
- 作者:老汪软件技巧
- 发表时间:2024-11-16 04:01
- 浏览量:
大数据处理和分析的领域,分布式计算框架(如 Hadoop)已经成为不可或缺的一部分。随着数据量的不断增加,传统的数据存储和处理方式逐渐暴露出性能瓶颈,如何高效处理大规模的数据,成为了技术人员亟待解决的问题。在这种背景下,Apache Hadoop 提供了一个高效且经济的分布式计算平台,特别适合处理 TB 甚至 PB 级别的数据。
本文将基于 Spring Boot 与 Hadoop 3.3.6 实现一个简单的 MapReduce 任务,结合实际项目场景进行应用,分析一个网站日志文件中的 IP 地址访问次数,从而展示如何将 Hadoop 与 Spring Boot 相结合,搭建一个日志分析平台。
一、背景与需求分析1.1 背景
现代网站和应用程序会生成大量的日志文件,这些日志文件中包含了每个用户的访问行为、请求信息、状态码等内容。通过分析这些日志数据,可以帮助我们实现:
因此,如何高效地分析海量日志数据成为了技术团队的一个重要任务。常见的日志分析工具有 ELK(Elasticsearch, Logstash, Kibana) 等,但如果需要自行搭建分析平台或在大数据环境下处理日志数据,Hadoop MapReduce 是一个非常适合的选择。
1.2 项目需求
在本项目中,我们将构建一个简单的日志分析平台,需求如下:
二、Hadoop 与 MapReduce 简介2.1 Hadoop 介绍
Apache Hadoop 是一个开源的分布式计算框架,主要用于处理大规模数据集。它包括以下几个核心组件:
Hadoop 的强大之处在于它的可扩展性和容错性,能够在普通硬件上运行,并能处理大量数据,适用于批处理和大规模数据分析场景。
2.2 MapReduce 编程模型
MapReduce 是 Hadoop 的核心计算模型。它将数据处理过程分为两个阶段:Map 阶段和 Reduce 阶段。
这一编程模型非常适合处理大规模数据,能够充分利用分布式计算资源进行并行处理。
三、项目结构与关键组件3.1 项目结构
项目的基本结构如下:
|-- src
| |-- main
| |-- java
| |-- com
| |-- example
| |-- loganalysis
| |-- LogAnalyzerMapper.java
| |-- LogAnalyzerReducer.java
| |-- LogAnalyzerService.java
| |-- LogAnalyzerController.java
| |-- resources
| |-- application.properties
| |-- log4j2.xml
|-- pom.xml
3.2 关键组件说明
package com.neo.controller;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogAnalyzerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text ipAddress = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split(" ");
if (tokens.length > 0) {
ipAddress.set(tokens[0]); // 提取 IP 地址
context.write(ipAddress, one);
}
}
}
package com.neo.controller;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogAnalyzerReducer extends Reducer {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
package com.neo.controller;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
@Service
public class LogAnalyzerService {
@Value("${hadoop.fs.defaultFS}")
private String hdfsUri;
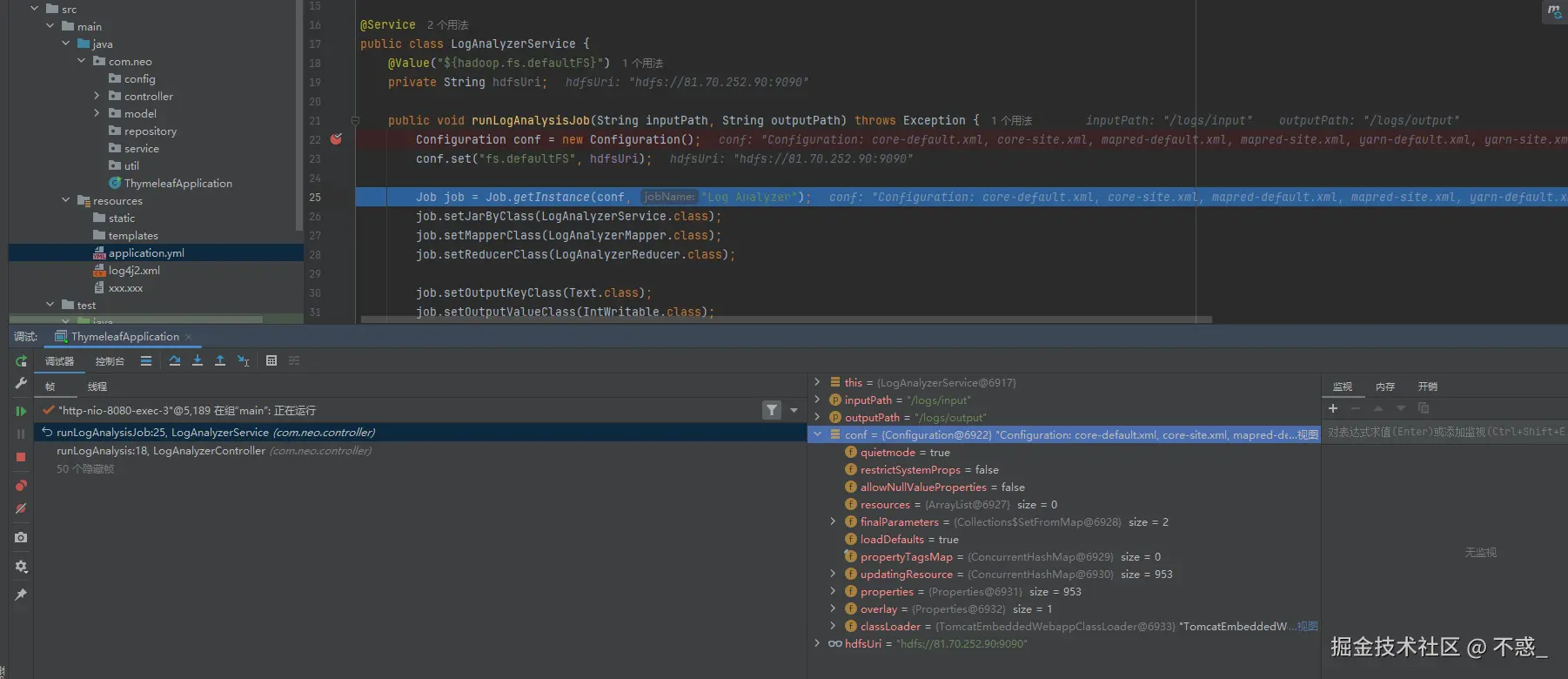
