
- 作者:老汪软件技巧
- 发表时间:2024-11-16 04:01
- 浏览量:

随着 Elastic Cloud 提供可观察性、安全性和搜索等解决方案,我们将使用 Elastic Cloud 的用户范围从完整的运营团队扩大到包括数据工程师、安全团队和顾问。作为 Elastic 支持代表,我很乐意与各种各样的用户和用例互动。
随着受众的扩大,我看到了更多关于管理资源分配的问题,特别是对分配健康状况进行故障排除和避免断路器的问题。我明白了!当我开始使用 Elasticsearch 时,我也有同样的问题。这是我第一次接触管理 Java 堆和时间序列数据库分片以及扩展我自己的基础设施。
当我加入 Elastic 时,我喜欢除了文档之外,我们还有博客和教程,这样我就可以快速上手。但随后,我在第一个月努力将我的理论知识与用户通过我的票务队列发送的错误联系起来。最终,我和其他支持代表一样发现,很多报告的错误只是分配问题的症状,同样的七个链接将使用户快速掌握成功管理其资源分配的方法。
作为一名支持代表,我将介绍我们向用户发送的最重要的分配管理理论链接、我们看到的最重要的症状以及我们指导用户更新他们的配置以解决他们的资源分配问题的地方。
理论
作为 Java 应用程序,Elasticsearch 需要从系统的物理内存中分配一些逻辑内存(堆)。这应该最多是物理 RAM 的一半,。设置更高的堆使用率通常是为了昂贵的查询和更大的数据存储。父熔断器()默认为 95%,但我们建议在持续 后扩展资源。
我强烈推荐这些概述文章以获取更多信息:
配置
Elasticsearch 的会根据节点角色和总内存自动调整 JVM 堆的大小。但是,你可以根据需要通过以下三种方式直接配置它:
直接在本地 Elasticsearch 文件的 config > jvm.options 文件中进行配置:
1. ## JVM configuration
3. ################################################################
4. ## IMPORTANT: JVM heap size
5. ################################################################
7. …
9. # Xms represents the initial size of total heap space
10. # Xmx represents the maximum size of total heap space
12. -Xms4g
13. -Xmx4g
作为 中的 Elasticsearch 环境变量:
1. version: '2.2'
2. services:
3. es01:
4. image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0
5. environment:
6. - node.name=es01
7. - cluster.name=es
8. - bootstrap.memory_lock=true
9. - "ES_JAVA_OPTS=-Xms4g -Xmx4g"
10. - discovery.type=single-node
11. ulimits:
12. memlock:
13. soft: -1
14. hard: -1
15. ports:
16. - 9200:9200
通过我们的 Elastic Cloud Hosted > Deployment > Edit 视图。注意:下拉菜单分配物理内存,大约一半将分配给堆。
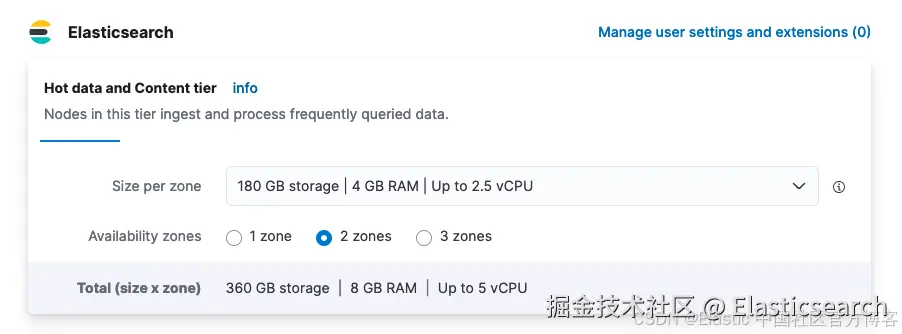
故障排除
如果你目前遇到集群性能问题,则最有可能归结为常见原因:
所有以下 cURL/API 请求都可以在 Elastic Cloud Hosted > Elasticsearch API 控制台中、作为 Elasticsearch API 的 cURL 或在 Kibana > Dev Tools 下进行。
分配健康状况
数据索引存储在子分片中,这些子分片在维护以及搜索/写入请求期间会使用堆内存。分片大小。
以上述拥有 8GB 物理内存的两区域 Elastic Cloud 托管示例为例(总共分配两个节点),我们可以用以下命令查看示例:[_cat/allocation]( "_cat/allocation")。
1. GET /_cat/allocation?v=true&h=shards,node
2. shards node
