
- 作者:老汪软件技巧
- 发表时间:2024-01-03 02:00
- 浏览量:
目录
经验是智慧之父,记忆是智慧之母。
——谚语
一、实验介绍
本实验实现了一个简单的循环神经网络(RNN)模型,并使用该模型进行序列数据的预测,本文将详细介绍代码各个部分的实现,包括模型的定义、训练过程以及预测结果的可视化。
在前馈神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力.在生物神经网络中,神经元之间的连接关系要复杂得多.前馈神经网络可以看作一个复杂的函数,每次输入都是独立的,即网络的输出只依赖于当前的输入.但是在很多现实任务中, 网络的输出不仅和当前时刻的输入相关,也和其过去一段时间的输出相关.比如一个有限状态自动机,其下一个时刻的状态(输出)不仅仅和当前输入相关,也和当前状态(上一个时刻的输出)相关.此外,前馈网络难以处理时序数据,比如视频、语音、文本等.时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变.因此,当处理这一类和时序数据相关 的问题时,就需要一种能力更强的模型. 循环神经网络( ,RNN)是一类具有短期记忆能力的神经网络.
在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构.和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构.循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上.循环神经网络的参数学习可以通过随时间反向传播算法[, 1990]来学习.随时间反向传播算法即按照时间的逆序将错误信息一步步地往前传递.
二、实验环境
本系列实验使用了深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
软件包
本实验版本
目前最新版
3.5.3
3.8.0
numpy
1.21.6
1.26.0
3.7.16
-learn
0.22.1
1.3.0
torch
1.8.1+cu102
2.0.1
0.8.1
2.0.2
0.9.1+cu102
0.15.2
三、实验内容 0. 导入必要的工具包
import torch
from torch import nn
import matplotlib.pyplot as plt
import numpy as np1. RNN模型
class Rnn(nn.Module):
def __init__(self, input_size):
super(Rnn, self).__init__()
# 定义RNN网络
## hidden_size是自己设置的,取值都是32,64,128这样来取值
## num_layers是隐藏层数量,超过2层那就是深度循环神经网络了
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=32,
num_layers=1,
batch_first=True # 输入形状为[批量大小, 数据序列长度, 特征维度]
)
# 定义全连接层
self.out = nn.Linear(32, 1)
# 定义前向传播函数
def forward(self, x, h_0):
r_out, h_n = self.rnn(x, h_0)
# print("数据输出结果;隐藏层数据结果", r_out, h_n)
# print("r_out.size(), h_n.size()", r_out.size(), h_n.size())
outs = []
# r_out.size=[1,10,32]即将一个长度为10的序列的每个元素都映射到隐藏层上
for time in range(r_out.size(1)):
# print("映射", r_out[:, time, :])
# 依次抽取序列中每个单词,将之通过全连接层并输出.r_out[:, 0, :].size()=[1,32] -> [1,1]
outs.append(self.out(r_out[:, time, :]))
# print("outs", outs)
# stack函数在dim=1上叠加:10*[1,1] -> [1,10,1] 同时h_n已经被更新
return torch.stack(outs, dim=1), h_n
a. 初始化 self.out是一个全连接层,将RNN的输出映射到1维输出。 b. 前向传播方法 2. 训练和预测 a. 超参数
TIME_STEP = 10
INPUT_SIZE = 1
LR = 0.02b. 创建模型实例
model = Rnn(INPUT_SIZE)
print(model)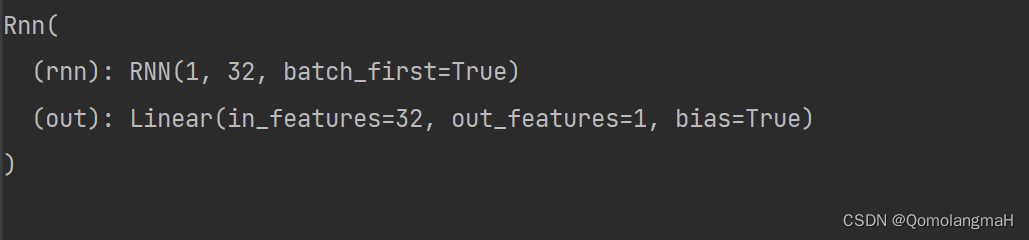
c. 模型训练
使用正弦和余弦序列数据作为输入和目标输出,通过迭代训练,模型通过反向传播和优化器来不断调整参数以最小化预测结果与目标输出之间的损失。
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
h_state = None # 初始化h_state为None
for step in range(300):
# 人工生成输入和输出,输入x.size=[1,10,1],输出y.size=[1,10,1]
start, end = step * np.pi, (step + 1) * np.pi
# np.linspace生成一个指定大小,指定数据区间的均匀分布序列,TIME_STEP是生成数量
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32)
# print("steps", steps)
x_np = np.sin(steps)
y_np = np.cos(steps)
# print("x_np,y_np", x_np, y_np)
# 从numpy.ndarray创建一个张量 np.newaxis增加新的维度
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
