
- 作者:老汪软件技巧
- 发表时间:2024-12-19 17:03
- 浏览量:
今年是人工智能发展的又一个疯狂之年。回顾这一年的最佳方式,就是阅读 2024 年引用次数最多的 10 篇人工智能研究论文,这将帮助我们洞悉该领域的发展方向。
作为最受欢迎的论文托管平台,arXiv 已收录了绝大多数重要研究。为了方便统计,我们将直接参考 arXiv 的数据,来一窥人工智能领域的增长速度。
让我们来揭晓榜单吧!
第10名Deepseek-code
Deepseek-coder[1]是一组专为「代码智能」而设计的开源大语言模型。这篇文章最大的亮点是使用了高质量的项目级代码语料库(共计 2 万亿 tokens),训练过程完全透明。
在多个基准测试中,模型性能在「开源代码模型」中处于领先地位,甚至超越了一些闭源模型(如 Codex 和 GPT-3.5)。

第9名LLM survey
LLM survey[2]是一篇全面「综述 LLM 领域」的论文,涵盖了模型的发展现状、核心技术和未来方向。因此,如果你想了解 LLM 的一些主要概念,那么这篇论文将是很好的起点。
第8名KAN
KAN[3]是一种多层感知机(MLP)的创新替代方案。但这是一篇颇具争议的论文,因为显然 Baseline 没有经过适当的训练。所以人们对它的实际表现十分怀疑。但他是 2024年最受欢迎的新型架构。
第7名 阿里巴巴 Qwen2
这是一篇Qwen[4]模型系列的技术报告论文,该论文介绍了阿里巴巴9月份发布的一系列大语言模型和多模态模型,涵盖从 0.5 亿到 720 亿参数的密集模型和专家混合模型。
它的亮点在于其强大的性能表现、多语言能力,以及开源和可扩展性。

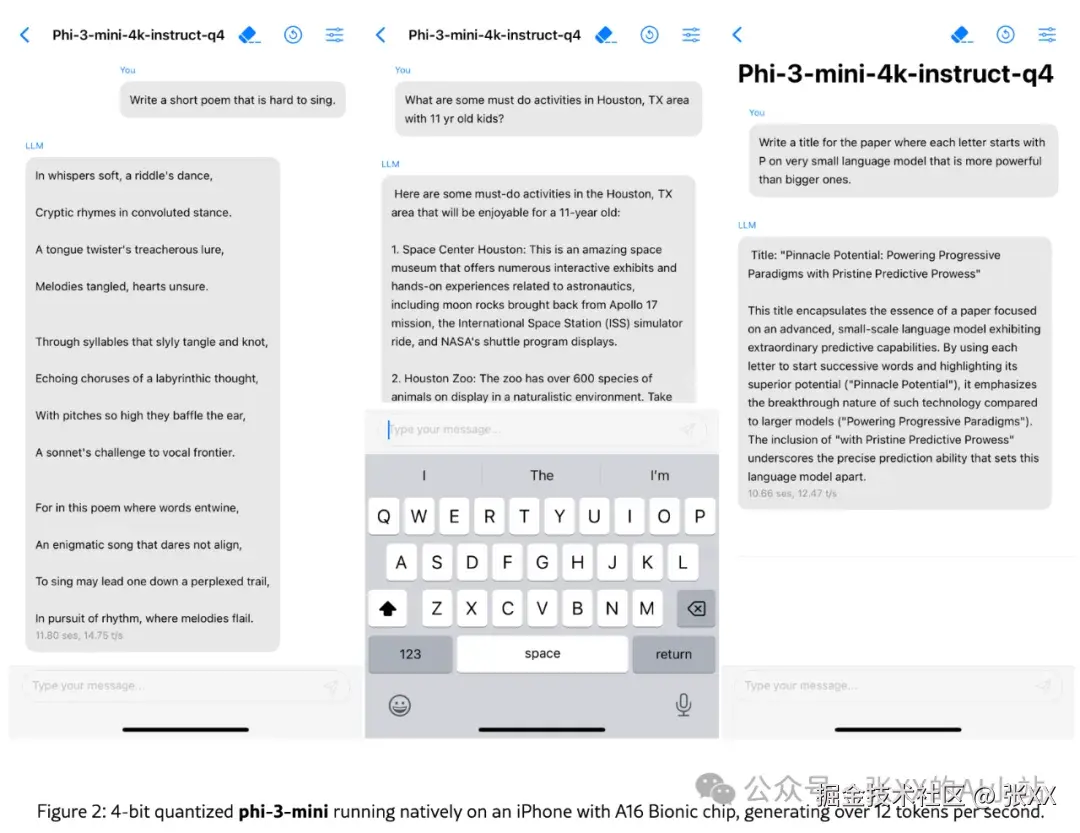
第6名 微软 Phi-3
微软发表的 53篇技术报告,他们有一些关于如何「训练超小但功能强大」的模型的见解。

其中的代表就是可以在手机上运行的phi-3-mini[5]。
第5名谷歌 Gemini 1.5
谷歌的 Gemini 1.5[6]的亮点在于其「超大的上下文长度」和极快的生成速度,它采用了新颖架构,可以容纳 1000万个 token, 其容量之大令人震惊。

第4名VisionMamba
VisionMamba[7]通过引入双向状态空间模型,显著提升了高分辨率图像处理的效率与性能,为视觉表示学习开辟了新的方向,极具研究与应用价值。
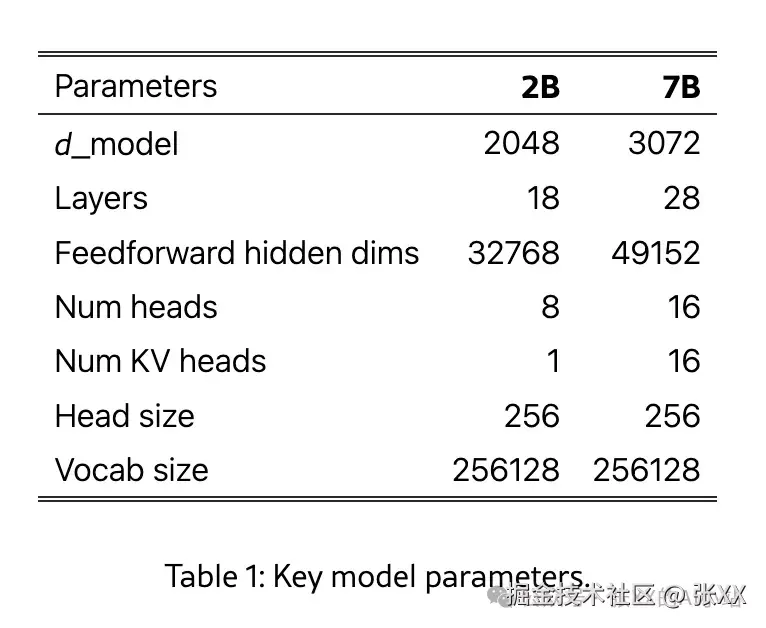
第3名 谷歌Gemma
谷歌 Gemma[8]源自他们的 Gemini模型,是一种「轻量级开源模型」。它提供两种规模的模型(2 亿参数和 7 亿参数),同时发布了预训练和微调的检查点。重点关注「人工智能安全」。
第2名MoE
MoE(Mixture of Experts Layer)[9]虽然不是最新的技术,但在数学、代码和多语言任务中表现突出,是前沿稀疏模型的典范。
第1名 Meta Llama-3
Meta 的 LIama 3 Herd of Model[10],这篇长达92页的巨作就像是训练大语言模型的圣经,用元语言逐字逐句地分享如何训练最先进的 450B参数模型。
在这篇论文中,你将确切的了解它们是如何优化硬件的,如何全面的进行预训练和其他超大规模的实验。
他们在论文中唯一跳过的是他们的「精确训练数据组合」。所以除了这个,你确实有确切的蓝图来制作出最先进的模型。

关于我



