
- 作者:老汪软件技巧
- 发表时间:2024-12-31 10:05
- 浏览量:91
一 时序数据库概述
时序数据库(Time Series Database, TSD)是一种专门设计用于存储、索引和检索时间序列数据的数据库。时间序列数据是指带有时间戳的数据,通常用于记录随着时间变化的度量值。时序数据库在多个领域有着广泛的应用,特别是在物联网(IoT)、金融、工业自动化、能源管理、电信和 IT 监控等领域。
InfluxDB 是一种时序数据库,时序数据库通常被用在监控场景,比如运维和 IOT(物联网)领域。这类数据库旨在存储时序数据并实时处理它们。比如。我们可以写一个程序将服务器上 CPU 的使用情况每隔 10 秒钟向 InfluxDB 中写入一条数据。接着,我们写一个查询语句,查询过去 30 秒 CPU 的平均使用情况,然后让这个查询语句也每隔 10 秒钟执行一次。最终,我们配置一条报警规则,如果查询语句的执行结果>xxx,就立刻触发报警。InfluxDB 使用了一种专门设计用于高效存储时间序列数据的二进制格式,称为 TSM(Time Series Measurement)格式。这种格式是为了优化写入性能、压缩存储空间和加快查询速度而设计的。
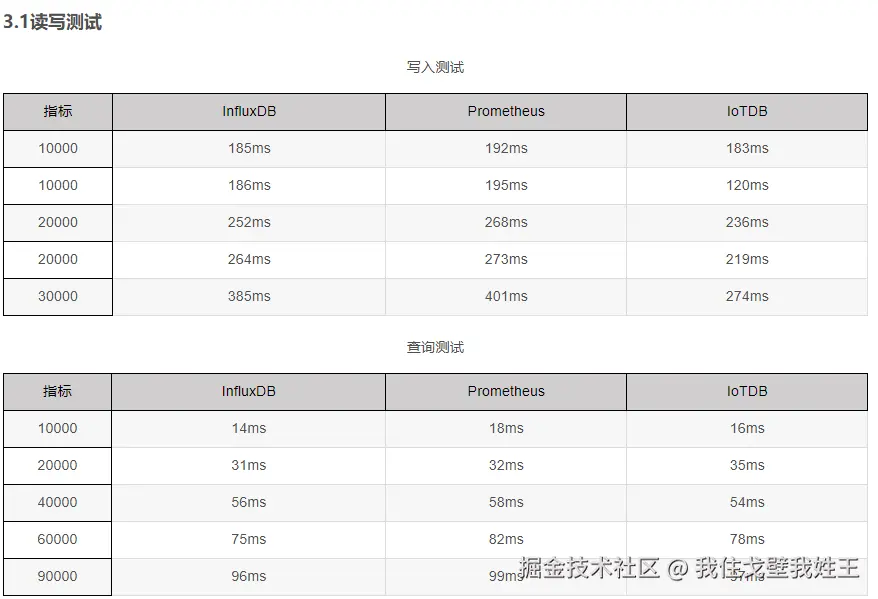
1.1 相比关系型数据库MySQL优势(1)写入性能
关系型数据库也是支持时间戳的,也能够基于时间戳进行查询。但是,从我们的使用场景出发,需要注意数据库的写入性能。通常,关系型数据库会采用 B+树数据结构,在数据写入时,有可能会触发叶裂变,从而产生了对磁盘的随机读写,降低写入速度。
当前市面上的时序数据库通常都是采用LSM Tree 的变种,顺序写磁盘来增强数据的写入能力。网上有不少关于性能测试的文章,同学们可以自己去参考学习,通常时序数据库都会保证在单点每秒数十万的写入能力。参见:
(2)数据价值
我们之前说,时序数据库一般用于指标监控场景。这个场景的数据有一个非常明显的特点就是冷热差别明显。通常,指标监控只会使用近期一段时间的数据,比如我只查询某个设备最近 10 分钟的记录,10 分钟前的数据我就不再用了。那么这 10 分钟前的数据,对我们来说就是冷数据,应该被压缩放到磁盘里去来节省空间。而热数据因为经常要用,数据库就应该让它留在内存里,等待查询。而市面上的时序数据库大都有类似的设计。
(3)时间不可倒流,数据只写不改
时序数据是描述一个实体在不同时间所处的不同状态。 就像是我们打开任务管理器,查看 CPU 的使用情况。我发现 CPU 占用率太高了,于是杀死了一个进程,但 10 秒前的数据不会因为我关闭进程再发生改变了。这是时序数据的一大特点。与之相应,时序数据库基本上是插入操作较多,不会有更新需求。
1.2 为什么性能数据查询使用influxDB,而活动告警监控使用redis?
