
- 作者:老汪软件技巧
- 发表时间:2024-12-31 00:11
- 浏览量:
深度学习网络通过 GPU 进行 profile 分析,我们发现大部分 kernel都是带宽瓶颈(bandwidth bound 或者 IO bound),对IO bound 类的整网优化,我们可以通过算子 Fusion 的方案进行有效解决,充分利用 L2 Cache和 L1 Cache 以及共享缓存,即通过高速 cache 的命中率提升解决带宽瓶颈问题,后续我们会通过其他的文章进行说明,本文档针对算子内的一个 kernel 如何通过向量化 loads 和 store 增加 GPU 带宽利用率,降低发射执行的指令数进行说明,本文档包含以下几部分
GPU vector
在 GPU 编程中,“向量化(Vectorization) ” 通常是指让每个线程一次性处理多个数据元素(而不是只处理一个标量),并且使用 GPU 硬件或编译器支持的“向量操作”或“向量指令”来完成这些批量数据的读写与计算。这样做的好处是,可以在相同或更少的指令数下完成更多数据的处理,从而提高吞吐量与效率,GPU 支持的向量化数据类型存储在 vector_types.h 中,下面是一部分示例
typedef __device_builtin__ struct char1 char1;
typedef __device_builtin__ struct uchar1 uchar1;
typedef __device_builtin__ struct char2 char2;
typedef __device_builtin__ struct uchar2 uchar2;
typedef __device_builtin__ struct char3 char3;
typedef __device_builtin__ struct uchar3 uchar3;
typedef __device_builtin__ struct char4 char4;
typedef __device_builtin__ struct uchar4 uchar4;
typedef __device_builtin__ struct short1 short1;
typedef __device_builtin__ struct ushort1 ushort1;
typedef __device_builtin__ struct short2 short2;
typedef __device_builtin__ struct ushort2 ushort2;
typedef __device_builtin__ struct short3 short3;
typedef __device_builtin__ struct ushort3 ushort3;
typedef __device_builtin__ struct short4 short4;
typedef __device_builtin__ struct ushort4 ushort4;
typedef __device_builtin__ struct int1 int1;
typedef __device_builtin__ struct uint1 uint1;
typedef __device_builtin__ struct int2 int2;
typedef __device_builtin__ struct uint2 uint2;
typedef __device_builtin__ struct int3 int3;
typedef __device_builtin__ struct uint3 uint3;
typedef __device_builtin__ struct int4 int4;
typedef __device_builtin__ struct uint4 uint4;
typedef __device_builtin__ struct long1 long1;
typedef __device_builtin__ struct ulong1 ulong1;
typedef __device_builtin__ struct long2 long2;
typedef __device_builtin__ struct ulong2 ulong2;
typedef __device_builtin__ struct long3 long3;
typedef __device_builtin__ struct ulong3 ulong3;
typedef __device_builtin__ struct long4 long4;
typedef __device_builtin__ struct ulong4 ulong4;
typedef __device_builtin__ struct float1 float1;
typedef __device_builtin__ struct float2 float2;
typedef __device_builtin__ struct float3 float3;
typedef __device_builtin__ struct float4 float4;
typedef __device_builtin__ struct longlong1 longlong1;
typedef __device_builtin__ struct ulonglong1 ulonglong1;
typedef __device_builtin__ struct longlong2 longlong2;
typedef __device_builtin__ struct ulonglong2 ulonglong2;
typedef __device_builtin__ struct longlong3 longlong3;
typedef __device_builtin__ struct ulonglong3 ulonglong3;
typedef __device_builtin__ struct longlong4 longlong4;
typedef __device_builtin__ struct ulonglong4 ulonglong4;
typedef __device_builtin__ struct double1 double1;
