
- 作者:老汪软件技巧
- 发表时间:2024-11-16 04:01
- 浏览量:
前言
在我之前的文章中提到过在现在的前端的面试中,关于浏览器和工程化的题目屡见不鲜,而在浏览器的范围内,浏览器缓存可以说是非常高频的考点了。毕竟不管怎么说,在互联网技术快速发展的今天,网站性能成为了用户体验的关键因素之一。而浏览器缓存作为提高网站性能的有效手段,对于减少网络延迟、加快页面加载速度具有重要作用。本文将探讨如何使用原生Node.js来优化浏览器缓存策略,特别是如何正确地设置HTTP响应头来控制缓存行为。
正文浏览器缓存基础
浏览器缓存是一种存储机制,允许浏览器临时保存从Web服务器下载的数据副本。当用户再次访问相同的页面或资源时,浏览器可以从本地缓存中直接读取数据,而不是每次都向服务器发出请求。举个很简单的例子,那就是百度主页的logo。
相信很多读者姥爷都曾经注意到,在一些节假日期间,百度的logo是会变化的,而在平常的绝大多数时间里,都是一成不变的。那么也就是说,如果可以将这个图片保存下来的话,以后打开的话就不需要再去发送器接口请求,而是直接从本地获取就可以了。这样不仅可以显著减少网络流量,还能大大缩短页面加载时间,从而提升用户体验。
原生node创建服务
在讨论浏览器的缓存前,得先有一个http服务才行。这里为了避免还没接触过node框架的小伙伴看不懂,我就用node自带的http去创建一个最简单的http服务,代码如下
const http = require('http'); // 导入Node.js内置的http模块,用于创建HTTP服务器
const server = http.createServer((req, res) => { // 创建HTTP服务器,传入请求处理函数
res.end('hello world'); // 发送文件内容作为响应
});
server.listen(3000, () => { // 启动服务器,监听3000端口
console.log('服务已启动: http://localhost:3000'); // 输出启动信息到控制台
});
需要补充的是,由于本文主要讲的还是浏览器缓存的相关内容,所以对一些node基础的相关内容不做过多赘述,我会在注释中做部分解释,其余的大家可以自行百度或者ai。
利用node运行起来上面的代码之后,我们可以在本地3000端口看见一个hello world,就说明项目成功运行了。
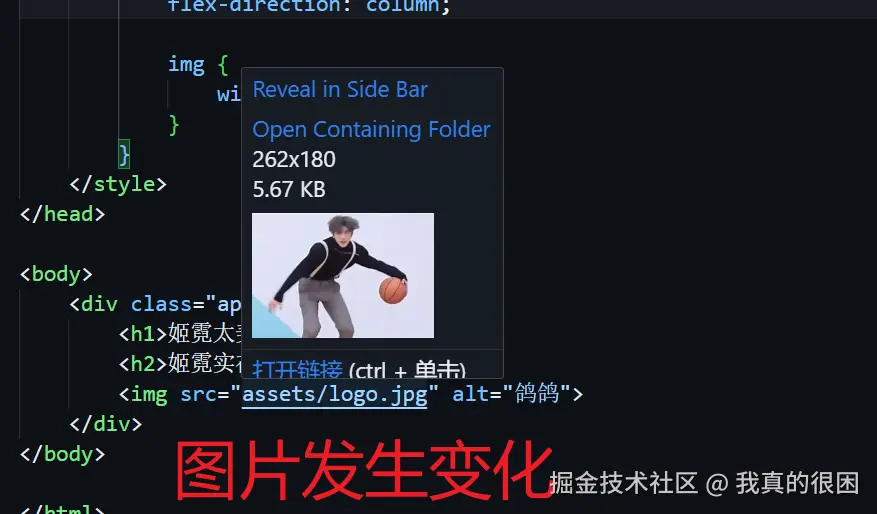
