
- 作者:老汪软件技巧
- 发表时间:2024-12-31 00:11
- 浏览量:
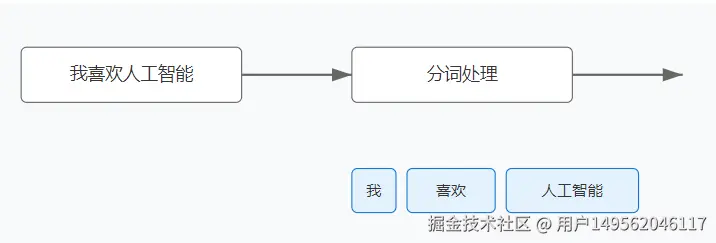
我们在调用大模型之前,往往会进行分词器分词,进行分词器分词后,然而还需要嵌入。其中的原因在于它们的功能和作用是相辅相成的。分词器的任务是将文本转化为模型可以处理的离散单位,而嵌入则负责将这些离散单位转化为模型可以理解的连续数值表示。下面我分别来讲讲他们的作用到底是什么。
一、模型自注意力前面的处理流程描述
1.文本分词:输入句子被分词器(如 WordPiece、BPE 等)处理,转化为 token 索引序列。
示例:"I love cats" → [101, 1045, 2293, 8873, 102]
2.词嵌入(Embedding):将每个 token 索引映射为一个高维连续向量(如 768 维)。果是一个矩阵,形状为 索引长度 × 嵌入维度,表示整个序列的嵌入。
[1045, 2293, 8873] → 向量 [[0.5, -0.2, ...], [1.2, 0.8, ...], [0.3, -0.7, ...]]
3.嵌入加位置信息:自注意力机制对序列位置不敏感,因此需要引入 位置编码(Positional Encoding) 或 位置嵌入(Positional Embedding) 来区分不同 token 的顺序。最终结果是每个 token 的嵌入向量加上位置信息,形成输入矩阵。4.自注意力机制:模型接收嵌入后的序列向量,计算每个 token 与其他 token 的相关性。这一步通过生成 Query(Q)、Key(K) 和 Value(V),计算加权关系并更新表示。上面4个流程体现了 自注意力机制(Self-Attention)的输入就是经过 词嵌入 后的连续向量表示。
二、分词器
分词器负责将输入文本拆分为更小的单元(如单词、子词或字符),然后将这些单元映射为离散的 索引(tokens),例如:

输入句子:"I love cats"
分词器输出:[101, 1045, 2293, 8873, 102]
这一步的目的是将自然语言转化为离散的符号序列,便于后续处理。
二、词嵌入
嵌入是将分词器生成的离散索引转化为连续的、密集的向量表示(embedding vectors)。这些向量表示模型理解每个单元的语义、上下文关系等。离散索引本身没有语义信息,嵌入的引入解决了以下问题:1.捕捉语义信息分词后的索引 [1045, 2293, 8873] 只是数字,没有语义,而嵌入将其映射为高维向量(如 300 维或 768 维),捕捉单词的语义关系。例如,"love" 和 "like" 的向量会更接近,而 "love" 和 "cat" 的向量则稍远。2.在向量空间建模上下文嵌入允许模型捕捉上下文关系,在句子 "I love cats" 中,嵌入可以帮助模型理解 love 是一种情感,而 cats 是一个具体的实体。嵌入还可以帮助模型建模更复杂的上下文,如词在句子中的顺序和作用。
三、分词器 + 嵌入:相辅相成
分词器和嵌入的结合是深度学习模型处理文本的关键步骤:1.分词器将自然语言分解为离散符号(tokens)。2.嵌入将这些符号转化为连续向量表示,便于神经网络处理。比如 Transformer 架构(如 BERT 或 GPT),就是依赖分词器将文本拆解为子词单元,然后使用嵌入层将这些子词表示为向量,输入到模型中。
三、为什么两者都不可缺少?
有的同学可能会问,如果我们只采用分词器,或者只采用词嵌入不就可以了吗,都是转化成特定维度的向量,最后交给大模型。我来给大家说说舍弃其中一个的问题。1.只采用分词器模型只能处理离散的 token 索引,而离散的索引之间没有语义信息。模型也无法捕捉词与词之间的关系。2.只采用词嵌入如果没有分词器的预处理,直接嵌入整段文本会导致复杂性过高(例如处理词表外单词或长文本)。
四、总结
分词器:将文本分解为可处理的最小单元(tokens)。嵌入:为这些最小单元提供语义信息的数值表示。只有当二者结合才能高效处理自然语言并输入到深度学习模型中,让模型既理解词语的语义,又能建模其上下文关系。



