
- 作者:老汪软件技巧
- 发表时间:2024-12-16 15:03
- 浏览量:
公共资源速递
5 个数据集:
3 个教程:
访问官网立即使用:
公共数据集
1. AlphaFold3 依赖数据库
该数据库是 AlphaFold 3 依赖的大量蛋白质和 RNA 数据库,包括 BFD small、MGnify、PDB、PDB seqres、UniProt、UniRef90、NT、RFam 和 RNACentral 这 9 个数据库。
直接使用:
/EUS8K
2. BIPED 边缘检测数据集
该数据集包含了 250 张户外高清图像,每张图像的分辨率均为 1280×720 像素。这些图像被分为训练集和测试集,其中 200 张用于训练,50 张用于测试,以便于研究人员能够评估和比较不同的边缘检测算法。
直接使用:
/NIPdb

数据集示例
3. BC-Z 机器人学习数据集
BC-Z 数据集包含了超过 25,877 个不同的操作任务场景,涵盖了 100 种多样化的操作任务。这些任务通过专家级的远程操作和共享自主过程来收集,涉及 12 个机器人和 7 名不同的操作员,累计了 125 小时的机器人操作时间。
直接使用:
/Lu9lY

数据集示例
4. DS-1000 代码生成基准数据集
该数据集包含了 1k 个源自 StackOverflow 的实际数据科学问题,覆盖了 Python 中 7 个广泛使用的数据科学库,如 NumPy、 Pandas、 TensorFlow 等。这些问题不仅反映了现实世界中的多样化和实用性,还通过多标准自动评估方法确保了解决方案的可靠性和正确性。
直接使用:
/QzFex
5. QAngaroo 多步骤推理阅读理解数据集
该数据集包含两个部分:WikiHop 和 MedHop,旨在构建能够执行多跳推理的阅读理解方法,即在不同文档中分散的事实需要通过多个步骤的推理来得出新的事实。
直接使用:
/h29ra

WikiHop 数据集
公共教程
1. F5-E2 TTS:只需 3 秒克降任何音色
F5-TTS 是一款高性能文本到语音 (TTS) 系统,它基于流匹配的非自回归生成方法,结合了扩散变换器 (DiT) 技术。这一系统能够在没有额外监督的情况下,通过零样本学习快速生成自然、流畅且忠实于原文的语音。
该教程包含了两个模型的 Demo 使用,分别为 F5-TTS 和 E2 TTS,只需按照示例步骤运行,即可体验音色克隆。
在线运行:
/mHwDT
效果示例
2. OmniGen:统一图像生成 Demo
OmniGen 是一个统一的图像生成模型。它能够在单一框架内处理多种图像生成任务,包括文本到图像的生成、图像编辑、主题驱动生成和视觉条件生成等。OmniGen 的架构简化,不需要额外的文本编码器,让用户可以用指令完成复杂任务,无需额外的预处理步骤,简化了图像生成的工作流程。
相关模型和依赖已经部署完毕,一键启动进入 API 地址即可体验模型。
在线运行:
/5D2cN
效果示例
3. IC-Lightv2:AI 打光操控升级 Demo
IC-Light 能够通过 AI 技术精确控制图像中的光照效果,旨在通过机器学习模型实现图像重新照明的项目。
该教程为 IC-Light v2 升级版,按照教程步骤即可一键启动模型,体验 AI 操控灯光。
在线运行:
/dwuiX
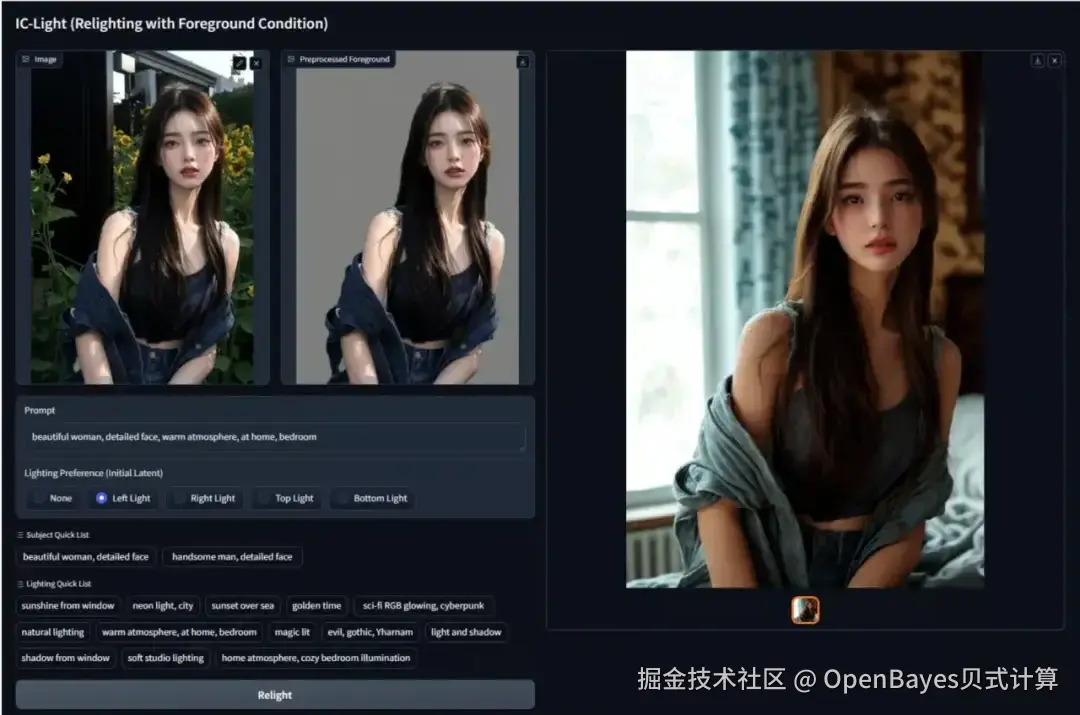
效果示例