当然,一般的网页肯定不只有一个简单的hello。所以这里我们多整点花样。我在根目录下新建一个page文件夹,然后在page文件夹中新建一个index.html。并在page中新建一个名为asset的文件夹,里面放一张名为logo的图片。目录结构如下:
root
├── www/
│ ├── assets/
│ │ └── logo.jpg
│ └── index.html
├── http.js
Html就随便写点啥了,我这里图方便就只放了两个标题以及logo图片。
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
.app {
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
img {
width: 400px;
}
}
style>
head>
<body>
<div class="app">
<h1>姬霓太美h1>
<h2>姬霓实在是太美h2>
<img src="assets/logo.jpg" alt="鸽鸽">
div>
body>
html>
然后根据前端请求的地址去返回相对应的html文件。那么我们就需要再引入url和fs两个模块分别用于获取请求路径和读取文件,同时,为了更好配置content-type,我这里用了mime-type插件去获取文件的后缀。
const http = require('http'); // 导入Node.js内置的http模块,用于创建HTTP服务器
const url = require('url'); // 导入Node.js内置的url模块,用于解析URL
const fs = require('fs'); // 导入Node.js内置的fs模块,用于文件系统操作
const path = require('path');
const mime = require('mime-types');
const server = http.createServer((req, res) => { // 创建HTTP服务器,传入请求处理函数
let parseUrl = url.parse(`http://${req.headers.host}${req.url}`); // 解析请求的完整URL,提取路径部分
let filePath = path.join(__dirname, 'www', parseUrl.pathname); // 构建文件路径,指向`www`目录下的`index.html`文件
const stats = fs.statSync(filePath)//获取文件状态
const isDir = stats.isDirectory()//判断是否为文件夹
if (isDir) {// 如果是文件夹,则拼接上`index.html`
