
- 作者:老汪软件技巧
- 发表时间:2024-11-21 15:03
- 浏览量:
本文内容较为详尽,涵盖了自动图像特征提取的原理、应用场景及可操作的完整代码。文章较长,建议大家耐心阅读,同时文中提供的代码均经过测试,可直接复制运行!
自动图像描述生成技术是人工智能的一项重要能力,它让 AI 能够通过“看图”,生成一段自然语言的描述。这种技术不仅是炫技,还能在辅助残障人士、智能监控、社交内容创作等领域发挥巨大作用。比如,当你上传一张图片到社交媒体时,AI 能自动帮你生成一段精彩的描述,让你的分享更有趣。
在本文中,我们将用通俗易懂的方式来拆解:AI是如何通过图像生成文字的。你不需要是技术专家,也能明白背后的关键逻辑!
一、技术背景与意义什么是自动图像描述生成?
自动图像描述生成是一项结合计算机视觉(Computer Vision)和自然语言处理(Natural Language Processing)的跨学科技术,致力于让 AI 从图片中提取语义信息,并生成自然语言描述。
例如,给定一张包含人和自行车的图片,AI 会生成如下描述:
“一个人在骑自行车穿过城市街道。”
这项技术的关键在于:
图像理解:AI 需要从图片中识别出物体、场景和动作。
语言生成:AI 需要基于图像内容,用人类习惯的语言组织出描述。
技术的核心问题
语义鸿沟:图像是二维空间信息,而语言是时间序列信息,如何将这两种模态连接起来?
多样性与准确性:生成的描述既要准确传达图片内容,又要富有语言表达的多样性。
技术的意义
辅助功能:帮助视障人士通过语音了解图片内容。想象一下,如果一个视障人士拍下一张照片,AI 可以通过语音告诉他:“照片里是一只小狗在草地上奔跑。”这无疑会让生活变得更加便利。
智能监控:实时生成场景描述,用于识别异常行为。在安全监控场景中,AI 可以为视频中的场景生成实时描述,比如“有一辆红色汽车在逆行”。
图像搜索引擎:在搜索引擎中,图像描述可以为每张图片添加“标签”,让图片更容易被找到。例如,搜索“猫在睡觉”时,系统可以找到有类似描述的图片。
内容创作:为图片或视频生成高质量的配文,提升创作效率。不擅长写文字的人,可以用 AI 来帮忙。例如,你上传一张日落的照片,AI帮你生成一段诗意的描述:“金色的夕阳映衬在平静的湖面上,仿佛一幅画。”
二、AI是如何实现“看图说话”的?
实现图像描述生成的过程主要分为两步:
看图:提取图片的核心内容
AI 通过“卷积神经网络”(CNN)分析图片,提取出其中的关键信息(如物体的形状、颜色和位置)。CNN 是模仿人类视觉系统设计的,能够识别图片中的不同部分。
举例:
AI看到一张图片,会提取到以下信息:
说话:将信息转化为自然语言描述
AI 利用语言模型将这些图像信息转化为文字,比如:“一只狗在草地上奔跑”。这里使用的模型通常是“循环神经网络”(RNN)或更先进的“Transformer”。
举例:
RNN 会按照以下步骤生成句子:
三、AI “看图说话” 的内部逻辑
实现自动图像描述生成通常涉及两个核心模块:视觉编码模块(图像特征提取)和语言解码模块(描述生成)。现代主流方法包括**CNN-RNN 架构和基于Transformer 的架构**。
视觉编码模块:图像特征提取
常用模型:
流程图:
[输入图像] --> [卷积神经网络 (CNN)] --> [图像特征向量]
语言解码模块:文本描述生成
常用技术:
流程图:
[图像特征向量] --> [语言生成模块] --> [输出描述]
四、AI生成描述时的难点
虽然 AI 已经很强大,但它的“看图说话”能力也有一些挑战:
描述的准确性: 有时候 AI 会看错,比如把“猫”看成“狗”,生成的描述就会完全出错。语义的丰富性: AI 生成的描述有时过于简单,比如一张山水照片,AI 可能只会说:“山和水。”但人类会用更丰富的语言,比如“高耸的群山环绕着碧绿的湖泊”。多样性: 同一张照片,AI 生成的描述可能会千篇一律,而人类会用不同风格的表达方式,比如“温馨的家庭聚会” vs “一家人其乐融融地在客厅合影”。五、技术实现:核心架构与工作原理
我们以经典的 CNN-RNN 模型为例,逐步解析如何实现图像描述生成。
数据准备
使用公开数据集(如 MS COCO 或 Flickr30k)作为训练数据:
模型构建
视觉编码器(CNN 部分)
输入图片,提取高维特征向量。
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.image import img_to_array
import numpy as np
from PIL import Image
import requests
from io import BytesIO
# 加载预训练的 ResNet50 模型
print("加载 ResNet50 模型(预训练权重:ImageNet)...")
