
- 作者:老汪软件技巧
- 发表时间:2024-12-30 17:03
- 浏览量:
前言
在科技飞速发展的今天,人工智能已经成为了一个不可忽视的领域,本文将结合黄佳老师AI理论课来聊一聊如何在魔搭社区通过数据分析和机器学习来进行直播带货的预测。
魔搭社区:数据科学家的理想实验田
首先,让我们简单了解一下魔搭社区:
作为为AI爱好者提供的免费平台,魔搭社区允许用户上传微调后的模型,并借助阿里云提供的强大虚拟机资源,在Python + AI机器学习环境中开展研究工作。社区中的Python Notebook环境(.ipynb文件格式)以及线上实验室功能,解决了许多学习者因本地计算能力不足而遇到的问题,使复杂的数据处理变得简单且高效。
这种设置非常适合新手尝试自己的想法,而无需额外购置虚拟机等硬件设施。
Python中的模块与分析库Pandas:数据处理的利器Matplotlib:数据可视化的艺术Scikit-Learn (sklearn):机器学习的得力助手数据加载与预览
开搞之前,我们先将一个包含直播带货信息的CSV文件上传至魔搭社区的虚拟机上。然后导入Pandas库,使用pd.read_csv读取CSV文件,并通过df_ads.head()显示数据框的前几行以了解数据结构。
Python
代码如下图所示:
# python 模块引入
# python 最流行的数据分析库
import pandas as pd
# js 异步的 IO 操作
# python 同步
df_ads = pd.read_csv("直播带货.csv")
# 数据样本的尺寸
# print(df_ads.size)
df_ads.head()
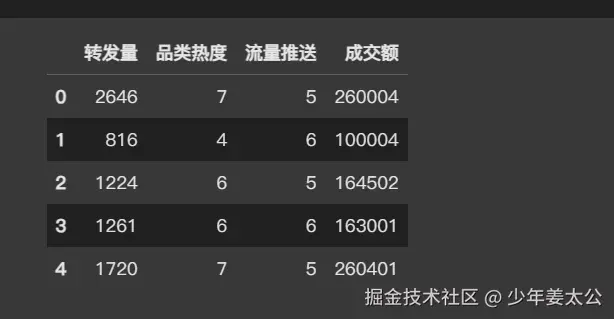
它的结果如下图所示:
数据可视化
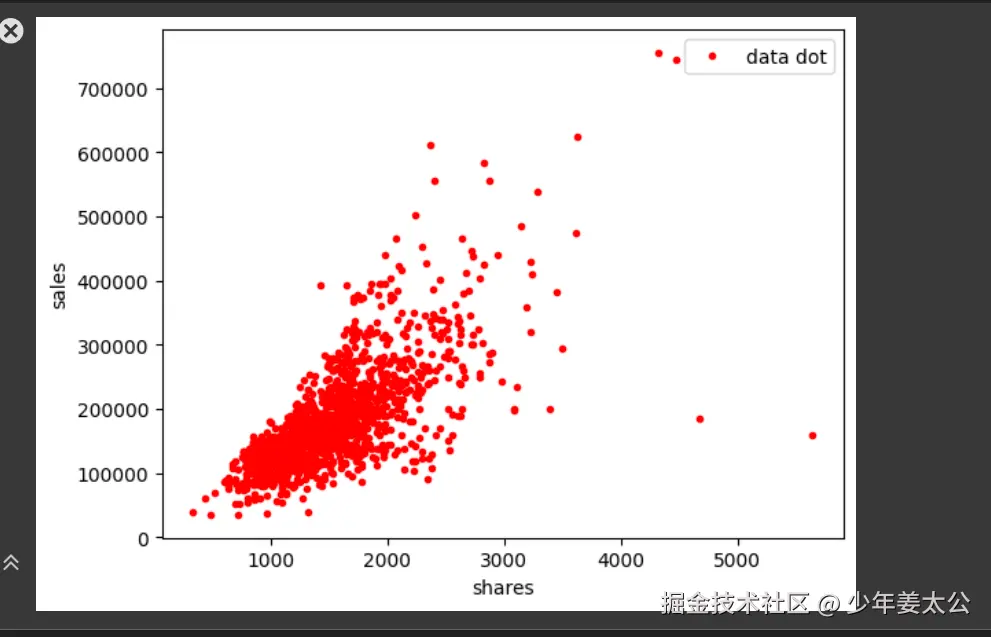
接下来,我们将使用Matplotlib库对数据进行可视化,以便更直观地理解数据间的潜在联系。例如,我们可以绘制散点图来观察“转发量”与“成交额”的关系。
我们可以使用plt.plot绘制散点图,横轴为转发量,纵轴为成交额并设置图表标题、标签和图例,最后使用plt.show()显示图表。代码如下所示:
import matplotlib.pyplot as plt
plt.plot(df_ads['转发量'], df_ads['成交额'], 'r.', label='data dot')
plt.xlabel('shares')
plt.ylabel('sales')
plt.legend()
plt.show()
数据预处理
先使用drop方法移除成交额列,并将剩余列赋值给X,然后将成交额列赋值给y,最后使用X.head()和y.head()显示前几行数据。这一步骤是确保数据适合机器学习算法的关键
# 移除成交额 这一列
# 影响成交额的影响因子拿出来 训练
X = df_ads.drop(["成交额"],axis = 1)
X
# 成交额 特征
y= df_ads.成交额
print(X.head())
y.head()
数据分割与模型训练
导入train_test_split用于数据分割,使用train_test_split将数据分为训练集和测试集。导入LinearRegression模型,使用fit方法训练模型。
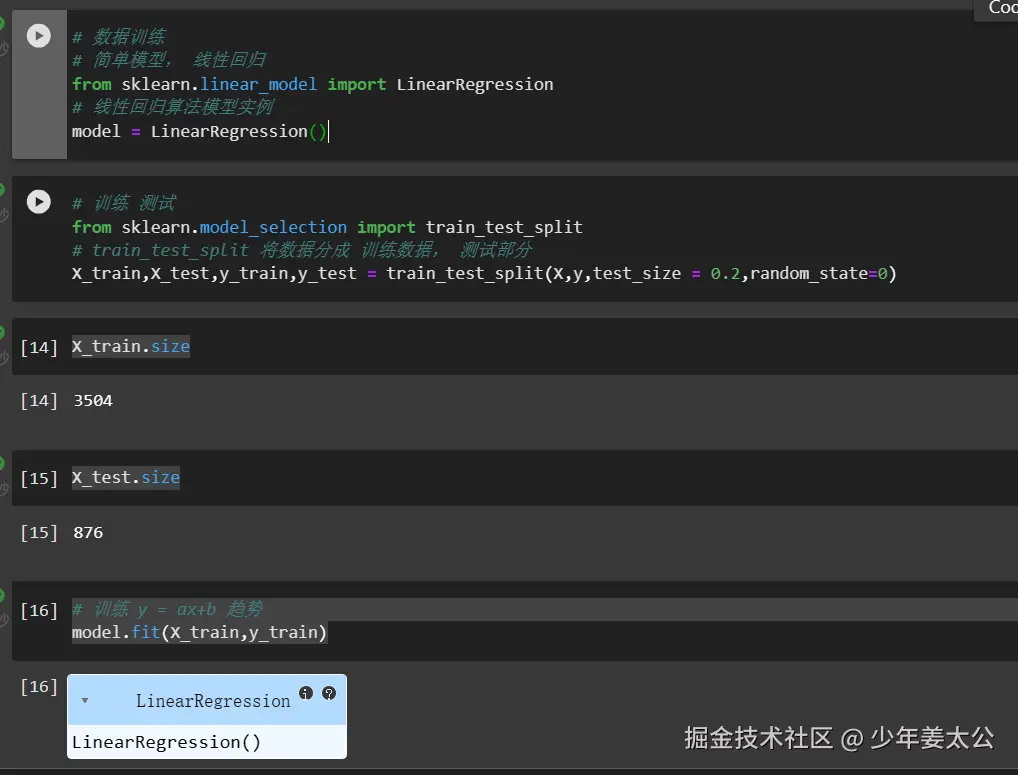
# 数据训练
# 简单模型, 线性回归
from sklearn.linear_model import LinearRegression
# 线性回归算法模型实例
model = LinearRegression()
# 训练 测试
from sklearn.model_selection import train_test_split
# train_test_split 将数据分成 训练数据, 测试部分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state=0)
X_train.size
X_test.size
# 训练 y = ax+b 趋势
model.fit(X_train,y_train)
model = LinearRegression()
model.fit(X_train, y_train)
预测结果展示
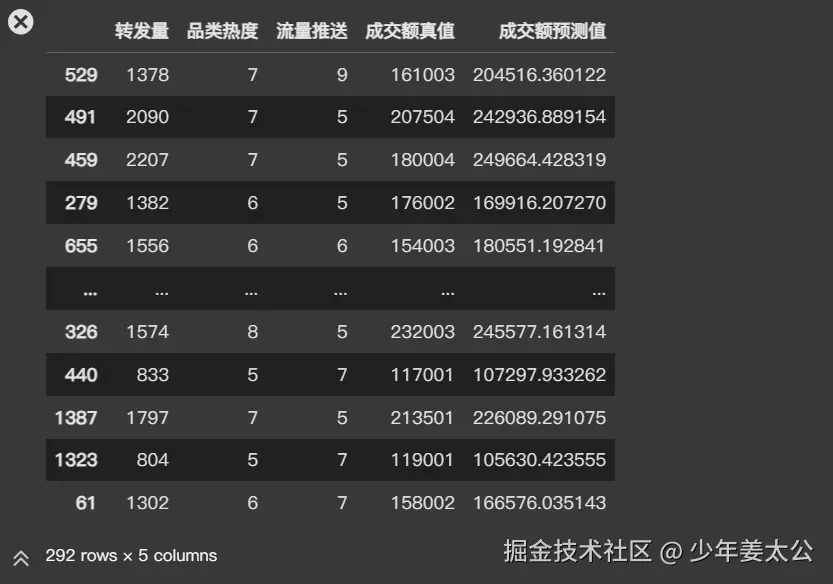
先创建一个新的DataFramedf_ads_pred,并复制X_test的数据,然后添加成交额真值列,值为y_test和成交额预测值列,值为模型预测的结果,最后使用head()显示前几行数据。
# 拷贝测试机数据
df_ads_pred = X_test.copy()
df_ads_pred.head()
df_ads_pred['成交额真值'] = y_test
df_ads_pred['成交额预测值'] = y_pred
df_ads_pred
模型评估
最后,我们使用model.score方法来评估模型的性能,该方法返回的是决定系数R²,它表示了模型对数据的解释程度。
# 大模型自己打分
# 预期的结果数据 衡量模型训练质量
y_pred = model.predict(X_test)
print("线性回归预测集评分", model.score(X_test, y_test))
print("线性回归预测集评分", model.score(X_train, y_train))

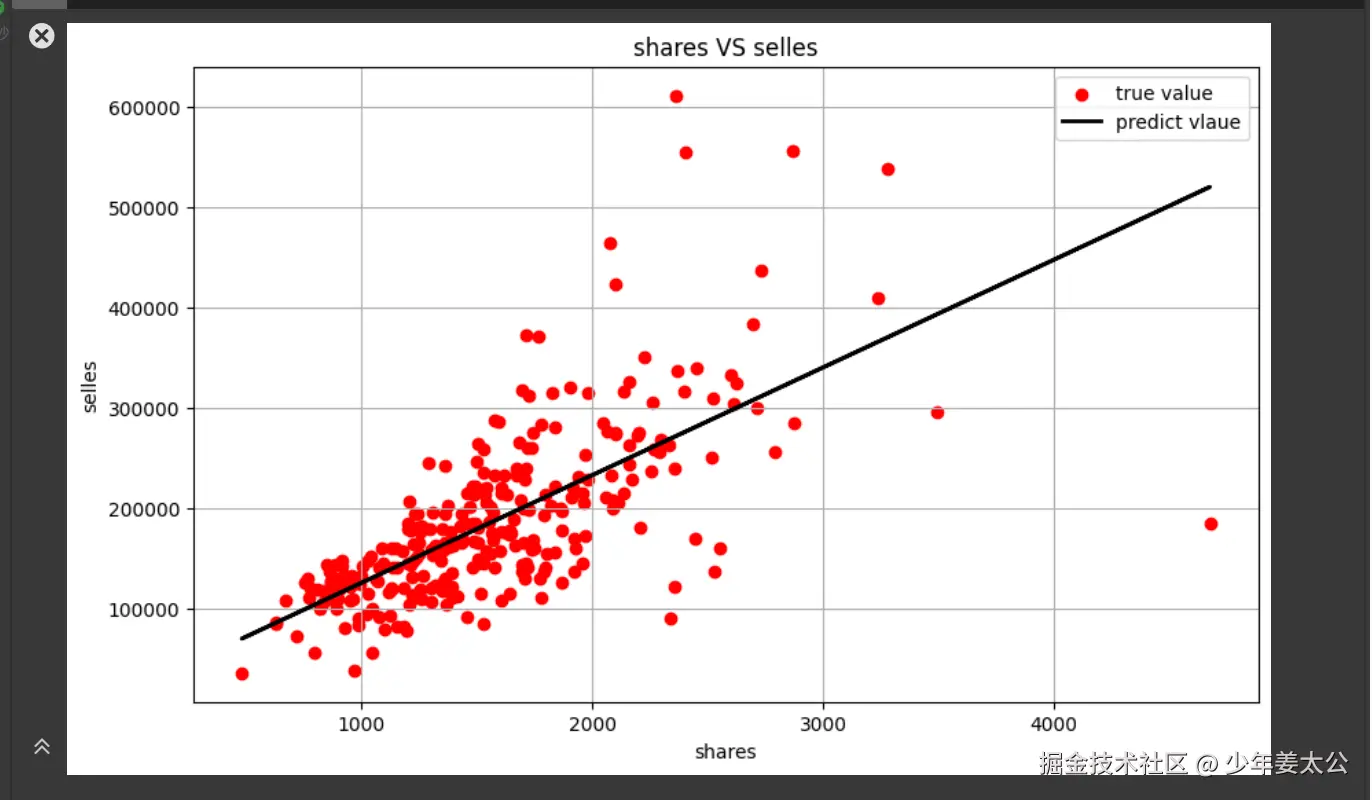
可视化预测结果
为了让预测结果更加直观,我们将真实值与预测值绘制成图表进行比较。我们使用plt.show()来显示图表。
X = df_ads[['转发量']]
X.head()
y=df_ads.成交额
y.head()
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state =0)
model = LinearRegression()
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
# 画布大小是10x6
plt.figure(figsize=(10,6))
# 散点图
plt.scatter(X_test,y_test,color='red',label="true value")
plt.plot(X_test,y_pred,color='black',linewidth=2,label="predict vlaue")
plt.xlabel("shares")
plt.ylabel("selles")
plt.title("shares VS selles")
plt.legend()
plt.grid(True)
plt.show()
总结
总结通过上述步骤,我们完成了从数据加载、可视化、预处理、模型训练到预测结果展示和评估的一整套流程。这个过程不仅帮助我们理解了直播带货中转发量与成交额之间的关系,也为我们提供了实际操作的经验,使得我们可以更好地应用机器学习技术于实践中。
这些步骤共同构成了一个完整的数据分析和建模流程,通过它们,我们可以有效地进行直播带货的效果预测,并不断优化模型以提高预测准确性
如果本文对你有些许帮助的话,点个免费的赞,并帮我投两票吧。/rank/2024/w…