filePath = path.join(filePath, 'index.html')
}
if (fs.existsSync(filePath)) { // 如果文件存在
const data = fs.readFileSync(filePath); // 读取文件内容
const { ext } = path.parse(filePath)//使用mime-types模块,根据文件后缀名获取文件类型
res.writeHead(200, { // 设置响应头,状态码为200(表示成功)
'Content-Type': mime.lookup(ext), // 设置响应内容类型为文件类型
});
return res.end(data); // 发送文件内容作为响应
} else {// 文件不存在
res.writeHead(404, { // 设置响应头,状态码为404(表示资源不存在)
'Content-Type': 'text/html;charset=utf-8', // 设置响应内容类型为HTML,并指定字符编码为UTF-8
});
return res.end('文件不存在
');
}
});
server.listen(3000, () => { // 启动服务器,监听3000端口
console.log('服务已启动: http://localhost:3000'); // 输出启动信息到控制台
});
这样一来,当我访问3000端口的时候就能获得页面了。这种方式就是服务器渲染,也是前端最初的工作方式,那个时候的前端还被叫做切图仔。

强缓存
接下来,当我们疯狂刷新页面的时候,我们就能够发现浏览器发送了两个主要的请求分别用于请求页面和图片并且状态码都是200。那么我们能不能控制让浏览器不再去发请求,而是在第一次拿到这份html和图片之后就保存下来呢。这就不得不提到强缓存了。
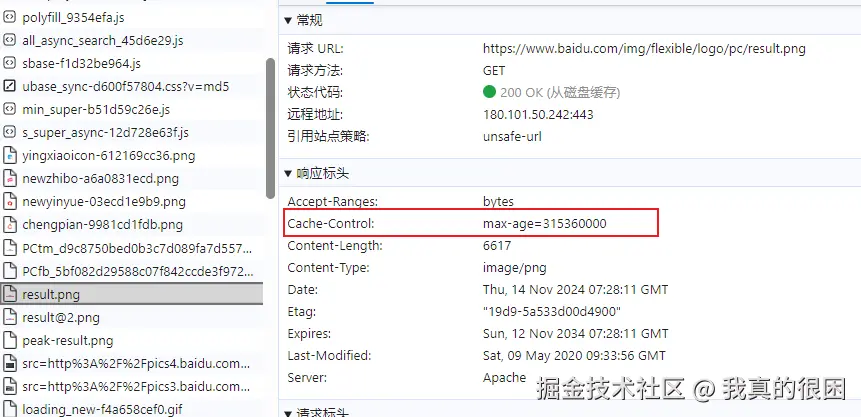
还是继续看我们最开始提到的百度主页,就拿logo来说,我们可以在网络请求中发现这张logo的响应头中有一个名为cache-control的字段,其中的max-age为315360000,这就意味着这张图片会被保存在用户的电脑中整整315360000秒,也就是整整3650天。既然如此,那我们也这么干试试。实现方式也很简单,既然是添加在响应头中,那么我们在代码中加上一行就行
res.writeHead(200, { // 设置响应头,状态码为200(表示成功)
'Content-Type': mime.lookup(ext), // 设置响应内容类型为文件类型