# print("x,y", x,y)
# 将x通过网络,长度为10的序列通过网络得到最终隐藏层状态h_state和长度为10的输出prediction:[1,10,1]
prediction, h_state = model(x, h_state)
h_state = h_state.data
# 这一步只取了h_state.data.因为h_state包含.data和.grad 舍弃了梯度
# print("precision, h_state.data", prediction, h_state)
# print("prediction.size(), h_state.size()", prediction.size(), h_state.size())
# 反向传播
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
# 更新优化器参数
optimizer.step()d. 预测结果可视化
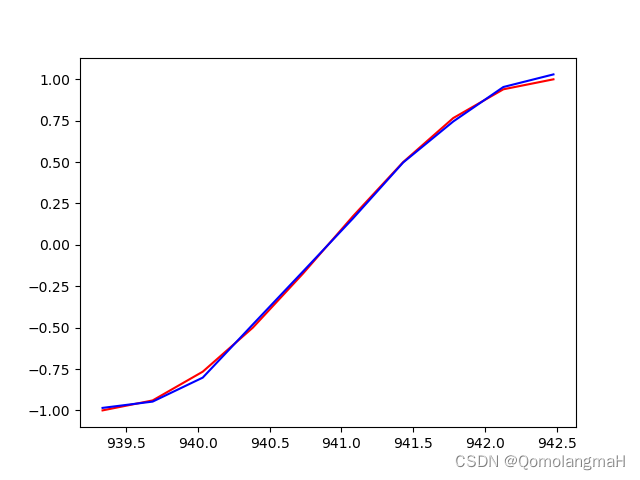
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.show()
将真实的目标输出数据和模型的预测结果进行可视化展示。
3. 代码整合
# 导入必要的工具包
import torch
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
# 定义RNN模型
class Rnn(nn.Module):
def __init__(self, input_size):
super(Rnn, self).__init__()
# 定义RNN网络
## hidden_size是自己设置的,取值都是32,64,128这样来取值
## num_layers是隐藏层数量,超过2层那就是深度循环神经网络了
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=32,
num_layers=1,
batch_first=True # 输入形状为[批量大小, 数据序列长度, 特征维度]
)
# 定义全连接层
self.out = nn.Linear(32, 1)
# 定义前向传播函数
def forward(self, x, h_0):
r_out, h_n = self.rnn(x, h_0)
# print("数据输出结果;隐藏层数据结果", r_out, h_n)
# print("r_out.size(), h_n.size()", r_out.size(), h_n.size())
outs = []
# r_out.size=[1,10,32]即将一个长度为10的序列的每个元素都映射到隐藏层上
for time in range(r_out.size(1)):
# print("映射", r_out[:, time, :])
# 依次抽取序列中每个单词,将之通过全连接层并输出.r_out[:, 0, :].size()=[1,32] -> [1,1]
outs.append(self.out(r_out[:, time, :]))
# print("outs", outs)
# stack函数在dim=1上叠加:10*[1,1] -> [1,10,1] 同时h_n已经被更新
return torch.stack(outs, dim=1), h_n
if __name__ == '__main__':
TIME_STEP = 10
INPUT_SIZE = 1
LR = 0.02
model = Rnn(INPUT_SIZE)
print(model)
# 此处使用的是均方误差损失
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
h_state = None # 初始化h_state为None
for step in range(300):
# 人工生成输入和输出,输入x.size=[1,10,1],输出y.size=[1,10,1]
start, end = step * np.pi, (step + 1) * np.pi
# np.linspace生成一个指定大小,指定数据区间的均匀分布序列,TIME_STEP是生成数量
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32)
# print("steps", steps)
x_np = np.sin(steps)
y_np = np.cos(steps)
# print("x_np,y_np", x_np, y_np)
# 从numpy.ndarray创建一个张量 np.newaxis增加新的维度
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
# print("x,y", x,y)
# 将x通过网络,长度为10的序列通过网络得到最终隐藏层状态h_state和长度为10的输出prediction:[1,10,1]
prediction, h_state = model(x, h_state)
h_state = h_state.data
# 这一步只取了h_state.data.因为h_state包含.data和.grad 舍弃了梯度
# print("precision, h_state.data", prediction, h_state)
# print("prediction.size(), h_state.size()", prediction.size(), h_state.size())
# 反向传播
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
# 更新优化器参数
optimizer.step()
# 对最后一次的结果作图查看网络的预测效果
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.show()