性能数据是时序数据,而告警数据不属于时序数据库;
性能数据需要进行时间聚合、分析计算,InfluxDB 提供了Flux查询语言,支持复杂的查询和聚合操作,非常适合用于性能监控数据分析。而告警不需要进行聚合、计算的操作
告警数据量远不如性能数据量,性能数据可以使用influxDB的自动过期策略(TTL),清理七天之前的数据;活动告警性质决定不适用过期策略,规定上限5w条,超出则将最久远的数据剔除,作为历史告警存到ES中,这里可以使用 Redis 的 List 数据结构。Redis 的 List 是一个链表结构,非常适合用来实现 FIFO(先进先出)队列,从而实现自动剔除最旧数据的功能。 插入数据:使用RPUSH命令将新的数据插入到列表的尾部。限制长度:使用LTRIM命令将列表的长度限制在5万条以内。
告警监控对实时性要求比性能查询更高
1.3 相比Prometheus而言influxDB的优势
/xuruilll/ar…
1.3.1查询复杂度增加时的表现差距较大
PromQL:PromQL 在处理简单的聚合查询(如对单个指标的求和、平均值计算等)时效率较高。但当查询复杂度增加,如涉及多个指标的关联聚合、复杂的条件筛选和多层嵌套聚合时,其性能可能会受到影响。因为这些复杂的查询可能需要更多的计算资源和时间来遍历和处理数据。例如,在计算一个包含多个子系统指标的复杂业务指标聚合(如根据不同服务的请求成功率和响应时间计算整体服务质量指标)时,PromQL 可能需要在多个时间序列之间进行关联和计算,导致效率下降。
Flux:Flux 由于其强大的管道操作和函数组合功能,在处理复杂查询时具有一定的优势。它可以通过灵活的管道操作将复杂的查询分解为多个简单的步骤,逐步处理数据。然而,过于复杂的查询仍然可能导致性能问题,尤其是当管道操作过长或者涉及大量数据转换和聚合时。例如,在进行跨多个存储桶的复杂数据分析和聚合时,Flux 需要处理的数据量和操作步骤可能会使查询效率降低。
1.3.2 场景多个指标的关联聚合
含义:
在监控系统中,指标是用于衡量系统某个方面状态的数据。多个指标的关联聚合是指将两个或多个不同的指标按照一定的规则组合在一起进行聚合计算,以获取更有意义的信息。
示例:
假设在一个 Web 服务监控场景中,有两个指标:http_requests_total(总的 HTTP 请求数)和http_response_time_seconds(HTTP 响应时间,单位为秒)。为了了解每个请求的平均响应时间,可以通过关联聚合这两个指标来计算。在 PromQL 中,可能的查询语句是sum(http_response_time_seconds) / sum(http_requests_total)。这个查询将总的响应时间除以总的请求数,得到平均响应时间。这就是关联聚合两个不同指标(请求数和响应时间)来获取一个新的、更具业务价值的指标(平均响应时间)的例子。
**
**
二 influxDB理论与原理2.1 influxDB行协议
下面这种数据格式是InfluxDB数据库使用的,只要数据符合下面这种格式,就能通过InfluxDB的API将数据导入数据库。