'cache-control': 'max-age=5'
});
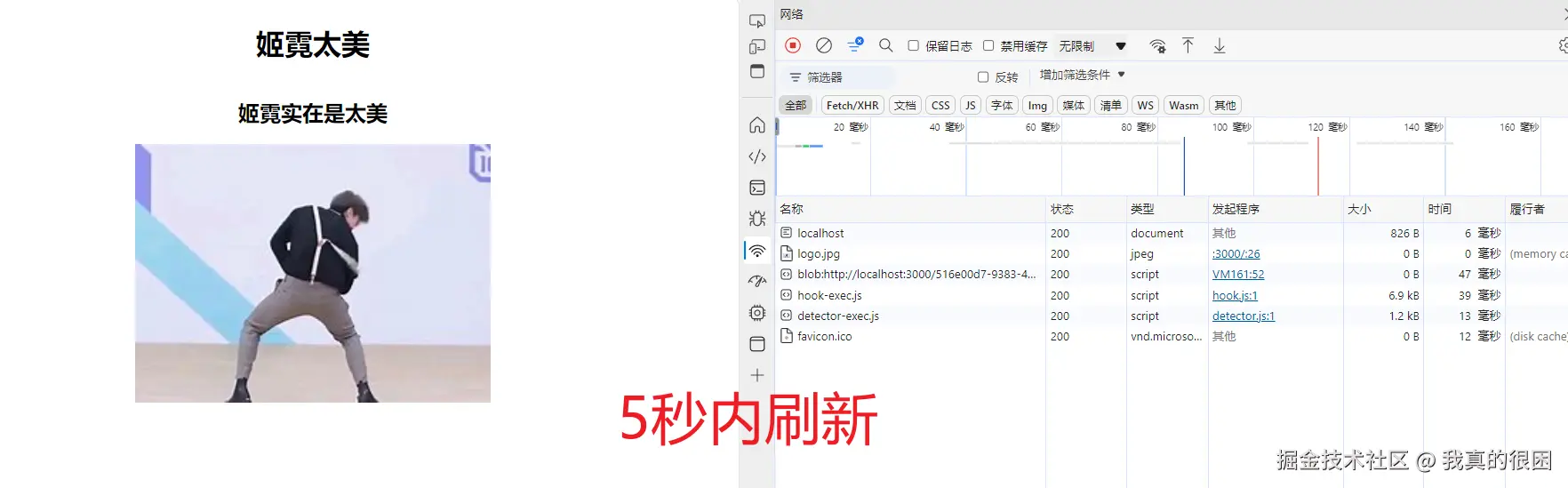
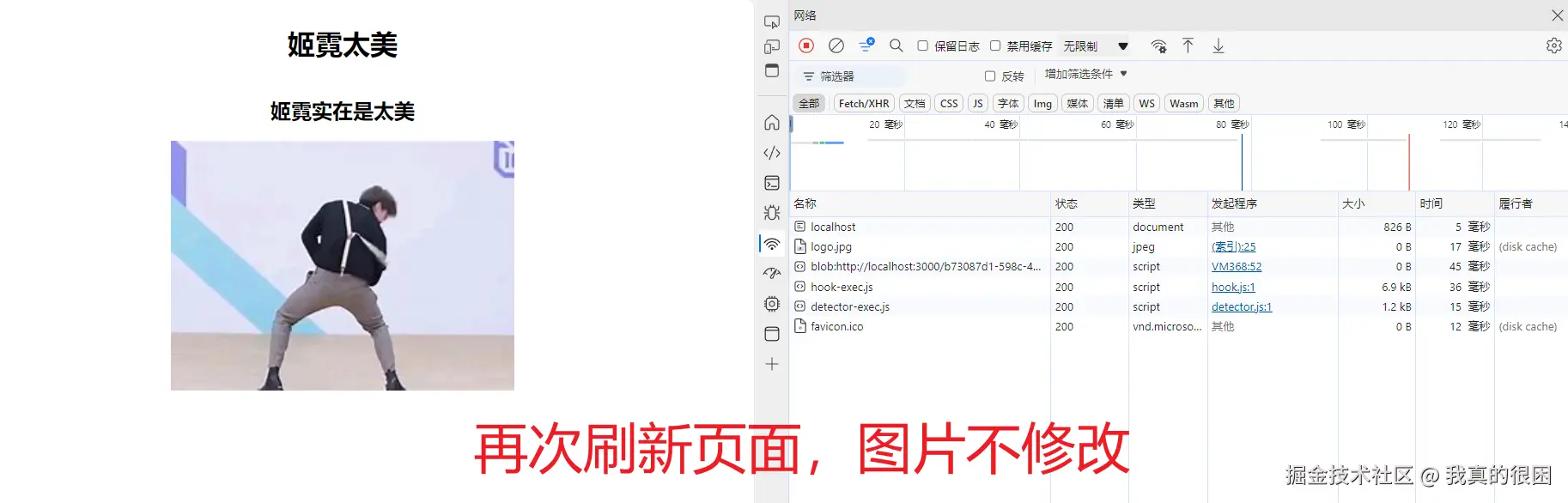
这里我设置的最大缓存时间为5秒,那么当我们在5秒内刷新页面的话,可以看到logo图片的大小变为0了,而5秒后,缓存被清空,这时候再去刷新页面的话,图片会重新加载。
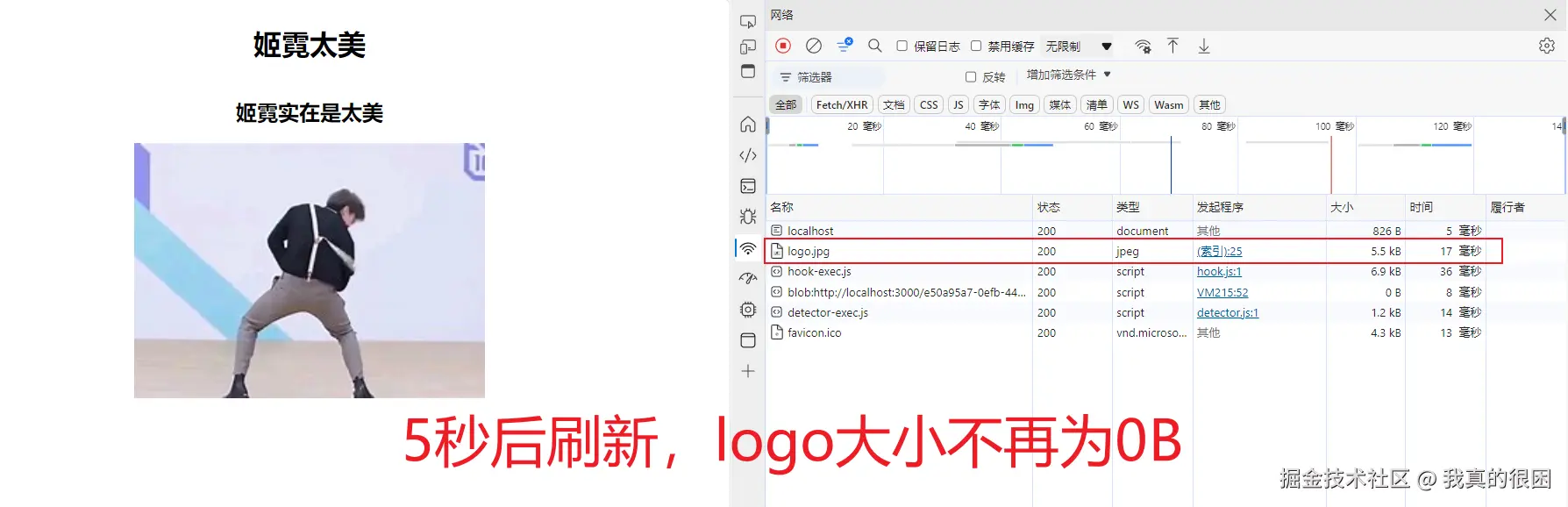
虽说有了强缓存之后,浏览器确实可以减少部分请求发送,但是问题也随之而来,首先就是我们在上面的图片中可以看到无论是在缓存时间内还是超出缓存时间后,html的大小一直都没变。说明强缓存策略对我们这份html文件不起作用。
原因也很简单,我们这里的html是依靠URL请求获取的,而强缓存对URL发送的get请求获取的资源无法进行缓存。
除此之外,现在我们去把图片修改一下,为了效果更明显,我把max-age设久一点。
res.writeHead(200, { // 设置响应头,状态码为200(表示成功)
'Content-Type': mime.lookup(ext), // 设置响应内容类型为文件类型
'cache-control': 'max-age=6000'
});
可以看到,当图片更新之后,我们刷新页面却没有看见更新后的图片,这就关系到强缓存的另一个缺陷——后端资源修改之后无法实时拿到最新的资源。
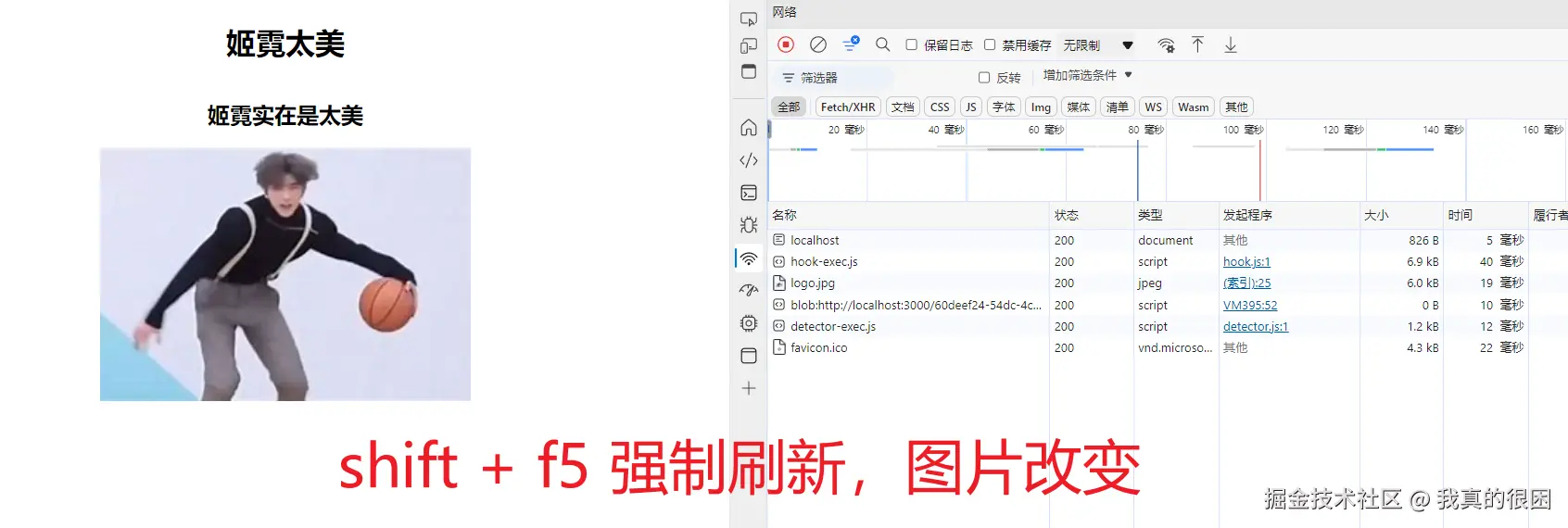
这样一来,我们就不得不找到另一种更加靠谱的方式去缓存我们的网页。由此,协商缓存应运而生。
协商缓存
与强缓存十分类似的是,协商缓存也是通过在响应头中设置对应的字段去实现的,不同点在于,协商缓存的“值”是一个文件签名。这里我利用的是checksum模块去生成内容对应的文件签名。
const http = require('http'); // 导入Node.js内置的http模块,用于创建HTTP服务器
const url = require('url'); // 导入Node.js内置的url模块,用于解析URL
const path = require('path'); // 导入Node.js内置的path模块,用于处理文件路径
const fs = require('fs'); // 导入Node.js内置的fs模块,用于文件系统操作
const mime = require('mime-types'); // 导入mime-types模块,用于获取文件的MIME类型