public void runLogAnalysisJob(String inputPath, String outputPath) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfsUri);
Job job = Job.getInstance(conf, "Log Analyzer");
job.setJarByClass(LogAnalyzerService.class);
job.setMapperClass(LogAnalyzerMapper.class);
job.setReducerClass(LogAnalyzerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
FileSystem fs = FileSystem.get(conf);
Path outputDir = new Path(outputPath);
if (fs.exists(outputDir)) {
fs.delete(outputDir, true); // 删除输出目录,防止报错
}
boolean success = job.waitForCompletion(true);
if (!success) {
throw new IOException("Log Analysis job failed");
}
}
}
package com.neo.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class LogAnalyzerController {
@Autowired
private LogAnalyzerService logAnalyzerService;
@GetMapping("/run-log-analysis")
public String runLogAnalysis(@RequestParam(required = false) String inputPath, @RequestParam(required = false) String outputPath) {
inputPath = "/logs/input";
outputPath = "/logs/output";
try {
logAnalyzerService.runLogAnalysisJob(inputPath, outputPath);
return "Log analysis job completed successfully!";
} catch (Exception e) {
return "Error running log analysis job: " + e.getMessage();
}
}
}
四、Spring Boot 与 Hadoop 集成4.1 配置 Hadoop 客户端
在 Spring Boot 项目的 application.properties 文件中,配置 Hadoop 的相关属性:
hadoop.fs.defaultFS=hdfs://localhost:9000
hadoop.mapreduce.framework.name=yarn
hadoop.yarn.resourcemanager.address=localhost:8032
hadoop.yarn.resourcemanager.scheduler.address=localhost:8030
这些配置指定了 Hadoop 的文件系统和 YARN 资源管理器的地址。
4.2 日志文件的存储与输入路径
假设日志文件存储在 Hadoop HDFS 的 /logs 目录下,你可以通过 FileInputFormat 类指定输入路径。
4.3 输出路径和结果
输出路径可以设置为 /user/logs/ip_count_output,在 MapReduce 作业执行完后,结果会存储在此目录下。
六、总结
通过 MapReduce 实现对网站访问日志的处理和分析。通过实际项目案例的展示,帮助读者理解如何在大数据环境中使用 Hadoop 进行批处理,结合 Spring Boot 搭建高效的微服务架构,处理和分析海量数据。
随着数据量的不断增长,分布式计算框架的应用将会越来越广泛。通过深入掌握 Hadoop 和 Spring Boot 的集成,开发者可以在实际项目中高效地处理大数据任务,并且在此基础上进行优化和扩展,实现更复杂的数据分析和处理需求。