3. 41 instance-0000000001
4. 41 instance-0000000000
以及:_cluster/health。
1. GET /_cluster/health?filter_path=status,*_shards
3. {
4. "status": "green",
5. "unassigned_shards": 0,
6. "initializing_shards": 0,
7. "active_primary_shards": 41,
8. "relocating_shards": 0,
9. "active_shards": 82,
10. "delayed_unassigned_shards": 0
11. }

如果任何分片在 active_shards 或 active_primary_shards 之外的报告数>0,则你已确定了性能问题的原因。
如果报告问题,最常见的情况是 unassigned_shards > 0。如果这些分片是主分片,你的集群将报告为 status:red,如果只有副本,它将报告为 status:yellow。更多有关这些状态的描述请参考文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。(这就是为什么在索引上设置副本很重要的原因 —— 如果集群遇到问题,它可以恢复,而不是经历数据丢失。)让我们假设我们有一个带有单个未分配分片的 status:yellow。为了调查,我们将通过 _cat/shards查看哪个索引分片有问题。
1. GET _cat/shards?v=true&s=state
2. index shard prirep state docs store ip node
3. logs 0 p STARTED 2 10.1kb 10.42.255.40 instance-0000000001
4. logs 0 r UNASSIGNED
5. kibana_sample_data_logs 0 p STARTED 14074 10.6mb 10.42.255.40 instance-0000000001
6. .kibana_1 0 p STARTED 2261 3.8mb 10.42.255.40 instance-0000000001
因此,这将适用于我们的非系统索引日志,这些日志具有未分配的副本分片。让我们通过运行 _cluster/allocation/explain 来查看是什么让它陷入困境。(专业提示:当你升级到我们官方的技术支持时,这正是我们所做的。)
GET _cluster/allocation/explain?pretty&filter_path=index,node_allocation_decisions.node_name,node_allocation_decisions.deciders.*
1. { "index": "logs",
2. "node_allocation_decisions": [{
3. "node_name": "instance-0000000005",
4. "deciders": [{
5. "decider": "data_tier",
6. "decision": "NO",
7. "explanation": "node does not match any index setting [index.routing.allocation.include._tier] tier filters [data_hot]"
8. }]}]}
此错误消息指向 data_hot,它是索引生命周期管理 (index lifecycle management- ILM) 策略的一部分,表明我们的 ILM 策略与我们当前的索引设置不一致。在这种情况下,此错误的原因是设置了热温(hot-warm) ILM 策略而没有指定热温节点。(我需要保证某些事情会失败,所以这是我为大家强制提供的错误示例。有关更多信息,请参阅此示例故障排除视频以获取解决方案演练。)
如果你在没有任何未分配的分片时运行此命令,你将收到 400 错误,表示无法找到任何未分配的分片来解释,因为没有任何错误需要报告。如果你遇到非逻辑原因(例如,临时网络错误,如分配期间节点离开集群),那么你可以使用 Elastic 的方便的 _cluster/reroute。
POST /_cluster/reroute
此请求未经过自定义,将启动一个异步后台进程,尝试分配所有当前状态为:UNASSIGNED 的分片。(不要像我一样,不等它完成就联系开发人员,因为我以为它会立即发生,而且巧合的是,它会及时升级,让他们说没什么问题,因为什么都没有了。)有关更多信息,请参阅此故障排除视频,以监控分配健康状况。
熔断器 -Circuit breakers
堆分配达到最大值可能会导致对集群的请求超时或出错,并且经常会导致集群遇到熔断器异常。熔断器错误会导致 elasticsearch.log 事件,例如:
Caused by: org.elasticsearch.common.breaker.CircuitBreakingException: [parent] Data too large, data for [] would be [num/numGB], which is larger than the limit of [num/numGB], usages [request=0/0b, fielddata=num/numKB, in_flight_requests=num/numGB, accounting=num/numGB]
1. GET /_cat/nodes?v=true&h=name,node*,heap*
2. # heap = JVM (logical memory reserved for heap)
3. # ram = physical memory
5. name node.role heap.current heap.percent heap.max
6. tiebreaker-0000000002 mv 119.8mb 23 508mb
7. instance-0000000001 himrst 1.8gb 48 3.9gb
8. instance-0000000000 himrst 2.8gb 73 3.9gb
或者,如果你之前已启用它,请导航至 Kibana > Stack Monitoring。
如果你已确认自己正在触及内存熔断器,则需要考虑暂时增加堆,以便给自己留出调查的喘息空间。调查根本原因时,请查看集群代理日志或 elasticsearch.log 以查找前面的连续事件。你将寻找:
非优化映射请求量/速度:通常是批量或异步查询扩展时间
如果这不是你第一次遇到熔断器,或者你怀疑这将是一个持续存在的问题(例如,持续达到 85%,因此是时候考虑扩展资源了),你需要仔细查看 JVM 内存压力作为长期堆指标。你可以在 Elastic Cloud Hosted > Deployment 中检查这一点。
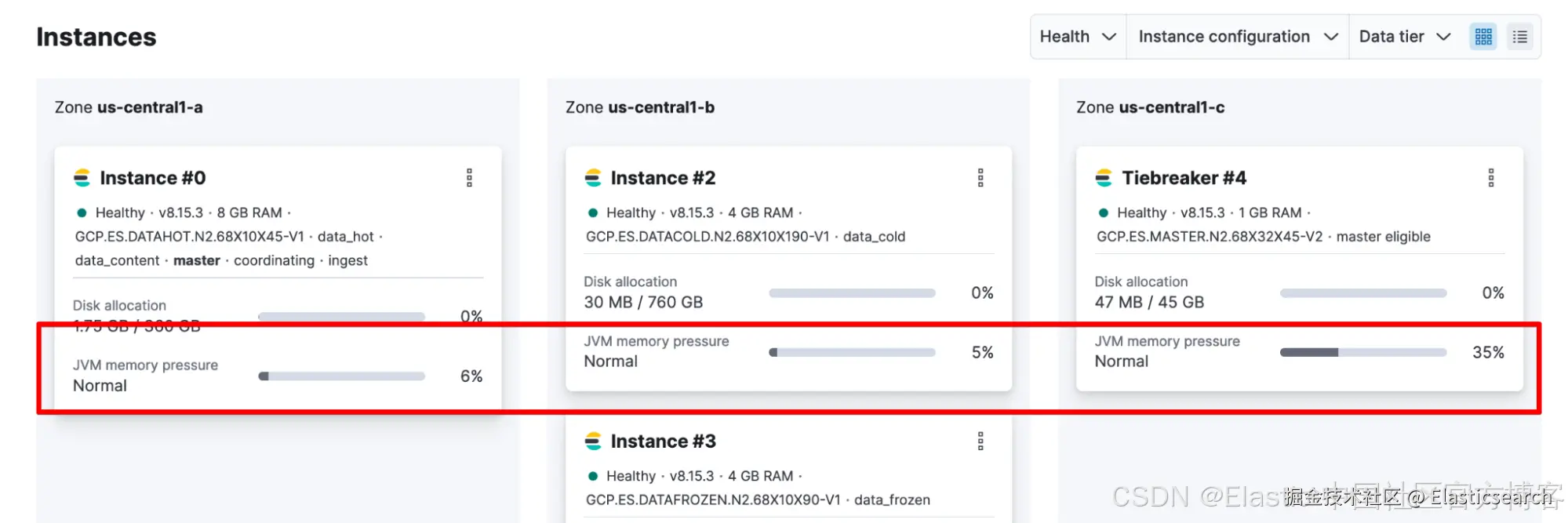
或者你可以从 _nodes/stats计算它:
1. GET /_nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
3. {"nodes": { "node_id": { "jvm": { "mem": { "pools": { "old": {
4. "max_in_bytes": 532676608,
5. "peak_max_in_bytes": 532676608,
6. "peak_used_in_bytes": 104465408,
7. "used_in_bytes": 104465408
8. }}}}}}}
在这里:
JVM Memory Pressure = used_in_bytes / max_in_bytes
这种情况的一个潜在症状是 elasticsearch.log 中的垃圾收集器 (gc) 事件出现频率高且持续时间长:
[timestamp_short_interval_from_last][INFO ][o.e.m.j.JvmGcMonitorService] [node_id] [gc][number] overhead, spent [21s] collecting in the last [40s]
如果你确认了这种情况,则需要考虑扩展集群或减少对集群的需求。你需要调查/考虑:
我们随时为你提供帮助
哇哦!从我在 Elastic 支持中看到的情况来看,这是最常见的用户工单的概要:未分配的分片、不平衡的分片堆、熔断器、高垃圾收集和分配错误。所有这些都是核心资源分配管理对话的症状。希望你现在也知道理论和解决步骤。
不过,此时,如果你在解决问题时遇到困难,请随时与我们联系。我们随时为你提供帮助!联系我们:
为我们能够以非 Ops(也喜欢 Ops)的身份自行管理 Elastic Stack 的资源分配的能力而欢呼!
原文:Managing and troubleshooting Elasticsearch memory | Elastic Blog