typedef __device_builtin__ struct double2 double2;
typedef __device_builtin__ struct double3 double3;
typedef __device_builtin__ struct double4 double4;
GPU vector loads and stores
load 和 store 的向量化操作指令,是数据加载由变量的数据加载,显式的修改为基于向量化的数据加载, 例如针对 int2 加载和存储的可以 load.64,store.64 ,针对 int4 的向量化加载存储操作可以为 load.128, store.128 同时计算可以基于对应的向量化宽度进行向量化计算,这可以有效的降低指令数目,kenel 的循环次数
案例对比说明
让我们基于一个简单的内存拷贝的案例开始说明
__global__ void device_copy_scalar_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N; i += blockDim.x * gridDim.x) {
d_out[i] = d_in[i];
}
}
void device_copy_scalar(int* d_in, int* d_out, int N)
int threads = 128;
int blocks = min((N + threads-1) / threads, MAX_BLOCKS);
device_copy_scalar_kernel<<>>(d_in, d_out, N);
}
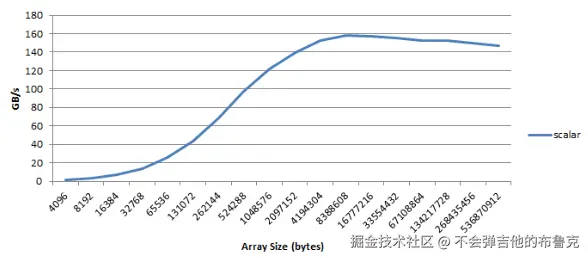
上述代码中,我们使用一个基于网格步长的循环,即每个线程负责其 idx 对应的 index,步长为整个网络大小的数据拷贝,例如 id=0 拷贝一次为 0,0+网格宽度,0+2*网格宽度,...,上限为输入数据的最大 size,由于 warp内是连续的,这种操作会被 GPU 进行编译优化(Coalesced Memory Accesses)
下图是上方内核随着复制内容大小变化的变化情况
下面我们可以基于汇编指令 颗粒度 分析一下上述 code我们可以使用 CUDA 工具包提供的 cuobjdump 工具来查看这个内核的汇编代码,针对可执行文件执行 cuobjdump,具体命令如下
cuobjdump -sass executable
上述标量拷贝的汇编 code 核心指令具体如下:
/*0058*/ IMAD R6.CC, R0, R9, c[0x0][0x140]
/*0060*/ IMAD.HI.X R7, R0, R9, c[0x0][0x144]
/*0068*/ IMAD R4.CC, R0, R9, c[0x0][0x148]
/*0070*/ LD.E R2, [R6]
/*0078*/ IMAD.HI.X R5, R0, R9, c[0x0][0x14c]
/*0090*/ ST.E [R4], R2
上述 code 我们可以看到与复制操作相关的六条指令。其中四条IMAD指令计算加载和存储地址,而LD.E和ST.E指令则从这些地址加载和存储 32 位数据。
汇编指令说明:
而在 SASS 里,通常用 IMAD(x2) 来计算一个 64 位地址。例如: int idx = blockIdx.x * blockDim.x + threadIdx.x; 或者 i += blockDim.x * gridDim.x
IMAD R6.CC, R0, R9, c[0x0][0x140]IMAD.HI.X R7, R0, R9, c[0x0][0x144]
最终 (R6, R7) 就得到指向 d_in[idx] 这一整型的地址,同理R4 和 R5 存放指向 d_out[idx] 这一整形的地址
IMAD R6.CC, R0, R9, c[0x0][0x140] 整条指令的功能为执行整数乘法和加法的融合操作指令,即表达式为 R6=R0 * R9 + c[0x0][0x140]
IMAD是一条乘加指令(Integer Multiply-Add),用于执行整数乘法和加法的融合操作,这样做的好处是在一些计算场景下(比如在图形处理、并行计算中常见的地址计算、偏移量计算等涉及乘加运算的情况)可以在一个指令周期内完成乘加,提高计算效率
R6.CC表示目标寄存器是R6,并且设置了条件码(Condition Code,CC)相关标志。条件码通常用于后续根据计算结果进行条件判断(比如分支跳转等操作会参考条件码来决定是否执行跳转等情况)
R0、R9是操作数寄存器,该指令会用R0寄存器中的值乘以R9寄存器中的值,然后再加上从立即数(常量)存储位置c[0x0][0x140]中获取的值,最后将结果存储到R6寄存器中。这里的c[0x0][0x140]一般是指常量内存(Constant Memory)中的某个特定位置,以二维数组索引形式来表示,实际在硬件实现上是按照特定的内存布局来存放这些常量的
IMAD.HI.X R7, R0, R9, c[0x0][0x144] IMAD.HI.X是IMAD指令的一种变体形式,其功能为只获取高位的数据
LD.E R2, [R6]:从 (R6,R7) 所指定的全局地址读数据,结果放进寄存器 R2。
ST.E [R4], R2:把寄存器 R2 的数据写入 (R4,R5) 指向的全局地址
d_out[idx] = d_in[idx]; 改代码等价与下面俩行代码//temp 为 R2int temp = d_in[idx]; // 从 d_in 读d_out[idx] = temp; // 写到 d_out
LD.E R2, [R6] LD.E表示加载指令(Load),.E可能表示这是一种特定模式下的加载操作(比如针对特定的内存区域、数据对齐要求等对应的加载模式,不同架构可能有不同解释)
ST.E [R4], R2 ST.E表示存储指令(Store),同样.E表示特定模式下的存储操作 即[R4] = R2 注意这里的 [R4] 表示是 R4 寄存器指向的地址
基于向量化指令进行加速
我们可以通过使用向量化的加载和存储指令LD.E.{64,128}和ST.E.{64,128}来提高此操作的性能。这些操作也用于加载和存储数据,但以 64 位或 128 位的宽度进行。使用向量化的加载可以减少总的指令数、降低延迟并提高带宽利用率.
