
- 作者:老汪软件技巧
- 发表时间:2024-12-07 17:03
- 浏览量:
自监督学习与扩散模型的结合-提升生成模型的效果
生成模型近年来取得了令人瞩目的进展,尤其是在图像生成、文本生成等领域。然而,传统生成模型(如GAN、VAE等)在生成质量和多样性方面仍存在不足。自监督学习(Self-Supervised Learning, SSL)与扩散模型(Diffusion Models)的结合为生成模型提供了一种新范式,能够显著提升其效果。本文将深入探讨这种结合的理论基础、应用场景,并通过代码实例展示其实际实现。
一、理论基础1.1 自监督学习概述
自监督学习是一种利用未标注数据进行学习的方式。其核心思想是设计预定义任务(如预测图像遮挡部分),让模型通过解决这些任务来学习有用的表示。自监督学习无需大量标注数据,具备良好的迁移能力。
1.1.1 优势1.2 扩散模型的原理
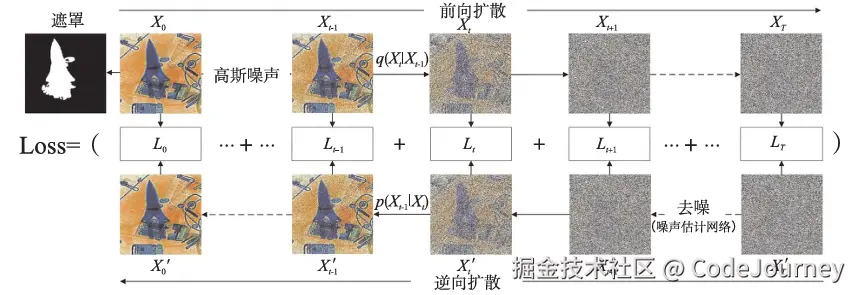
扩散模型是一种基于概率的生成模型,其核心思想是通过一系列噪声注入和还原的过程来生成数据。其训练过程包括两个阶段:
1.2.1 数学公式
扩散模型以马尔可夫链为基础,正向扩散过程为:
q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I),q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1}, (1-\alpha_t)\mathbf{I}), q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I),
其中,αt\alpha_tαt 是噪声添加的步长。逆向过程通过神经网络预测数据分布:
p(xt−1∣xt)=N(xt−1;μθ(xt,t),σθ(xt,t)).p(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \sigma_\theta(x_t, t)). p(xt−1∣xt)=N(xt−1;μθ(xt,t),σθ(xt,t)).
1.3 自监督学习与扩散模型的结合
将自监督学习融入扩散模型的关键在于设计合适的自监督任务,帮助扩散模型学习更优的去噪表示。具体思路包括:
二、实际应用场景2.1 图像生成
在图像生成任务中,使用自监督学习的特征作为扩散模型的输入,可以显著提升生成图像的清晰度与多样性。
2.2 文本生成
通过对文本进行自监督预训练(如掩码语言模型任务),扩散模型在生成文本时能够更准确地捕捉上下文信息。
2.3 多模态生成
自监督学习适用于图像-文本对齐等多模态任务,结合扩散模型后可以实现高质量的多模态生成。
三、代码实例:图像生成
数据集

以下代码演示如何结合自监督学习与扩散模型进行图像生成。
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.models import resnet18
from diffusers import DDPMScheduler, UNet2DModel
# 1. 定义自监督学习模型(如ResNet)
class SelfSupervisedResNet(nn.Module):
def __init__(self):
super().__init__()
self.resnet = resnet18(pretrained=False)
self.projector = nn.Linear(512, 128) # 投影层用于自监督任务
def forward(self, x):
features = self.resnet(x)
projections = self.projector(features)
return projections
# 2. 加载扩散模型
def get_diffusion_model():
model = UNet2DModel.from_pretrained("google/ddpm-cifar10-32")
scheduler = DDPMScheduler(num_train_timesteps=1000, beta_start=0.0001, beta_end=0.02)
return model, scheduler
# 3. 结合自监督学习与扩散模型
class CombinedModel(nn.Module):
def __init__(self, ssl_model, diffusion_model):
super().__init__()
self.ssl_model = ssl_model
self.diffusion_model = diffusion_model
def forward(self, noisy_image, t):
ssl_features = self.ssl_model(noisy_image)
denoised_image = self.diffusion_model(noisy_image, t, ssl_features)
return denoised_image
# 4. 训练流程
def train_combined_model():
ssl_model = SelfSupervisedResNet()
diffusion_model, scheduler = get_diffusion_model()
combined_model = CombinedModel(ssl_model, diffusion_model)
optimizer = torch.optim.Adam(combined_model.parameters(), lr=1e-4)
for epoch in range(10):
for noisy_image, clean_image in dataloader: # 示例数据加载器
noisy_image, clean_image = noisy_image.cuda(), clean_image.cuda()
t = torch.randint(0, 1000, (noisy_image.size(0),)).cuda()
# 正向传播
denoised_image = combined_model(noisy_image, t)
loss = nn.MSELoss()(denoised_image, clean_image)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
# 调用训练函数
train_combined_model()