与 CSV 相似,在 InfluxDB 行协议中,一条数据和另一条数据之间使用换行符分隔, 所以一行就是一条数据。另外,在时序数据库领域,一行数据一行数据由下面 4 种元素构成。
目前,你可以将它理解为关系型数据库中的一张表。是必需存在的,测量的名称。每个数据点都必须声明自己是哪个测量里面的 ,不可省略。大小写敏感。不可以下划线 _ 开头
标签应该用在一些值的范围有限的,不太会变动的属性上。比如性能指标包含的位置信息(资源实例)等等。在InfluxDB中一个Tag相当于一个索引。给数据点加上Tag有利于将来对数据进行检索。但是如果索引太多了,就会减慢数据的插入速度。
【空格】
行协议中的空格决定了InfluxDB如何解释数据点。第一个未转义的空格将测量值&Tag Set (标签集)与 Field Set(字段集) 分开。第二个未转义空格将Field Set(字段级)和时间戳分开。

2.2 协议中的数据类型及其格式1)Float(浮点数)
IEEE-754标准的64位浮点数。这是默认的数据类型。
示例:字段级值类型为浮点数的行协议
myMeasurement fieldKey=1.0
myMeasurement fieldKey=1
myMeasurement fieldKey=-1.234456e+78
2)Integer(整数)
有符号64位整数。需要在数字的尾部加上一个小写数字 i 。
整数最小值 整数最大值
-9223372036854775808i 9223372036854775807i
示例:字段值类型为有整数的
3)UInteger(无符号整数)
无符号64位整数。需要在数字的尾部加上一个小写数字 u 。
无符号整数最小值 无符号整数最大值
0u 18446744073709551615u
示例:字段值类型为无符号整数的航协议
myMeasurement fieldKey=1u
myMeasurement fieldKey=12485903u
4)String(字符串)
普通文本字符串,长度不能超过64KB
示例:
# String measurement name, field key, and field value
myMeasurement fieldKey="this is a string"
5)Boolean(布尔值)
true或者false。
示例:
myMeasurement fieldKey=true
myMeasurement fieldKey=false
myMeasurement fieldKey=t
myMeasurement fieldKey=f
myMeasurement fieldKey=TRUE
myMeasurement fieldKey=FALSE
不要对布尔值使用引号,否则会被解释为字符串
6)Unix Timestamp(Unix 时间戳)
如果你写时间戳,myMeasurementName fieldKey="fieldValue" 1556813561098000000
7)注释
以井号 # 开头的一行会被当做注释。
示例:
这是一行数据
myMeasurement fieldKey="string value" 1556813561098000000
2.3 常用概念
与传统数据库中的名词做比较:
influxDB中的名词传统数据库中的概念
database
数据库
measurement
数据库中的表
points
表里面的一行数据
想要正确使用时序数据库,就必须理解时序数据库管理数据的逻辑。这里,我们会和普通的 SQL(关系型)数据库做一下比较。
下面这张表示 SQL(关系型)数据库中一个简单的示例。表中有创建索引和未创建索引的列。
park_id、planet、time 是创建了索引的列。_foodships 是未创建索引的列。
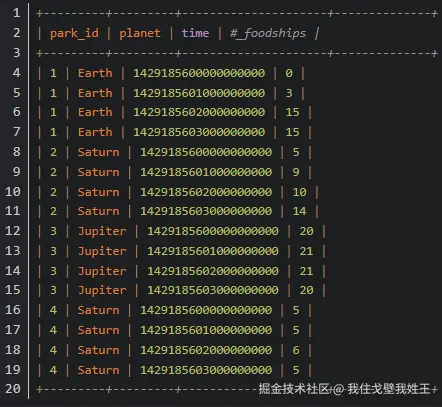
--》
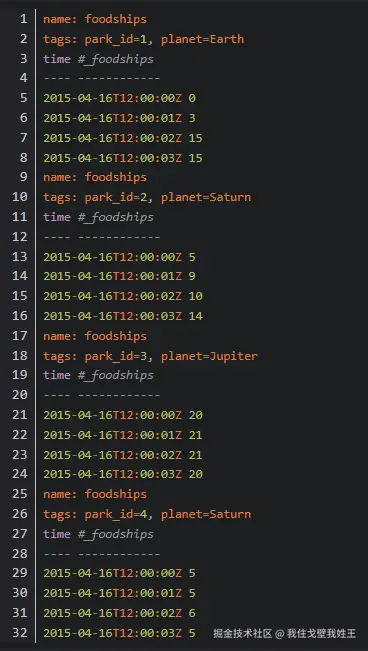
理解序列的概念至关重要
简单来说,InfluxDB 这类数据库是用序列的方式来管理数据的。在 InfluxDB 中,唯一 的 measurement,tag_set 和 fileld(一个字段)组合是一个 series(序列) 。比如下图中有 6 条连续的线,这里面每个条线就是一个序列。每一个序列的数据在内存和磁盘上紧密存放, 这样当你要查询这一序列的数据时,InfluxDB 可以很快定位到这一序列中的好多条数据。你也可以将measurement,tag,field 视为索引,而且它们本身就是索引。
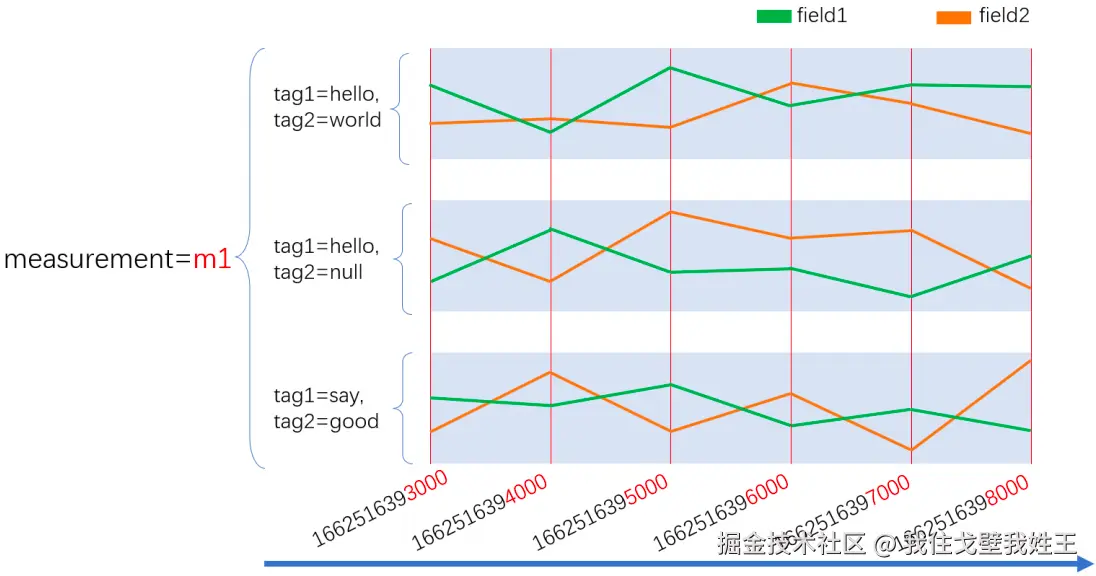
以序列的方式管理数据是时序数据库和传统关系型数据库最不同的地方。传统的关系型数据库通常是以 record(记录或者行)的方式管理数据,这个时候,关系型数据库可以让你快速地通过索引定位到一条数据。但是在时序场景下,我们通常需要查找某个设备最近一段时间的数据。 这个时候对于传统关系型数据库来说,很可能需要多次寻址来找到多个 record 才能完成查询。而时序库是把索引打到一批次的数据上,所以在这种场景的下的读写,时序库性能是远强于 B+树数据库的。
双索引设计与高效查询思路
我们之前说到你可以将 measurement、tag_set 和 field 视为索引,还没有提到最重要的时间。其实,在 InfluxDB 中时间也是索引,数据在入库时,会按时间戳进行排序。这样, 我们在进行查询时,一般遵循下面的思路。先指定要从哪个存储桶查询数据,指定数据的时间范围指定 measurement、tag_set和 field 说明我要查询哪个序列。
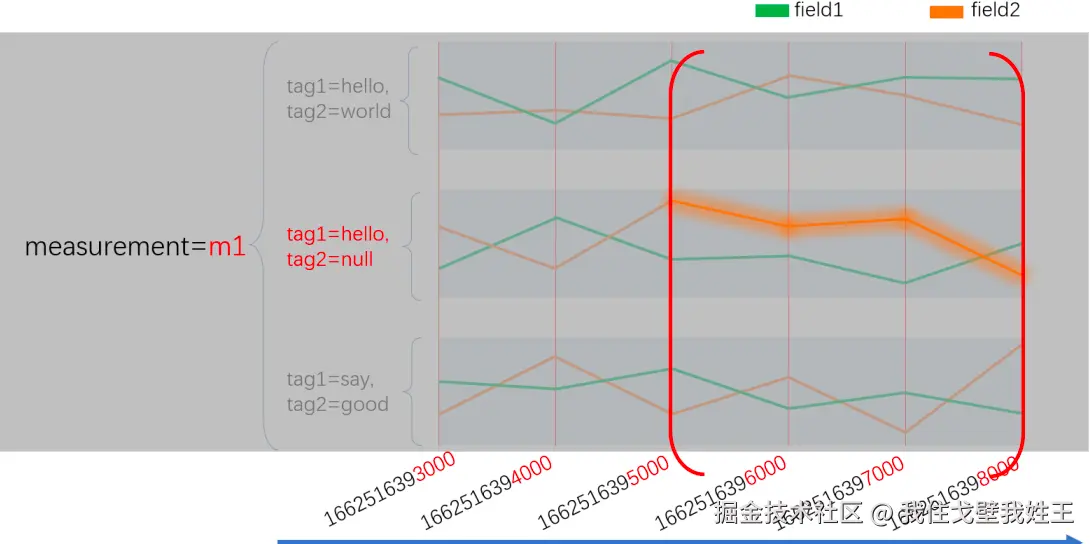
我一次只能查询一个序列吗,一次只能查询一个序列,这显然是不合理的。假如,我现在只指定要查询 measurent 为 m1 和 tag1 为 hello 的数据,那么就会命中图中 4 条序列。所以实际上,measurement,tag,field 都是倒排索引。
时间线膨胀(高基数问题)
