
- 作者:老汪软件技巧
- 发表时间:2024-11-21 15:03
- 浏览量:
1.过滤器
HBase过滤器(Filter)提供了非常强大的特性来帮助用户提高其处理表中数据的效率。用户不仅可以使用HBase中预定义好的过滤器,而且可以实现自定义的过滤器。
HBase中两种主要的数据读取函数是get()和scan(),他们都支持直接访问数据和通过指定起止行键,添加更多限制条件访问数据的功能。但是他们缺少一些细粒度的筛选功能,比如说基于正则表达式对行键或值进行筛选。Get和Scan两个类都支持过滤器。通过过滤器可以对行键,列名或列值进行过滤。过滤器最基本的接口叫Filter,除此之外,还有一些由HBase提供的无需编程就可以直接使用的类。
同时用户还可以通过继承Filter类来实现自己的需求。所有的过滤器都在服务端生效,叫做谓词下推(predicate push down)。这样可以保证被过滤掉的数据不会被传送到客户端。用户可以在客户端代码中实现过滤的功能(但会影响性能),因为这种情况下,服务器需要传输更多的数据到客户端,用户应当尽量避免这种情况。
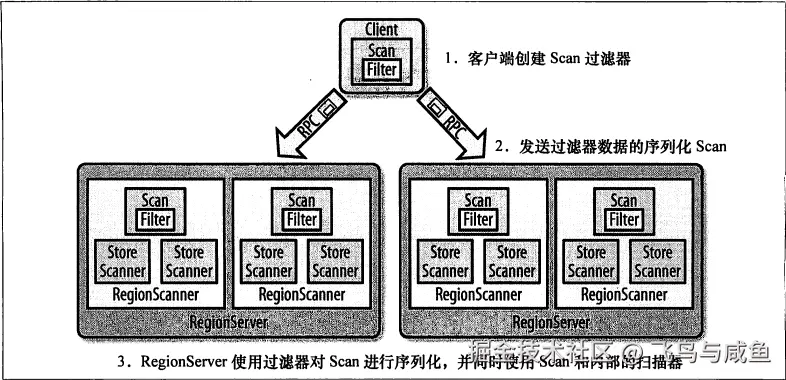
1.1.过滤器的层次结构
在过滤器层次结构的最底层是Filter接口和FilterBase抽象类,它们实现了过滤器的空壳和骨架,这使得实际的过滤器类可以避免许多重复的结构代码。
大部分实体过滤器类一般都是直接继承自FilterBase,也有一些间接继承自该类。他们使用流程相同,用户定义一个所需要的过滤器实例,同时把定义好的过滤器实例传递给Get或Scan实例:
setFilter(filter)
在实例化过滤器的时候,用户需要提供一些参数来设定过滤器的用途。其中有一组特殊的过滤器,他们继承自CompareFilter,需要用户同时提供至少两个特定参数,这两个参数会被基类用于执行它的任务。
1.2.比较运算符
因为继承自CompareFilter的过滤器比基类FilterBase多了一个compare()方法,它需要使用传入参数定义比较操作的过程。
CompareFilter中的比较运算符
LESS 匹配小于设定值的值
LESS_OR_EQUAL 匹配小于或等于设定值的值
EQUAL 匹配等于设定值的值
NOT_EQUAL 匹配与设定值不相等的值
GREATER_OR_EQUAL 匹配大于或等于设定值的值
GREATER 匹配大于设定值的值
NO_OP 排除一切值
1.3.比较器
CompareFilter所需要的第二类类型是比较器(comparator),比较器提供了多种方法来比较不同的键值。比较器都继承自Writable和Comparable接口。如果只使用HBase原生提供的比较器实现则可以不必过度关注细节,HBase提供的比较器罗列于下表,这些比较器构造时通常只需要提供一个阈值,这个值将会与表中的实际值进行比较。
HBase对基于CompareFilter的过滤器提供的比较器
比较器描述
BinaryComparator
使用pareTo()比较当前值与阈值
BinaryPrefixComparator
与上面的相似,使用Bytes.conpareTo()进行匹配,但是是从左端开始前缀匹配
NullComparator
不做匹配,只判断当前值是不是Null
BitComparator
通过BitwiseOp类提供的按位于(AND)和(OR),异或(XOR)操作执行位级比较
RegexStringComparator
根据一个正则表达式,在实例化这个比较器的时候去匹配表中的数据
SubstringComparator
把阈值和表中数据当做String实例,同时通过contains()操作匹配字符
后面的3种比较器,即BitComoarator,RegexStringComparator和SubstringComparator,只能与EQUAL和NOT_RQUAL运算符搭配使用,因为这些比较器的compareTo()方法匹配时返回0,不匹配时返回1。如果和LESS或GREATER运算符搭配使用,会产生错误结果。

用户需要了解,HBase中过滤器本来的目的是为了筛掉无用的信息。被过滤掉的信息不会被传送到客户端。过滤器不能用来指定用户需要哪些信息,而是在读取数据的过程中不返回用户不想要的额信息。
正好相反,所有基于CompareFilter的过滤处理过程与上面所描述的恰好相反,他们返回匹配的值。换句话说,用户需要根据过滤器的不同规则来小心地挑选过滤器。例如,如果用户需要返回大于或等于某值的数据,就不应当使用LESS来跳过不需要的数据,而应当使用GREATER_OR_EQUAL来包括所有符合条件的数据。
1.4.专用过滤器
HBase提供的第二类过滤器直接继承自FilterBase,同时用于更特定的使用场景。其中的一些过滤器只能做行筛选,因此只适用于扫描操作。对get()方法来说,这些过滤器限制的过于苛刻:要么包括整行,要么什么都不包括。
2.计数器
许多收集统计信息的应用有点击流或在线广告意见,这些应用需要被收集到日志文件中用于后续的分析。用户可以使用计数器做实时统计,从而放弃延时较高的批量处理操作。