const checksum = require('checksum'); // 导入checksum模块,用于生成文件的校验和
const server = http.createServer((req, res) => { // 创建HTTP服务器,传入请求处理函数
let parsedUrl = url.parse(req.url); // 解析请求的URL
let filePath = path.join(__dirname, 'www', parsedUrl.pathname); // 构建文件路径,指向`www`目录下的文件
if (fs.existsSync(filePath)) { // 检查文件或目录是否存在
const isDir = fs.statSync(filePath).isDirectory(); // 检查是否为目录
if (isDir) { // 如果是目录,则拼接上`index.html`
filePath = path.join(filePath, 'index.html');
}
if (fs.existsSync(filePath)) { // 再次检查文件是否存在
checksum.file(filePath, (err, hash) => { // 生成文件的校验和
if (err) { // 如果生成校验和时出错
res.writeHead(500, { 'Content-Type': 'text/html;charset=utf-8' }); // 设置响应头,状态码为500(表示内部服务器错误)
res.end('服务器错误
'); // 发送错误信息
return;
} else {
const etag = `"${hash}"`; // 将校验和用双引号包裹,形成ETag
const { ext } = path.parse(filePath); // 获取文件扩展名
// 检查客户端请求头中的If-None-Match是否与当前ETag匹配
if (req.headers['if-none-match'] === etag) {
res.writeHead(304, { // 设置响应头,状态码为304(表示未修改)
'Content-Type': mime.lookup(ext), // 设置响应内容类型为文件类型
'Etag': etag // 设置ETag
});
res.end(); // 发送空响应
} else {
const resStream = fs.createReadStream(filePath); // 创建文件读取流
res.writeHead(200, { // 设置响应头,状态码为200(表示成功)