四、深度分析4.1 效果提升的关键自监督特征的引入:帮助扩散模型在逆扩散过程中更准确地还原数据分布。多任务学习:自监督任务与扩散模型训练协同优化。4.2 局限性与改进方向五、模型优化策略
尽管结合了自监督学习和扩散模型的生成框架在理论上具备优势,但其实际效果往往依赖于模型优化策略的选择。本节将详细探讨几种优化方法,以进一步提升模型的性能。
5.1 自监督任务的优化5.1.1 预训练任务设计
不同的自监督任务对模型性能的影响显著。以下是两种常见的任务:
代码示例:对比学习的简单实现:
import torch.nn.functional as F
def contrastive_loss(features, labels, temperature=0.5):
# 计算对比学习的相似性矩阵
similarity_matrix = F.cosine_similarity(features.unsqueeze(1), features.unsqueeze(0), dim=2)
labels = labels.unsqueeze(1) == labels.unsqueeze(0)
# 计算正样本和负样本的对数概率
positive_similarity = similarity_matrix[labels]
negative_similarity = similarity_matrix[~labels]
positive_loss = -torch.log(torch.exp(positive_similarity / temperature).mean())
negative_loss = -torch.log(1 - torch.exp(negative_similarity / temperature).mean())
return positive_loss + negative_loss
5.1.2 数据增强策略
数据增强能够显著提高自监督特征的泛化能力。常用方法包括:
5.2 扩散过程的改进5.2.1 噪声调度策略
传统扩散模型使用线性噪声调度策略,可能在高噪声或低噪声阶段引入不必要的复杂性。改进策略包括:
代码示例:余弦调度实现:
import numpy as np
def cosine_schedule(timesteps, s=0.008):
# 返回余弦形式的噪声衰减
return np.cos(((timesteps / 1000) + s) / (1 + s) * np.pi / 2) ** 2
5.2.2 特征引导机制
将自监督学习的特征作为额外指导信号,可以进一步优化扩散模型的去噪过程。例如:
代码示例:特征引导过程:
class GuidedDiffusionModel(nn.Module):
def __init__(self, diffusion_model, guidance_features):
super().__init__()
self.diffusion_model = diffusion_model
self.guidance_features = guidance_features # 自监督特征
def forward(self, noisy_image, t):
guided_input = torch.cat([noisy_image, self.guidance_features], dim=1)
return self.diffusion_model(guided_input, t)
5.3 多任务学习
通过联合训练不同任务(如自监督学习与扩散建模任务),可以实现特征共享,提升生成性能。关键点在于设计合理的损失函数以平衡各任务的权重。
5.3.1 多任务损失函数
设计多任务学习的损失函数时,需要同时考虑:
代码示例:
def combined_loss(ssl_loss, diffusion_loss, alpha=0.5):
return alpha * ssl_loss + (1 - alpha) * diffusion_loss
5.3.2 权重动态调整
通过动态调整任务权重,可以适应不同阶段的训练需求。例如,在初期更多关注自监督任务,在后期加大对扩散模型的优化力度。
六、扩展应用与前景6.1 高分辨率图像生成
传统扩散模型生成高分辨率图像时,通常面临计算成本高的问题。通过结合自监督学习,扩散模型可以更高效地生成高分辨率样本,减少训练迭代次数。
方法探索
6.2 多模态生成任务
自监督学习天然适用于多模态任务,通过在图像-文本配对上进行训练,扩散模型可以实现更具一致性的多模态生成。
应用场景
代码示例:结合自监督特征的多模态生成:
class MultimodalDiffusionModel(nn.Module):
def __init__(self, text_features, image_features, diffusion_model):
super().__init__()
self.text_features = text_features
self.image_features = image_features
self.diffusion_model = diffusion_model
def forward(self, input_text, noisy_image, t):
combined_features = torch.cat([self.text_features(input_text), self.image_features(noisy_image)], dim=1)
return self.diffusion_model(combined_features, t)
6.3 强化学习的引入
强化学习可进一步提升自监督学习与扩散模型的结合效率。例如,通过奖励信号优化扩散模型的生成质量或多样性。
思路七、总结
自监督学习与扩散模型的结合为生成模型的发展提供了一种新思路。自监督学习的特征提取能力与扩散模型的生成机制形成互补,能够显著提升生成效果。在本文中,我们从理论背景、结合方法到具体优化策略,全面分析了这种融合的潜力和技术实现。
通过设计特定的自监督任务、自适应扩散过程、特征引导机制,以及多任务学习框架,生成模型在性能上取得了显著提升。具体优化方法包括对比学习与预测任务的创新应用、噪声调度策略的改进以及多模态特征的整合。在代码实现层面,我们演示了从自监督特征引导扩散模型到多任务损失权重调整的核心技术,提供了实践参考。
此外,文章探讨了融合模型在高分辨率图像生成、多模态生成任务以及强化学习引入等方面的潜力,这些方向为未来的研究和应用打开了新的窗口。