与之前介绍的原子操作检查并修改(check-adn-modify)一样,HBase也有一种机制可以将列当做计数器。如果没有计数器,如果用户需要对一行数据加锁,然后读取数据,再对当前数据做加法,最后写回HBase并释放该行锁,从而其他写程序可以访问该行数据。这样做会引起大量的资源竞争问题,尤其是当客户端进程崩溃之后,尚未释放的锁需要等待超时恢复----这回在一个高负债的系统中引起灾难性后果。
客户端API提供了专门的方法来完成这种读取并修改(read-and-modify)操作,同时在单独一次客户端的调用过程中保证原子性。早期的HBase版本只会在每次计数器更新操作中使用一个RPC请求,不过新版本的HBase中CRUD操作开始使用与此相同的机制,让许多更新计数器的请求都可以在一次RPC中完成。
虽然用户可以一次更新多个计数器,但它们都必须属于同一行。更新多行的计数器需要通过独立的API调用,即多个RPC请求。batch()方法调用目前并不支持Increment实例,不过这种情况今后可能会改变。
3.协处理器
HBase中海油一些特性让用户甚至可以把一部分计算移动到数据的存放端:协处理器(coprocessor)。
3.1.协处理器简介
使用客户端API,配合筛选机制,例如,使用过滤器或限制列族的范围,都可以控制被返回到客户端的数据量。如果可以更进一步优化会更好,例如,数据的处理流程直接放到服务器端执行,然后仅返回一个小的处理结果集。这类似于一个小型的MapReduce框架,该框架将工作分发到整个集群。
协处理器允许用户在region服务器上运行自己的代码,更准确的说允许用户执行region级的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。在客户端,用户不关心操作具体在哪里执行,HBase的分布式框架会帮助用户 把这些工作变得透明。
协处理器框架已经提供了一些类,用户可以通过继承这些类来扩展自己的功能。这些类主要分为两大类,即observer和endpoint。
observer
这一类协处理器与触发器(trigger)类似:回调函数(也被称作钩子函数,hook)在一些特定事件发生时被执行。这些事件包括用户产生的事件,也包括服务器端内部自动产生的事件。
协处理器框架提供的接口如下所示。
observer提供了一些设计好的回调函数,每个操作在集群服务器端都可以被调用。
endpoint
除了事件处理之外还需要将用户自定义操作添加到服务器端。用户代码可以被部署到管理数据的服务器端,例如,做一些服务器端的计算工作。
endpoint通过添加一些远程过程调用来动态扩展RPC协议。可以把他们理解为与RDBMS中类似的存储过程。endpoint可以与observer的实现组合起来直接作用于服务器端的状态。
这些接口都基于Coprocessor框架的接口,以获取一些共有的特性,同时也可以实现自己特有的功能。
最后,协处理器可以被链接起来使用,这个特点与Java Servlet API的过滤器请求相似。
4.连接管理
每个HTable实例都需要建立和远程主机的连接。这些连接在内部使用HConnection类表示,更重要的是,其被HConnectionManager类管理并分享。用户没有必要同时和这两个类打交道,只需要创建衣蛾Configuration实例,然后利用客户端API使用这些类。
HBase内部使用键值映射来存储连接,使用Configration实例作为键值映射的键。换句话说,当你创建很多HTable实例时,如果你提供了相同的Configuration引用,那么它们都共享一个底层的HConnection实例。
共享Zookeeper连接
因为每个客户端最终都需要Zookeeper连接来完成表的region地址初始寻址。连接一旦建立后,共享就变得很有意义,这使得之后的客户端实例可以共用。
缓存通用资源
通过Zookeeper查询到的-ROOT-和.META.的地址,以及region的地址定位都需要网络传输的开销。这些地址将被缓存在客户端来减少网络的调用次数,因此达到加速寻址的目的。
对于每个连接到远程集群的本地客户端来说,他们的地址表都是相同的,因此运行相同进程的客户端共享连接非常有用,这是通过共享HConnection实例来实现的。另外,当寻址失败时(如region拆分时),连接有内置的重试机制来刷新缓存,对于其他所有共享相同连接引用的客户端来说,这项更改立即生效,因此这更加减少了客户端初始化连接的开销。
另一个受益的类是HTablePool,所有连接池中的HTable实例都自动共用一个提供的Configuration实例,因此它们也共享连接。因此当用户想创建多个HTable实例时,最好先创建一个共用的Configuration实例。
共享连接的缺点在于释放,如果用户不显示关闭连接,它将一直存在,知道客户端退出。这样可能导致很多Zookeeper连接都保持打开状态,尤其是在大型分布式环境下,比如执行MapReduce作业的HBase程序,这样可能会产生一些问题。最坏的情况是耗尽所有的连接句柄或内存,并导致I/O异常。
用户可以通过显式关闭连接来避免这种情况。建议用户不再需要HTbale时主动调用HTable的close()方法,调用这个方法将释放所有共享资源,其中包括Zookeeper连接,同时移除内部列表中的链接引用。
每次用户重用Configuration实例时,连接管理器都会增加引用计数器。因此用户必须调用close()来触发清楚工作。