时间线膨胀是所有时序数据库都绕不过的问题。简单地来解释时间线膨胀,就是我们的时序数据库中序列太多了。当序列过多时,时序数据库的写入和读取性能通常都会有明显的下降。所以,当你去网上看一些时序数据库的压测文章时,需要注意文章有没有将序列数考虑进去。设计的时候可以利用influxDB的自动过期策略(TTL)保存最近一周的数据,来保证influxDB写入和读取的性能。
2.4 存储引擎
TSM Tree 是 InfluxDB 根据实际需求在 LSM Tree 的基础上稍作修改优化而来。TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
TSM 存储引擎的特点三InfluxDB语言
InfluxDB 提供了两种查询语言:InfluxQL 和 Flux。
InfluxQL 是 InfluxDB 最初提供的查询语言,支持传统的 SQL 风格的 DML 语句,如 INSERT, SELECT, 和 DELETE。Flux 是 InfluxDB 2.x 版本中引入的新查询语言,提供了更强大的数据处理能力和更灵活的查询方式,但不直接支持 INSERT 和 DELETE 语句,而是通过 API 或函数来实现这些操作。
3.1InfluxQL
历史背景:InfluxQL 是 InfluxDB 最初提供的类似于SQL的查询语言,它的设计受到了 SQL 的启发,使得熟悉 SQL 的用户可以更容易上手。
功能:InfluxQL 提供了基本的查询功能,如选择、过滤、分组、聚合等。它主要用于简单的数据检索和分析任务。
限制:
3.1.1 插入数据
INSERT cpu,host=server01 usage_idle=99,usage_user=1 1434055562000
3.1.2 查询数据
SELECT usage_idle, usage_user FROM cpu WHERE host='server01'
SELECT * FROM cpu WHERE time > now() - 1h
3.2 Flux四 数据存储目录与文件结构
influxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录:
这两个目录下的结构是相似的,其基本结构如下:
# wal 目录结构
-- wal
-- mydb
-- autogen
-- 1
-- _00001.wal
-- 2
-- _00035.wal
-- 2hours
-- 1
-- _00001.wal
# data 目录结构
-- data
-- mydb
-- autogen
-- 1
-- 000000001-000000003.tsm
-- 2
-- 000000001-000000001.tsm
-- 2hours
-- 1
-- 000000002-000000002.tsm
其中 mydb 是数据库名称,autogen 和 2hours 是存储策略名称,再下一层目录中的以数字命名的目录是 shard 的 ID 值,比如 autogen 存储策略下有两个 shard,ID 分别为 1 和 2,shard 存储了某一个时间段范围内的数据。再下一级的目录则为具体的文件,分别是 .wal 和 .tsm 结尾的文件。
具体使用参见:/qq_44766883…



