
- 作者:老汪软件技巧
- 发表时间:2024-12-12 17:02
- 浏览量:
作为一款流行的事务型数据库,PostgreSQL 在满足分析需求,特别是实时分析方面存在不足。为了解决这个问题,Postgres 用户可以利用变更数据捕获(CDC)将数据传递到数据仓库或者数据湖,从而实现实时分析。这种方式能够保证数据仓库或数据湖中始终有最新的数据,据此用户可以进行实时分析、机器学习或商业决策。因为该方法靠增量数据加载来实现,可减少批处理方式带来的延迟和开销,并最终实现更快得到数据分析结果,提高运营效率,增强客户体验。
本文将指导您如何通过变更数据捕获(CDC)搭建一个流式数据处理管道,将 Postgres 变更数据实时传输到 Apache Iceberg。在 RisingWave 中,完成这一任务只需几条 SQL 命令和简单设置,不必搭建复杂系统。
1. 传统典型架构
传统从 Postgres 到 Iceberg 捕获和同步数据库数据变化通常涉及多个系统,包括 Debezium、Kafka、Kafka Connect 和 Flink。
这些组件协同工作,以捕获、转换并加载数据到 Iceberg。Kafka Connect 或者Flink 负责将数据转换和输出到 Iceberg。部署、配置和管理 Debezium、Kafka、Kafka Connect(或 Flink)这一套系统较为复杂,让人望而生畏。
2. 使用 RisingWave 简化架构
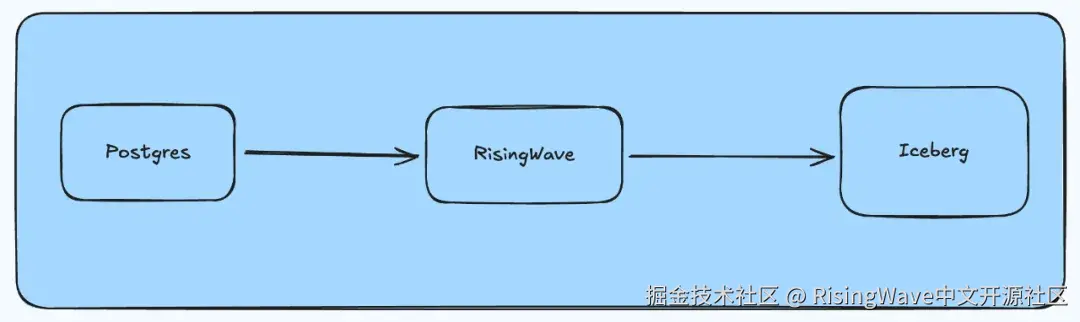
相较之下,RisingWave 简化了整个流程。RisingWave 提供原生的 Postgres Source和 Iceberg Sink 连接器。开发人员只需 RisingWave 就能搭建从 Postgres 到 Iceberg 的数据管道。
如果使用 RisingWave Cloud,搭建这样一个流处理数据管道的工作则可以进一步简化,最快只需几分钟。
2.1 配置 Postgres
要在 Postgres 上启用 CDC,需要将wal_level配置为logical,并分配必要的角色和权限。详情请参见设置 PostgreSQL。
作为示例,我们首先在 Postgres 中创建一个表,并插入一些示例数据。
-- PostgreSQL 表
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER NOT NULL,
order_status VARCHAR(20) NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入示例数据
INSERT INTO orders (customer_id, order_status, total_amount) VALUES
(101, 'pending', 299.99),
(102, 'processing', 1250.50),
(101, 'shipped', 89.99),
(103, 'delivered', 499.99),
(102, 'cancelled', 750.00);
2.2 在 RisingWave 中设置数据摄取
我们可以注册一个RisingWave Cloud账号并免费创建、启动一个集群,整个过程只需几分钟。在 RisingWave 集群中, 我们需要创建 Source 和表,该 Source 负责建立与 Postgres 实例的连接,而该表负责接收 Postgres 中对应表的数据。对于同一个 Postgres 数据库,RisingWave 支持创建多个表,这实质上是搭建了多个 CDC 数据管道,可以实现将多个 Postgres 表流式传输到多个下游系统。
CREATE SOURCE pg_cdc_source WITH (
connector = 'postgres-cdc',
hostname = '127.0.0.1',
port = '8306',
username = 'root',
password = '123456',
database.name = 'mydb',
slot.name = 'mydb_slot'
);
CREATE TABLE orders_rw (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
order_status VARCHAR,
total_amount DECIMAL,
last_updated TIMESTAMP
)
FROM source pg_cdc_source TABLE orders;
2.3 配置 Sink connector
为了将数据流式传输到 Iceberg,我们将利用 RisingWave 的原生 Iceberg connector。在 RisingWave 中,Sink 是一种可以持续输出数据到指定目标的流式任务(streaming job)。输出的数据可以是 RisingWave 中已经定义的表或物化视图,也可以是一个查询语句。
以下示例是一个CREATE SINK语句,这个语句从orders表中聚合数据,输出到 Iceberg。我们将使用 Storage Catalog 这一种 Iceberg Catalog 类型将所有元数据存储在文件系统中。此外,RisingWave 还支持其他 Catalog 类型,包括 Hive、REST、Glue 和 JDBC。
CREATE SINK orders_status_summary AS
SELECT
order_status,
COUNT(*) as order_count,
SUM(total_amount) as total_revenue,
AVG(total_amount) as avg_order_value,
MIN(last_updated) as first_order_time,
MAX(last_updated) as last_order_time
FROM orders_rw
GROUP BY order_status
WITH (
connector = 'iceberg',
type = 'append-only',
force_append_only = true,
s3.endpoint = '' ,
s3.access.key = 'access_key',
s3.secret.key = 'secret_key',
s3.region = 'ap-southeast-1',
catalog.type = 'storage',
catalog.name = 'demo',
warehouse.path = 's3://icebergdata/demo',
database.name = 's1',
table.name = 't1'
);
RisingWave 也支持直接将数据从orders_rw表输出到 Iceberg,无需任何转换。请看以下查询示例:
CREATE SINK orders_status_summary
FROM orders_rw
WITH (
connector = 'iceberg',
type = 'append-only',
force_append_only = true,
s3.endpoint = '' ,
s3.access.key = 'access_key',
s3.secret.key = 'secret_key',
s3.region = 'ap-southeast-1',
catalog.type = 'storage',
catalog.name = 'demo',
warehouse.path = 's3://icebergdata/demo',
database.name = 's1',
table.name = 't1'
);
这样就完成了 CDC 流式数据管道的搭建。搭建完成后,您可以在 Postgres 中添加、更新或删除记录,并同步检验这些更改是否成功实时传输到 Iceberg 表中。
3. 结论
通过本文示例:RisingWave 可以轻松实现 Postgres 到 Iceberg 的实时数据迁移,让实时数据分析和基于数据快速决策成为可能。RisingWave 包含众多 Source 和 Sink 连接器, 是简化数据管道搭建的理想选择。可整合来自数据库、消息队列和对象存储系统等多个数据源的数据,并将处理结果同步传输到数据仓库、数据湖和流处理平台等各种下游系统。无论是从 0 到 1 构建现代数据架构,还是在原有架构基础上进行优化迁移,RisingWave 都是可靠的解决方案。
4. 关于 RisingWave
RisingWave是一款开源的分布式流处理数据库,旨在帮助用户降低实时应用的开发成本。RisingWave 采用存算分离架构,提供 Postgres-style 使用体验,具备比 Flink 高出 10 倍的性能以及更低的成本。