base_model = ResNet50(weights='imagenet')
# 修改模型输出为倒数第二层,提取特征
model = Model(inputs=base_model.input, outputs=base_model.layers[-2].output)
print("模型加载完成,输出层为倒数第二层。")
# 定义特征提取函数
def extract_features_from_url(image_url):
try:
print(f"\n开始处理网络图片:{image_url}")
# 下载网络图片
print("下载图片数据...")
response = requests.get(image_url)
response.raise_for_status() # 确保请求成功
# 将图片数据加载到 PIL 中
print("加载图片并调整大小为 224x224...")
image = Image.open(BytesIO(response.content)).convert("RGB")
image = image.resize((224, 224)) # 调整图片大小
print("图片加载完成!")
# 转换图片为数组
print("将图片转换为 NumPy 数组...")
image_array = img_to_array(image)
print(f"图片数组形状:{image_array.shape} (高, 宽, 通道)")
# 添加批量维度(模型需要 4D 输入)
print("添加批量维度...")
image_array = np.expand_dims(image_array, axis=0)
print(f"扩展后的数组形状:{image_array.shape} (批量, 高, 宽, 通道)")
# 归一化数组(像素值缩放到 [0, 1])
print("对图片像素值进行归一化处理...")
image_array = image_array / 255.0
# 使用模型提取特征
print("使用模型提取图像特征...")
features = model.predict(image_array)
print(f"提取的特征向量形状:{features.shape} (批量, 特征维度)")
print("特征提取完成!\n")
return features
except requests.exceptions.RequestException as e:
print(f"网络请求失败:{e}")
except Exception as e:
print(f"图片处理失败:{e}")
# 示例运行
image_url = "https://i.ytimg.com/vi/ea-NJT7JVUw/maxresdefault.jpg" # 替换为网络图片链接
features = extract_features_from_url(image_url)
# 打印特征向量的前几个值,便于观察
if features is not None:
print("提取的特征向量(前 10 个值):")
print(features[0][:10])

执行结果:
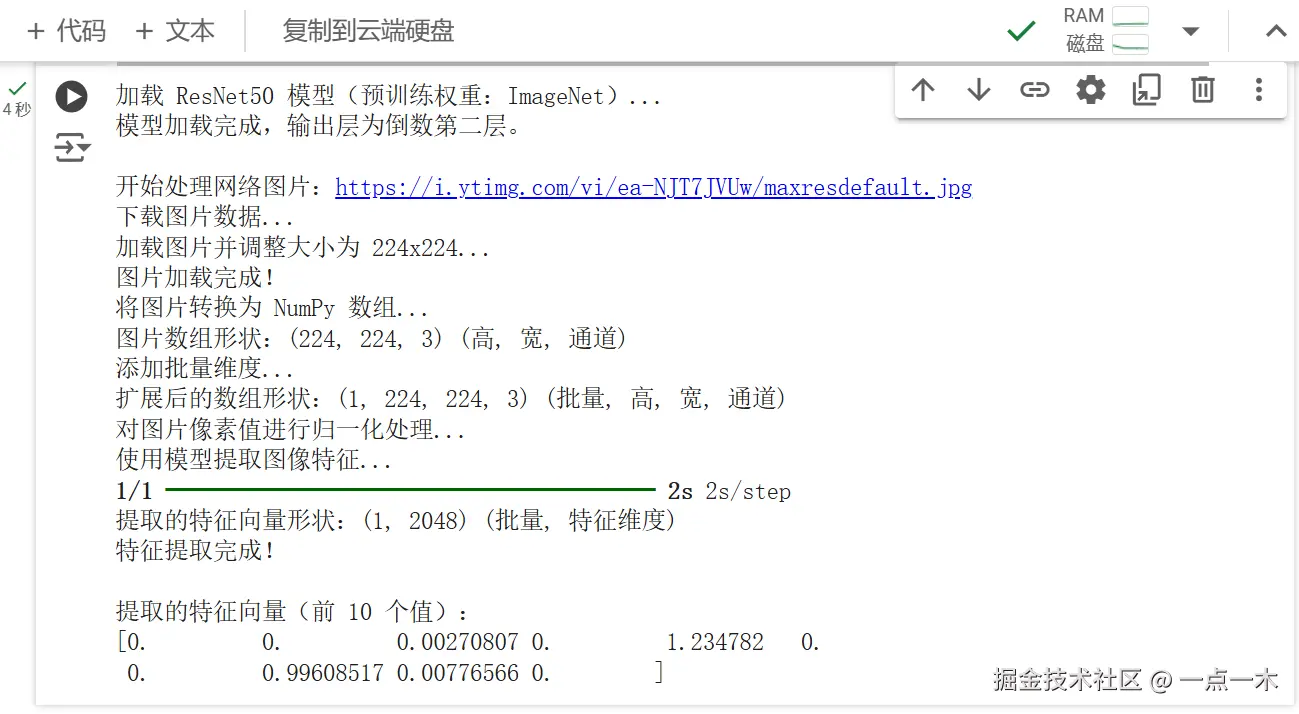
特征向量是深度学习模型(如 ResNet50)从图片中提取的高维数值表示。这些向量捕捉了图片的核心特征,如物体的形状、纹理、颜色,以及更高层次的语义信息。虽然特征向量本身没有直观的物理意义,但它们是模型理解图片内容的基础,广泛应用于图像分类、目标检测、图像检索等任务。
如果您想深入了解特征向量的概念和应用,可以参考相关资料,网络上有许多优秀的教程和文章。
语言解码器(RNN 部分)
使用 LSTM 生成描述。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
import numpy as np
# 构建语言生成模型
def build_decoder(vocab_size, embedding_dim, input_length=None):
print("开始构建语言生成模型...")