'Content-Type': mime.lookup(ext), // 设置响应内容类型为文件类型
'Etag': etag // 设置ETag
});
resStream.pipe(res); // 将文件内容通过管道发送到响应
}
}
});
} else { // 文件不存在
res.writeHead(404, { 'Content-Type': 'text/html;charset=utf-8' }); // 设置响应头,状态码为404(表示资源不存在)
res.end('未找到资源
'); // 发送404错误信息
}
} else { // 文件或目录不存在
res.writeHead(404, { 'Content-Type': 'text/html;charset=utf-8' }); // 设置响应头,状态码为404(表示资源不存在)
res.end('未找到资源
'); // 发送404错误信息
}
});
server.listen(3000, () => { // 启动服务器,监听3000端口
console.log('Server running at http://localhost:3000/'); // 输出启动信息到控制台
});
当文件签名在响应头中被设置之后,文件的请求头会自带一个Etag。那么当我们接受到请求的时候就可以先判断请求头中的etag和我们文件生成的etag是否一样,如果一样的话就说明本地缓存的文件和我们的文件一模一样,如此一来我们只需要将响应码设定为304,让请求重定向找本地的缓存文件即可。
总结
在这篇文章中,我为各位读者老爷简单介绍了一下浏览器缓存的重要性及其在提升网站性能方面的作用。浏览器缓存不仅能够显著减少网络流量,还能大幅缩短页面加载时间,从而提升用户体验。通过一个简单的Node.js服务,我们展示了如何通过设置HTTP响应头来控制缓存行为,从而实现高效的缓存策略。
在实际开发中,合理利用浏览器缓存不仅可以减轻服务器的压力,还可以提升应用的整体性能。无论是通过强缓存还是协商缓存,都能在不同的场景下发挥其独特的优势。强缓存适用于那些不经常变化的静态资源,如图片、CSS和JavaScript文件,而协商缓存则更适合那些可能会频繁更新的动态资源,如HTML文件。
通过这篇文章,希望读者能够对浏览器缓存有一个更全面的理解,并在实际项目中灵活运用这些技术,以提升应用的性能和用户体验。浏览器缓存虽然只是一个小小的细节,但在现代Web开发中却起着至关重要的作用。希望各位开发者能够在日常工作中不断探索和实践,找到最适合自己的缓存策略。最后,祝各位读者姥爷0 waring(s),0 error(s)!



