
- 作者:老汪软件技巧
- 发表时间:2024-01-08 18:00
- 浏览量:
1 core文件的配置
默认情况下,如果程序崩溃了是不会生成core文件的,因为生成core文件受到系统配置的影响。
-c是core文件的大小,默认为0,因此,就不会生成core文件,因此,为了能够生成core文件,可以使用 -c 命令使得程序在崩溃时能够生成core文件。
默认情况下,会在崩溃的程序所在的路径下生成core文件,当然也可以通过修改/proc/sys//core-将core文件放到某个路径下。
2 gdb查看堆栈
当有了core文件后,就可以用gdb查看core文件,得到core的堆栈信息。
gdb binary core.11111
就是执行时崩溃的二进制程序,core.11111就是崩溃时产生的core文件。
然后执行bt命令就可以查看程序崩溃时的堆栈,并定位到具体崩溃的业务代码。
3 &
在使用gdb进行调试时,通常需要使用断点,即,在使用gdb运行程序时,可以执行以下命令增加断点:
b func_name
然后使用info b就可以查看断点信息,注意,如果程序需要加载其他的so,此时还拿不到so中的符号信息,gdb会提示:Make on load?
使用可以让程序运行到某个地方暂停,然后查看此时的变量或者内存的情况,但是,有时候,某个变量由于某个bug导致变成了非预期的值,就可以使用对变量进行监控,当变量的值变化时程序就会暂停。
如果需要对变量进行监控,那gdb肯定是需要有该变量的信息,监控变量相当于监控某块内存空间,是需要程序启动才能添加的,可以在程序最开始打,当程序暂停时再打:
w variable_name
3.1
通过break命令添加断点时,有三种方式可以指定断点所在的地方:
除了常规的断点,还有两种特殊的断点:
临时断点和条件断点的结合:
比如某个采集进程信息的程序,需要在程序启动后,查看某个特定的进程,那么,可以先用让程序在比较靠前的位置停止,当程序停止时,再执行用例,然后用条件断点,让程序在收到该进程信息时停止。
4 debug vs
debug和是程序发布的两种模式,两者的主要区别是:
当使用gdb进行调试时,如果不加-g的话,程序就不带调试信息,例如,变量的名称和文件名,那么在用gdb进行调试时,就无法通过函数或者变量名添加断点,因此,在使用gdb进行调试之前编译选项需要加上-g。
5 的使用
是提供的一款可以上报文件的工具,客户端程序可以集成该库,在程序core时,获取当前堆栈信息,可以用于在不方便登录到这些环境只能远程分析的场景。
5.1 升级gcc 5.2 的简单使用
git clone https://github.com/google/breakpad.git
cd breakpad
git clone https://github.com/getsentry/linux-syscall-support.git src/third_party/lss
然后在目录执行./&&make进行编译,然后在src目录下编写以下程序:
#include "client/linux/handler/exception_handler.h"
static bool dumpCallback(const google_breakpad::MinidumpDescriptor& descriptor, void*context, bool succeeded) {
printf("Dump path: %s\n", descriptor.path());
return succeeded;
}
void crash() {
volatile int* a = (int*)NULL;
*a = 1;
}
int main() {
google_breakpad::MinidumpDescriptor descriptor("/tmp");
google_breakpad::ExceptionHandler eh(descriptor, NULL, dumpCallback, NULL, true, -1);
crash();
return 0;
}
执行以下命令进行编译:
cp client/linux/libbreakpad_client.a /usr/local/lib
g++ test.c -o test -lbreakpad_client -I./
然后执行./test就可以在/tmp目录下生成dump文件,那么在实际中如何使用呢?
5.3 的实际使用
这里又要提到上面的debug和:debug是开发和功能测试过程中用的构建模式,编译时会带上-g选项,使用默认的优化级别_O0,是性能测试和实际发布的构建模式,编译时会去掉-g选项,并使用高优化级别,例如-O2,同时,为了反逆向,还会对二进制进行加壳操作,提高外部对二进制分析的门槛。
# 生成debug程序
g++ test.c -g -o test.debug -lbreakpad_client -I./
# 生成release程序
g++ test.c -O2 -o test.release -lbreakpad_client -I./
下面要用到(位于/src/tools/linux//),该工具可以将二进制的符号导出来用于后续分析。
./tools/linux/dump_syms/dump_syms test.release > test.sym
当程序使用模式进行编译后,还需要对二进制进行strip去掉里面的符号,一方面可以减小二进制的大小,另一方面当然也是防止程序被逆向。
以上面的程序为例,对生成的二进制进行strip:
strip -o test.user test.release
会发现,进行strip前,test.二进制大小为1.6M,进行strip后,test.user二进制大小为107K。
现在为止,我们就有两个文件:其中test.user是不带调试信息并且去掉符号信息的二进制,在进行一些加密的操作后就可以给用户使用,另一个是test.sym符号文件,可以用于后续分析。
下一步就是执行test.user,此时会在/tmp目录下生成dmp文件,下面对该文件进行分析,假设生成的dump文件路径为:/tmp/-2bdd-4460--.dmp。
先使用工具将dump文件和符号文件进行展开:
./processor/minidump_stackwalk /tmp/d5f4ae04-2bdd-4460-a63bff89-0790bde8.dmp ./test.sym > dump.result
查看dump.文件,然后使用得到地址所在的程序的地方:
addr2line -f -C -e test.debug 0x405f
但是会发现,在版本的情况下,由于加了优化级别,通过地址查不到具体导致crash的代码行,而用debug版本的情况下,是可以定位到具体报错的行。
6 定位容器中的core
如果在宿主机上用gdb定位容器中产生的core文件,会出现找不到so的问题,比如:
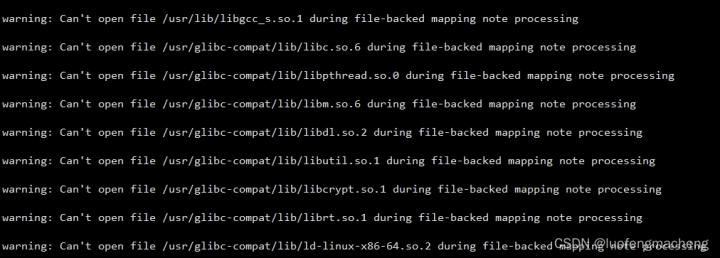
一方面,可能宿主机本地确实没有这些so,另一方方面,容器中使用的so跟宿主机的也可能不同。
gdb下面的提示也给出了解决办法:
将命令放到~/.中:
set sysroot /root/gdb_root
将容器中对应路径的so拷贝到/root/中,例如,当缺少/usr/lib/.so.1时,就将容器中的/usr/lib/.so.1放到宿主机的/root//usr/lib/.so.1,然后用gdb开启调试,此时就可以读取到对应的so,但是这种方式就需要将依赖的so都下载放到这里。
而另一个命令,set solib--path则适合用于会通过路径去查找so的场景,如果有时候就是查找特定路径的so,则该命令没啥用。