model = Sequential([
# Embedding 层:将词汇索引映射到密集向量空间
Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=input_length, name="Embedding_Layer"),
# 第一层 LSTM:输出所有时间步的隐藏状态
LSTM(512, return_sequences=True, name="LSTM_Layer_1"),
# 第二层 LSTM:仅输出最后一个时间步的隐藏状态
LSTM(512, name="LSTM_Layer_2"),
# Dense 层:输出词汇表大小的概率分布
Dense(vocab_size, activation='softmax', name="Dense_Output_Layer")
])
print("语言生成模型构建完成!")
return model
# 参数定义
vocab_size = 5000
embedding_dim = 256
input_length = 10
# 构建模型
decoder = build_decoder(vocab_size, embedding_dim, input_length)
# 打印模型结构
print("\n模型结构信息:")
decoder.summary()
# 模拟输入数据
dummy_input = np.random.randint(0, vocab_size, size=(2, input_length)) # 批量大小为 2,序列长度为 10
print("\n示例输入数据(词汇索引):")
print(dummy_input)
# 获取模型输出
dummy_output = decoder(dummy_input)
print("\n模型输出形状:", dummy_output.shape)
# 打印模型输出数据(部分)
print("\n模型输出示例(第一个样本的前 10 个词汇概率):")
print(dummy_output[0, :10])
执行结果:
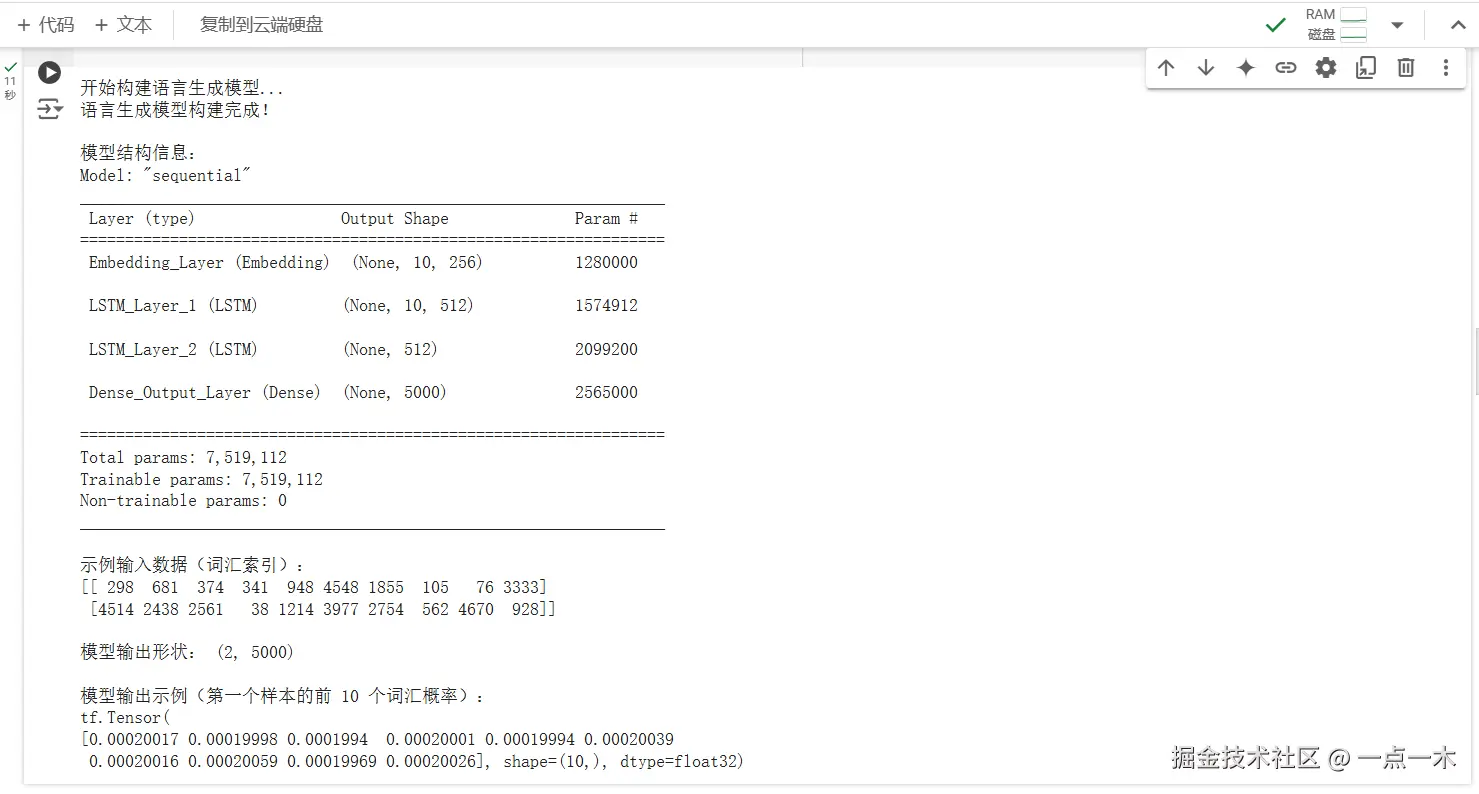
输出的数据是词汇概率分布
模型的输出 dummy_output 是一个三维张量,形状为 (batch_size, vocab_size),即:
对于每个输入序列,模型会为每个时间步预测下一个单词的概率分布,输出的每个值表示对应词汇的概率。
模型训练
使用图片和对应的描述数据,训练 CNN-RNN 模型。
损失函数:交叉熵,用于衡量生成描述与真实描述的差异。
优化方法:Adam 优化器。
结果展示
输入一张图片,运行训练好的模型,生成对应的描述。
六、用简单代码试试 AI “看图说话”
即使你没有编程经验,也可以用简单的工具尝试让 AI 看图并生成描述。以下是一个简单示例:
import requests
from PIL import Image
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
from io import BytesIO
print("加载预训练模型...")
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
def generate_caption_from_url(image_url):
try:
response = requests.get(image_url)
response.raise_for_status(
print("加载图片数据...")
image = Image.open(BytesIO(response.content)).convert("RGB")
print("提取图像特征...")
pixel_values = feature_extractor(images=[image], return_tensors="pt").pixel_values
print("生成描述...")
output_ids = model.generate(pixel_values)
caption = tokenizer.decode(output_ids[0], skip_special_tokens=True)
return caption
except requests.exceptions.RequestException as e:
print(f"网络请求失败:{e}")
except Exception as e:
print(f"图片处理失败:{e}")
image_url = "https://i.ytimg.com/vi/ea-NJT7JVUw/maxresdefault.jpg" # 替换为实际的网络图片链接
print(f"正在处理图片:{image_url}")
caption = generate_caption_from_url(image_url)
print(f"生成的描述:{caption}")
输入的图片为:

这个代码会让 AI 读取你提供的图片(maxresdefault.jpg),然后生成一句描述。
生成的描述:a cat is sitting on a tree branch
七、技术优势与挑战技术优势高效性:自动完成图片到文字的转换,节省人力。多场景适用:从医疗到娱乐,应用场景广泛。易扩展性:结合其他 AI 技术(如语音合成),可以提供完整的解决方案。技术挑战准确性:模型对复杂场景的理解可能不够准确。生成多样性:生成的描述往往较为单一。数据依赖性:训练需要大规模标注数据集。八、未来展望个性化描述:让 AI 生成符合用户风格的个性化描述,例如幽默风、简洁风。实时处理:提升模型推理速度,支持动态视频的实时场景描述。少样本学习:减少对大规模标注数据的依赖,让模型在小样本条件下也能表现出色。总结
自动图像描述生成技术让 AI 具备了“看图说话”的能力,展示了人工智能在多模态学习中的潜力。通过本文的详细解析,你不仅了解了技术的原理和实现方式,还能看到它在实际生活中的巨大潜力。未来,这项技术将进一步推动内容创作、辅助工具和人机交互的进步。
想法讨论:



