- 作者:老汪软件技巧
- 发表时间:2024-01-08 18:00
- 浏览量:
此篇将所有代码都补充完了,之前发现有的代码写错了,以这篇为准,以下为完整代码,如果发现我有什么考虑不周的地方,可以评论提建议,感谢。代码是想哪写哪,可能比较繁琐,还需要优化。
import re
import os
import tkinter.filedialog
from tkinter import *
class Hive2Presto:
def __int__(self):
self.t_funcs = ['substr', 'nvl', 'substring', 'unix_timestamp'] + \
['to_date', 'concat', 'sum', 'avg', 'abs', 'year', 'month', 'ceiling', 'floor']
self.time_funcs = ['date_add', 'datediff', 'add_months', 'date_sub']
self.funcs = self.t_funcs + self.time_funcs
self.current_path = os.path.abspath(__file__)
self.dir = os.path.dirname(self.current_path)
self.result = []
self.error = []
self.filename = ''
def main(self):
self.root = Tk()
self.root.config(bg='#ff741d') # 背景颜色设置为公司主题色^_^
self.root.title('Hive转Presto')
self.win_width = 550
self.win_height = 500
self.screen_width = self.root.winfo_screenwidth()
self.screen_height = self.root.winfo_screenheight()
self.x = (self.screen_width - self.win_width) // 2
self.y = (self.screen_height - self.win_height) // 2
self.root.geometry(f'{self.win_width}x{self.win_height}+{self.x}+{self.y}')
font = ('楷体', 11)
self.button = Button(self.root, text='转换', command=self.trans, bg='#ffcc8c', font=font, anchor='e')
self.button.grid(row=0, column=0, padx=100, pady=10, sticky=W)
self.file_button = Button(self.root, text='选择文件', command=self.choose_file, bg='#ffcc8c', font=font,
anchor='e')
self.file_button.grid(row=0, column=1, padx=0, pady=10, sticky=W)
self.entry = Entry(self.root, width=65, font=font)
self.entry.insert(0, '输入Hive代码')
self.entry.grid(row=1, column=0, padx=10, pady=10, columnspan=2)
self.entry.bind('', self.delete_text)
self.text = Text(self.root, width=75, height=20)
self.text.grid(row=2, column=0, padx=10, pady=10, columnspan=2)
self.des_label = Label(self.root, text='可以复制结果,也有生成的文件,与选取的文件同文件夹', bg='#ffcc8c',
font=('楷体', 10))
self.des_label.grid(row=3, column=0, padx=10, pady=10, columnspan=2)
s = ''
for i in range(0, (n := len(self.funcs)), 4):
if i + 4 <= n:
s += ','.join(self.funcs[i:i + 4]) + '\n'
else:
s += ','.join(self.funcs[i:]) + '\n'
s = s[:-1]
self.des_label1 = Label(self.root, text=s, bg='#ffcc8c',
font=('楷体', 10))
self.des_label1.grid(row=4, column=0, padx=10, pady=10, columnspan=2)
self.root.columnconfigure(0, minsize=10)
self.root.columnconfigure(1, minsize=10)
self.root.columnconfigure(0, pad=5)
self.root.mainloop()
def replace_func(self, s, res):
"""
把搜索到函数整体取出来,处理括号中的参数
:param s:
:param res:
:return:
"""
for f in res:
f1 = f.replace('\n', '').strip()
f1 = re.sub(r'(\(s*)', '(', f1)
# 搜索括号里的字符串
if re.findall(r'(\w+)\(', f1):
func_name = re.findall(r'(\w+)\(', f1)[0].strip()
else:
continue
try:
if 'date_add' == func_name.lower():
date, date_num = self.extact_func(f1, func_name)
s_n = f"date_add('day',{date_num},cast(substr(cast{date} as varchar,1,10) as date))"
s = s.replace(f, s_n)
elif 'datediff' == func_name.lower():
date1, date2 = self.extact_func(f1, func_name)
s_n = f"date_add('day',{date2},cast(substr(cast{date1} as varchar,1,10) as date),cast(substr(cast{date1} as varchar),1,10) as date))"
s = s.replace(f, s_n)
elif 'nvl' == func_name.lower():
s1, s2 = self.extact_func(f1, func_name)
s_n = f"coalesce({s1},{s2})"
s = s.replace(f, s_n)
elif 'substr' == func_name.lower():
date, start, end = self.extact_func(f1, func_name)
s_n = f"substr(cast({date} as varchar),{start},{end}"
s = s.replace(f, s_n)
elif 'substring' == func_name.lower():
date, start, end = self.extact_func(f1, func_name)
s_n = f"substring(cast({date} as varchar),{start},{end}"
s = s.replace(f, s_n)
elif 'unit_timestamp' == func_name.lower():
date = self.extact_func(f1, func_name)[0]
s_n = f"to_unixtime(cast({date} as timestanp))"
s = s.replace(f, s_n)
elif 'to_date' == func_name.lower():
date = self.extact_func(f1, func_name)[0]
s_n = f"cast({date} as date)"
s = s.replace(f, s_n)
elif 'concat' == func_name.lower():
res = self.extact_func(f1, func_name)[0]
s_n = f'concat('
for r in res:
r = r.strip().replace('\n', '')
s_n += f"cast({r} as varchar),"
s_n = s_n[:-1] + ')'
s = s.replace(f, s_n)
elif 'sum' == func_name.lower():
if 'unix_timestamp' in f1 or 'to_unixtime' in f1:
continue
ss = self.extact_func(f1, func_name)[0]
if 'if(' in ss.replace(' ', ''):
continue
s = self.func_trans(f, f1, func_name, ss, s)
elif 'avg' == func_name.lower():
if 'unix_timestamp' in f1 or 'to_unixtime' in f1:
continue
ss = self.extact_func(f1, func_name)[0]
if 'if(' in ss.replace(' ', ''):
continue
s = self.func_trans(f, f1, func_name, ss, s)
elif 'abs' == func_name.lower():
if 'unix_timestamp' in f1 or 'to_unixtime' in f1:
continue
ss = self.extact_func(f1, func_name)[0]
if 'if(' in ss.replace(' ', ''):
continue
s = self.func_trans(f, f1, func_name, ss, s)
elif 'ceiling' == func_name.lower():
if 'unix_timestamp' in f1 or 'to_unixtime' in f1:
continue
ss = self.extact_func(f1, func_name)[0]
if 'if(' in ss.replace(' ', ''):
continue
s = self.func_trans(f, f1, func_name, ss, s)
elif 'floor' == func_name.lower():
if 'unix_timestamp' in f1 or 'to_unixtime' in f1:
continue
ss = self.extact_func(f1, func_name)[0]
if 'if(' in ss.replace(' ', ''):
continue
s = self.func_trans(f, f1, func_name, ss, s)
elif 'year' == func_name.lower():
date = self.extact_func(f1, func_name)[0]
s_n = f"year(cast(substr(cast({date} as varchar,1,10) as date))"
s = s.replace(f, s_n)
elif 'month' == func_name.lower():
date = self.extact_func(f1, func_name)[0]
s_n = f"month(cast(substr(cast({date} as varchar,1,10) as date))"
s = s.replace(f, s_n)
elif 'date_sub' == func_name.lower():
date, date_num = self.extact_func(f1, func_name)
s_n = f"date_add('day',-{date_num},cast(substr(cast{date} as varchar,1,10) as date))"
s = s.replace(f, s_n)
except:
self.error.append(f"源代码中{func_name}函数参数输入可能有错误,具体为:{f1}")
continue
if self.error:
self.entry.delete(0, END)
self.text.delete("1.0", END)
self.text.insert("end", f"{s}")
self.error.insert(0, '转换失败,有部分没有转成功\n')
root_ex = Tk()
root_ex.title('错误')
win_width = 600
win_height = 200
screen_width = root_ex.winfo_screenwidth()
screen_height = root_ex.winfo_screenheight()
x = (screen_width - win_width) // 2
y = (screen_height - win_height) // 2
root_ex.geometry(f'{win_width}x{win_height}+{x}+{y}')
label_ex = Label(root_ex, text="\n".join(self.error), font=("楷体", 10))
label_ex.pack()
root_ex.mainloop()
return s
def func_trans(self, f, f1, func_name, ss, s):
if not ('+' in ss or '-' in ss or '*' in ss or '/' in ss):
date = self.extact_func(f1, func_name)[0]
s_n = f'{func_name}(cast{date} as double))'
s = s.replace(f, s_n)
else:
res1 = self.mysplit(f1)
s_n = f
n = len(s_n)
for item in res1:
if any(c.isalpha() for c in item.replace(' ', '')):
idxs = s_n.find(item)
idxs = [idxs] if type(idxs) != list else idxs
for idx in idxs:
if idx + len(item) + 3 <= n:
if not 'as' in s_n[idx:idx + len(item) + 4]:
s_n = re.sub(rf'\b{item}\b', f'cast({item} as double)', s_n)
else:
s_n = re.sub(rf'\b{item}\b', f'cast({item} as double)', s_n)
s = s.replace(f, s_n)
return s
def choose_file(self):
"""
如果代码太多,从text中输入会很卡,直接选择代码文件输入会很快
:return:
"""
self.filename = tkinter.filedialog.askopenfilename()
if '/' in self.filename:
self.filename = self.filename.replace('/', '\\')
self.entry.delete(0, END)
self.entry.insert(0, self.filename)
def findvar(self, ss):
"""
搜索与计算有关的字段
:param ss:
:return:
"""
global r1
b = ['+', '-', '*', '/', '=', '!=', '>', '<', '<=', '>=', '<>']
result1 = []
result2 = []
result1_n = []
result2_n = []
res_ops = []
res1_ops = []
res_adj = []
res1_adj = []
for op in b:
s_temp1 = ss.replace('\n', ' ')
s_temp2 = ss.replace('\n', ' ')
s_temp3 = ss.replace('\n', ' ')
if op == '/' or op == '=':
op = op
elif op == '+' or op == '-' or op == '*' or op == '>' or op == '<':
op = f'\\{op[0]}'
else:
op = f'\\{op[0]}\\{op[1]}'
parttern = f'\s*-*\d+\s*{op}\s*\w+|' + f'\s*-*\d+\.\s*{op}\s*\w+\.\s*\w+|' \
+ f'\s*\w+\.\s*\w+\s*{op}\s*\w+\.\s*\w+|' + f'\s*\w+\s*{op}\s*\w+\.\s*\w+|' \
+ f'\s*\w+\.\s*\w+\s*{op}\s*\w+|' + f'\s*\w+\s*{op}\s*\w+'
parttern1 = f'\s*\)+\s*{op}\s*\w+|' + f'\s*\)+\s*{op}\s*\w+\.\s*\w+|' \
+ f'\s*\w+\s*{op}\s*\(+|' + f'f\s*\w+\.\s*{op}\s*\(+'
parttern2 = f'\s*\w+\s*{op}\s*\w+|' + f'\s*\w+\s*{op}\s*\w+\.\s*\w+|' \
+ f'\s*\w+\s*{op}\s*\w+|' + f'f\s*\w+\.\s*{op}\s*\w+'
while True:
res = re.findall(parttern, s_temp1)
if not res:
break
result2.extend(res)
for r in res:
r1 = r.replace(' ', '').split(f'op')
result1.append(r1)
res_ops.append(f'{op}')
res_adj.append(False)
s_temp1 = s_temp1.replace(f'{r1[0]}', '')
# 搜索带括号的计算
if op == '+' or op == '-' or op == '*' or op == '/':
while True:
res = re.findall(parttern1, s_temp2)
if not res:
break
result2.extend(res)
for r in res:
r1 = r.replace(' ', '').split(f'{op}')
result1.append(r1)
res_ops.append(f'{op}')
res_adj.append(False)
tem = r1[0] if r1[0].strip() not in ['(', ')'] else r1[1]
s_temp2 = s_temp2.replace(f'{tem}', '')
else:
res = re.findall(parttern2, s_temp3)
result2.extend(res)
for r in res:
r1 = r.replace(' ', '').split(f'{op}')
result1.append(r1)
res_ops.append(f'{op}')
res_adj.append(True)
str_ = re.findall(r'\'([^\']*)\'', ss)
str_ = list(set(str_))
str_ = [v.rstrip(' \n') for v in str_]
for i, fun in enumerate(result1):
flag = 0
for item in fun:
if any(item.strip() in v for v in str_) or any(item.strip() == v for v in self.t_funcs):
break
flag += 1
if flag == 2 and result1[i] not in result1_n:
result1_n.append(result1[i])
result2_n.append(result2[i])
res1_ops.append(res_ops[i])
adj = result1[i][0] in self.time_funcs or result1[i][0] in self.time_funcs
res1_adj.append(adj)
if result1_n:
z = zip(result1_n, result2_n, res1_ops, res1_adj)
z1 = sorted(z, key=lambda x: len(x[1].replace(' ', '')), reverse=True)
result1_n, result2_n, res1_ops, res1_adj = zip(*z1)
return result1_n, result2_n, res1_ops, res1_adj
def mysplit(self, s):
"""
分割字段
:param s:
:return:
"""
s = s.strip().replace(')', '').replace('(', '')
b = ['+', '-', '*', '/']
res = [s]
result = []
for op in b:
n_res = []
for item in res:
n_res.extend(item.split(op))
res = n_res
for item in res:
if ' as ' not in item:
result.append(re.findall(r'^[\w+_*]+$', item.replace(' ', ''))[0])
result = list(set(res))
return result
def extact_func(self, s, func_name):
res = []
s = s[:-1].replace(f'{func_name}(', '', 1)
com_idx = [i for i, v in enumerate(s) if v == ',']
jd_com_idx = []
for i in com_idx:
s1 = s[0:i]
if s1.count('(') == s1.count(')'):
jd_com_idx.append(i)
jd_com_idx.append(len(s))
jd_com_idx.insert(0, -1)
for i in range(1, len(jd_com_idx)):
res.append(s[jd_com_idx[i - 1] + 1:jd_com_idx[i]])
return res
def sort_funcs(self, li):
li = sorted(li, key=lambda x: x.count('('), reverse=True)
li_n = []
for l in li:
li_n.append(l)
return li_n
def delete_text(self, event):
self.entry.delete(0, END)
self.filename = ''
def trans(self):
if self.filename:
data = open(self.filename, 'r', encoding='utf-8').readlines()
self.folder_path = os.path.dirname(self.filename)
file_res = self.folder_path + r'\hive转presto_res.sql'
os.startfile(f'{self.folder_path}')
else:
data = self.entry.get().split('\n')
file_res = self.dir + r'\hive转presto_res.sql'
data_n = []
for s in data:
if not s.rstrip(' \n'):
continue
if '”' in s:
s = s.replace('“', '')
if ',' in s:
s = s.replace(',', ',')
if '(' in s:
s = s.replace('(', '(')
if ')' in s:
s = s.replace(')', ')')
if (idx := s.find('--')) == -1:
data_n.append(s + '\n')
else:
data_n.append(s[:idx] + '\n')
data = ''.join(data_n)
res1, res2, ops, adj = self.findvar(data)
for i, ss in enumerate(res1):
s_n = res2[i]
s_n1 = res2[i]
s_n2 = res2[i]
s_t = res2[i]
flag = 0
for elem in ss:
elem1 = elem.replace(' ', '')
if any(c.isalpha() for c in elem1):
if ops[i] in ['=', '!=', '>', '<', '<=', '>=', '<>']:
if adj[i]:
if elem1 not in self.time_funcs:
s_n = re.sub(rf'\b{elem}\b', f'cast(substr({elem1},1,10) as date', s_n)
continue
else:
continue
if any(op in s_t for op in ['+', '-', '*', '/']):
s_n = re.sub(rf'\b{elem}\b', f'cast({elem1} as double)', s_n)
else:
s_n = re.sub(rf'\b{elem}\b', f'cast({elem1} as varchar)', s_n)
else:
if elem.strip() not in ['(', ')']:
s_n = re.sub(rf'\b{elem}\b', f'cast({elem1} as double)', s_n)
flag += 1
data = data.replace(res2[i].strip(), s_n)
if flag == 2:
if any(op in s_t for op in ['+', '-', '*', '/']):
s_n1 = re.sub(rf'\b{ss[0]}\b', f'cast({ss[0]} as double)', s_n)
s_n2 = re.sub(rf'\b{ss[1]}\b', f'cast({ss[1]} as double)', s_n)
else:
s_n1 = re.sub(rf'\b{ss[0]}\b', f'cast({ss[0]} as varchar)', s_n)
s_n2 = re.sub(rf'\b{ss[1]}\b', f'cast({ss[1]} as varchar)', s_n)
data = data.replace(s_n1, s_n)
data = data.replace(s_n2, s_n)
self.error = []
self.result = []
for func_name in self.funcs:
r = [m.start() for m in re.finditer(func_name, data.lower())]
for idx in r:
n = 1
while True:
s = data[idx:idx + n]
if (s.count(')') == s.count('(') and s.count(')') != 0) and idx + n > len(data):
break
n += 1
if s not in self.result and s.rstrip(' \n')[len(func_name)] == '(':
self.result.append(s)
self.result = self.sort_funcs(self.result)
res = self.replace_func(data, self.result)
res_new = []
for r in res.split('\n'):
if r.rstrip(' \n'):
res_new.append(r)
res_new = '\n'.join(res_new)
self.text.delete("1.0", END)
self.text.insert("end", f'{res_new}')
with open(file_res, 'w', encoding='utf-8') as f:
f.write(res_new)
if __name__ == '__main__':
pro = Hive2Presto()
pro.__int__()
pro.main()
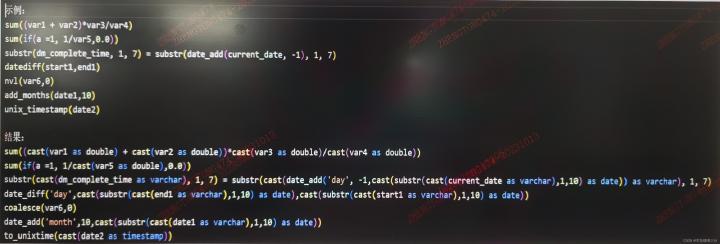
效果如下所示: