
- 作者:老汪软件技巧
- 发表时间:2024-10-06 00:01
- 浏览量:
为什么 Elasticsearch 不建议深度分页?
Elasticsearch 在处理分页时,深度分页会引发性能问题。主要原因是 Elasticsearch 的分页机制是通过 from + size 参数来实现的,即它会跳过前 from 个文档并返回接下来的 size 个文档。
随着 from 值变大(即深度分页),Elasticsearch 需要跳过大量的文档,这会带来以下几个问题:
内存消耗大:Elasticsearch 为了实现跳过,需要在内存中维护一个较大的排序列表,这会导致内存消耗急剧增加。查询性能下降:跳过大量文档后,还要对剩下的文档进行排序、过滤等操作,查询时间也会随之增加,尤其在海量数据时尤为明显。
为了避免这些问题,Elasticsearch 官方推荐使用其他方案来解决深度分页的需求,比如使用 scroll API 或 search_after。
实际场景案例场景描述:
假设我们有一个电商平台,用户可以通过搜索框来查询商品列表。用户想要翻页浏览商品,而某些高频用户会尝试翻到非常深的页面(比如第 100 页或更深)。在传统的 from + size 方案下,系统的响应速度会变得很慢且消耗大量资源。为了解决这个问题,我们可以使用 search_after 方法来优化分页性能。
search_after 通过上一个查询的最后一个文档的排序值来继续分页,不会像 from + size 那样需要跳过所有之前的文档,因此性能要好得多。
基础框架:Spring Boot + Elasticsearch RestHighLevelClient步骤:依赖配置使用 search_after 来实现深度分页实现复杂查询场景(如多条件查询、排序等)代码实现:1. 添加依赖
首先,在 pom.xml 文件中添加 elasticsearch 和 spring-boot-starter-data-elasticsearch 依赖。
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.10.0version>
dependency>
dependencies>
2. 配置 Elasticsearch 客户端
在 application.properties 中配置 Elasticsearch 连接信息:
spring.elasticsearch.rest.uris=http://localhost:9200
然后创建配置类,初始化 RestHighLevelClient:
@Configuration
public class ElasticsearchConfig {
@Bean
public RestHighLevelClient client() {
return new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
}
}
3. 实现复杂查询和深度分页
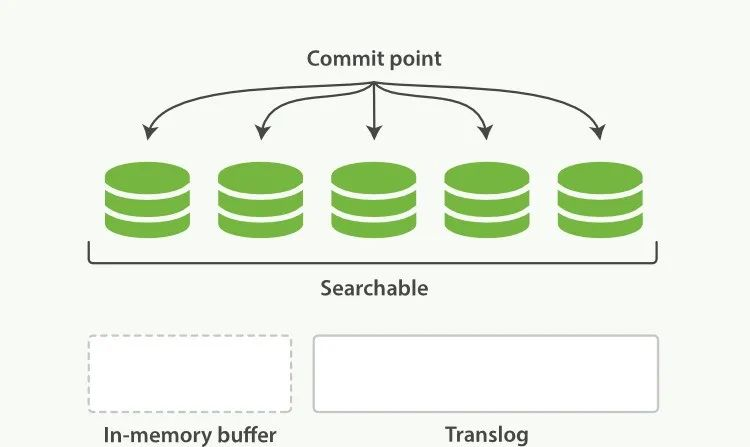
创建一个 Product 对象,用于封装商品信息:
@Data
@Document(indexName = "products")
public class Product {
private String id;
private String name;
private String description;
private double price;
private String category;
private long timestamp; // 用于排序的字段
}
创建服务类,用于处理 Elasticsearch 查询:
@Service
public class ProductService {
@Autowired
private RestHighLevelClient client;
public SearchResponse searchProducts(String keyword, String category, Double minPrice, Double maxPrice, int size, Object[] searchAfter) throws IOException {
SearchRequest searchRequest = new SearchRequest("products");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if (keyword != null && !keyword.isEmpty()) {
boolQuery.must(QueryBuilders.matchQuery("name", keyword));
}
if (category != null && !category.isEmpty()) {
boolQuery.filter(QueryBuilders.termQuery("category.keyword", category));
}
if (minPrice != null) {
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(minPrice));
}
if (maxPrice != null) {
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(maxPrice));
}
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(boolQuery);
sourceBuilder.size(size);
// 根据时间戳进行排序,确保分页的顺序一致
sourceBuilder.sort(new FieldSortBuilder("timestamp").order(SortOrder.DESC));
// 使用 search_after 实现深度分页
if (searchAfter != null) {
sourceBuilder.searchAfter(searchAfter);
}
searchRequest.source(sourceBuilder);
return client.search(searchRequest, RequestOptions.DEFAULT);
}
}
4. 控制器层代码
创建 REST 控制器,提供接口来处理前端的分页请求:
@RestController
@RequestMapping("/products")
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/search")
public ResponseEntity> searchProducts(
@RequestParam(required = false) String keyword,
@RequestParam(required = false) String category,
@RequestParam(required = false) Double minPrice,
@RequestParam(required = false) Double maxPrice,
@RequestParam(defaultValue = "10") int size,
@RequestParam(required = false) Object[] searchAfter
) throws IOException {
SearchResponse response = productService.searchProducts(keyword, category, minPrice, maxPrice, size, searchAfter);
List> products = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
products.add(hit.getSourceAsMap());
}
Map result = new HashMap<>();
result.put("products", products);
// 将当前返回结果的最后一个文档的排序值返回给前端,便于下一次分页请求
if (response.getHits().getHits().length > 0) {
result.put("searchAfter", response.getHits().getHits()[response.getHits().getHits().length - 1].getSortValues());
}
return ResponseEntity.ok(result);
}
}
5. 测试接口
通过 GET 请求访问 /products/search,传递搜索条件、分页大小以及 searchAfter 参数。返回的 JSON 结果中会包含产品列表以及 searchAfter 字段,用于下一页请求。
示例请求:
GET /products/search?keyword=phone&category=electronics&minPrice=100&maxPrice=1000&size=10
示例响应:
{
"products": [
{
"id": "1",
"name": "iPhone 12",
"description": "Latest Apple iPhone",
"price": 999.99,
"category": "electronics",
"timestamp": 1609459200
},
...
],
"searchAfter": [1609459200, "1"]
}
在前端使用 searchAfter 进行下一页请求:
GET /products/search?keyword=phone&category=electronics&minPrice=100&maxPrice=1000&size=10&searchAfter=[1609459200,"1"]
总结
通过 search_after 代替传统的 from + size,我们有效地解决了深度分页带来的性能问题。特别是在处理大量数据时,search_after 可以避免跳过大量文档,显著提升分页查询的性能。