使用向量加载的最简单方法是使用 CUDA C/C++标准头文件中定义的向量数据类型,通过类型转换在 C/C++中轻松使用这些类型。
例如,在 C++中,你可以将int指针d_in重新类型转换为int2指针,使用
reinterpret_cast(d_in)
在 C99 中,你可以使用转换运算符做同样的事情:(int2*(d_in))如int2、int4或float2 等等内部支持的向量化操作类型
注意: 解引用这些指针将会导致编译器生成向量指令。然而,这里有一个重要的注意事项:这些指令需要对齐的数据。设备分配的内存会自动对齐到数据类型的大小的倍数,但如果偏移指针,偏移量也必须对齐。例如,reinterpret_cast(d_in+1)是无效的,因为d_in+1不是对齐到sizeof(int2)的倍数
如果使用“对齐”的偏移,如reinterpret_cast(d_in+2)所示。你还可以使用结构 struct 生成向量加载,只要 struct 的大小是 2 的幂次,code 如下:
struct Foo {int a, int b, double c}; // 16 bytes in size
Foo *x, *y;
…
x[i]=y[i];
因此基于向量化改造上面简单的内存拷贝后,code 如下:
__global__ void device_copy_vector2_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N/2; i += blockDim.x * gridDim.x) {
reinterpret_cast(d_out)[i] = reinterpret_cast(d_in)[i];
}
// in only one thread, process final element (if there is one)
if (idx==N/2 && N%2==1)
d_out[N-1] = d_in[N-1];
}
void device_copy_vector2(int* d_in, int* d_out, int n) {
threads = 128;
blocks = min((N/2 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector2_kernel<<>>(d_in, d_out, N);
}
这个内核只有少量更改。
Sass 汇编指令如下:
/*0088*/ IMAD R10.CC, R3, R5, c[0x0][0x140]
/*0090*/ IMAD.HI.X R11, R3, R5, c[0x0][0x144]
/*0098*/ IMAD R8.CC, R3, R5, c[0x0][0x148]
/*00a0*/ LD.E.64 R6, [R10]
/*00a8*/ IMAD.HI.X R9, R3, R5, c[0x0][0x14c]
/*00c8*/ ST.E.64 [R8], R6
现在编译器生成了LD.E.64和ST.E.64。其他所有指令都相同。然而,需要注意的是,由于循环只执行 N/2 次,因此执行的指令数量只有原来的一半。这种指令数量上的 2 倍改进在指令受限或延迟受限的内核中非常重要 同理我们将上述 code 修改为 向量4的版本,对应汇编 code 如下:
/*0090*/ IMAD R10.CC, R3, R13, c[0x0][0x140]
/*0098*/ IMAD.HI.X R11, R3, R13, c[0x0][0x144]
/*00a0*/ IMAD R8.CC, R3, R13, c[0x0][0x148]
/*00a8*/ LD.E.128 R4, [R10]
/*00b0*/ IMAD.HI.X R9, R3, R13, c[0x0][0x14c]
/*00d0*/ ST.E.128 [R8], R4
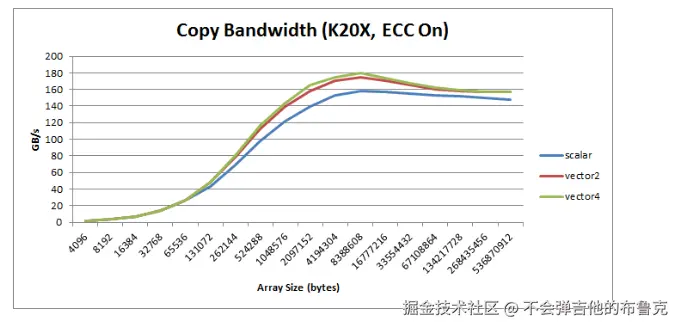
LD.E.128和ST.E.128。这一版本的代码将指令数减少了 4 倍。你可以在下图中看到所有 3 个版本的内核的总体性能,变量操作落后不明显是因为 warp 内操作连续,GPU 底层采用Coalesced Memory Accesses 进行了优化了合并了数据请求
总结
本文档总体介绍说明了向量化加载和对应的指令,并针对标量拷贝,向量化拷贝 进行带宽利用率对比和分析不同方案指令级循环次数的次数减少的倍率
向量化的载荷是 CUDA 优化中的一个基本方法,如果可能我们尽可能使用向量化加载,因为这可以提高带宽、减少指令数并降低延迟。但万事有利有弊,这非常耗费寄存器,会降低我们整体的并行度,所以如果内核已经收到寄存器的限制,或者并行度很低(由于每个线程使用了很多的寄存器或其他的资源限制),使用标量拷贝是一个不错的选择,但是标量拷贝建议每个 warp 内每个线程的变量操作尽可能连续,因为 GPU 会针对这种场景尽可能的利用Coalesced Memory Accesses优化合并成一个请求
引用:



