
- 作者:老汪软件技巧
- 发表时间:2024-12-07 07:04
- 浏览量:151
用于文本到图像生成的扩散模型-跨模态生成技术的深入解析
文本到图像生成(Text-to-Image Generation)是人工智能领域的重要任务之一,其目标是根据输入的自然语言描述生成匹配的图像。扩散模型(Diffusion Models)作为一种新兴的生成技术,正逐步取代传统生成方法,成为跨模态生成技术的核心。本文将深入解析扩散模型在文本到图像生成中的原理、关键技术,以及应用实例,并通过代码实例帮助读者更好地理解这项技术。
扩散模型简介
扩散模型的核心思想是通过逐步添加噪声来扰乱数据,然后通过反向过程逐步去噪还原原始数据。它具有以下特点:
生成质量高:生成的图像更加细腻、逼真。稳定性强:相较于生成对抗网络(GAN),训练过程更加稳定。多模态适应性强:适合文本到图像等复杂跨模态生成任务。
扩散模型的应用范围广泛,包括图像生成、图像修复和多模态生成等。
文本到图像生成的核心技术
文本到图像生成需要解决如何将语言信息有效地转化为视觉信息。扩散模型通过以下关键技术实现这一目标:
1. 文本编码
将输入文本转化为高维向量表示,常用预训练的自然语言模型(如BERT、CLIP)来获取文本特征。
2. 噪声调控
在训练过程中,将图像逐步添加噪声,并结合文本特征指导反向去噪的过程,使生成图像与输入文本匹配。
3. 跨模态融合
通过跨模态注意力机制(Cross-Attention)将文本特征嵌入到扩散过程中的各个阶段,实现语言和视觉信息的有效结合。
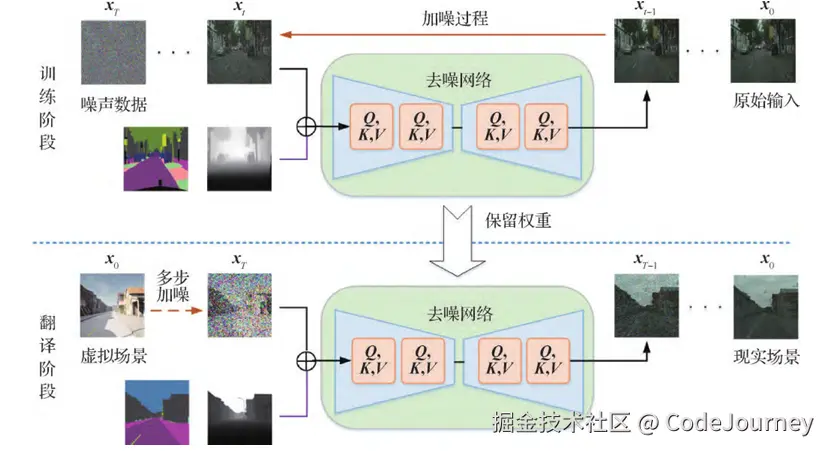
扩散模型的文本到图像生成代码实例
以下是一个基于diffusers库实现文本到图像生成的简单示例。
环境准备
首先,确保安装必要的依赖库:
pip install diffusers transformers torch
模型加载与文本生成
使用预训练的扩散模型(如Stable Diffusion)进行文本到图像生成:
from diffusers import StableDiffusionPipeline
# 加载预训练的Stable Diffusion模型
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to("cuda")
# 输入文本描述
prompt = "A futuristic cityscape at sunset with flying cars"
# 生成图像
image = pipeline(prompt).images[0]
# 保存生成结果
image.save("generated_image.png")
print("图像生成完成,已保存为 generated_image.png")
结果分析
运行上述代码后,可以生成一张符合描述的未来城市风景图。此过程充分体现了扩散模型将文本特征融入图像生成过程的能力。
扩展与优化1. 提升生成质量
可以通过调整采样步骤(如减少噪声加入的次数)和引入更复杂的文本编码模型来进一步提升生成质量。
2. 支持定制化生成
为生成结果加入条件约束,如特定的艺术风格或颜色主题。例如:
prompt = "A portrait of a woman in Van Gogh's painting style"
3. 多模态融合的未来
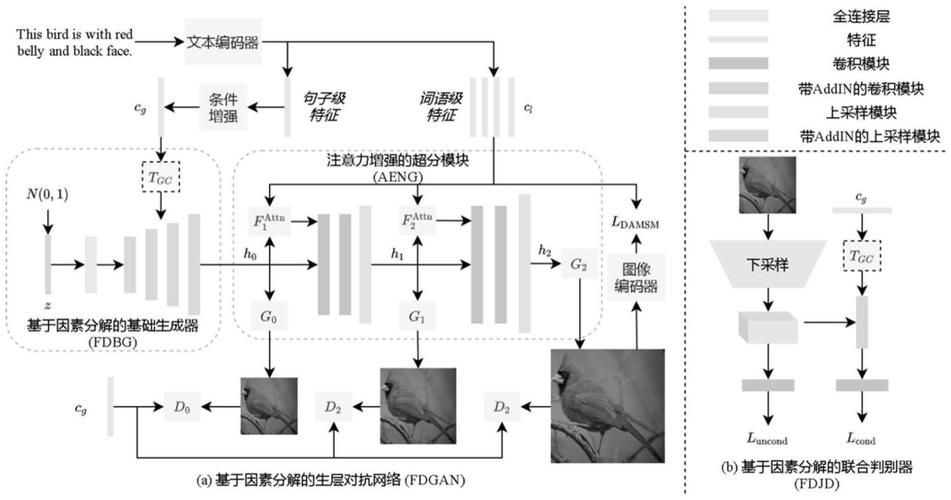
结合语音描述、动作捕捉等信息,进一步拓展跨模态生成的边界。
扩散模型的技术细节解析1. 逐步去噪的过程
扩散模型生成图像的过程被称为“去噪”。这一过程由多步组成,每一步都通过一个训练好的去噪网络减少数据中的噪声。对于文本到图像生成任务,去噪过程中还需要参考文本的嵌入信息,从而在每一步的生成中保持与输入文本的语义一致。
实现去噪的关键
去噪网络的设计通常需要注意以下几点:
2. 文本嵌入与跨模态映射
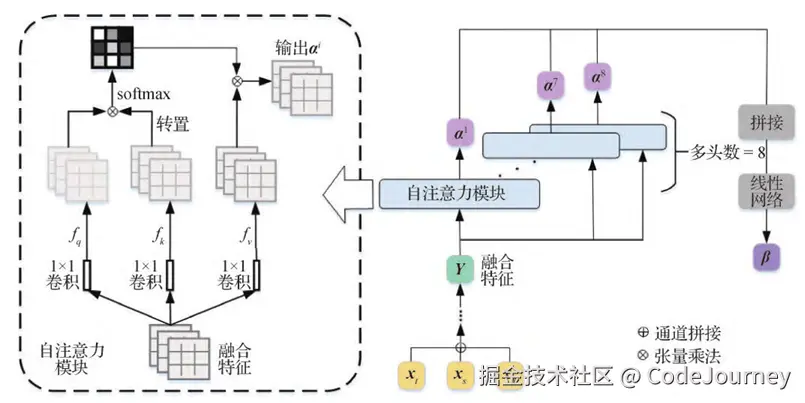
文本到图像生成的核心是将语言特征转化为视觉信息。以下技术在实现这一目标中起到了关键作用:
文本嵌入技术跨模态映射深入探索跨模态生成的应用场景
扩散模型的跨模态生成能力正在多个领域展现其潜力。
1. 游戏与虚拟世界
生成游戏背景、角色模型和虚拟场景。在该场景下,用户仅需输入简单的描述,就能生成高质量的游戏资产。例如:
prompt = "A medieval knight with glowing armor, standing in a dark forest"
2. 艺术创作
帮助艺术家快速生成灵感草图或艺术风格的作品。例如,通过输入“Van Gogh-style sunset over a calm lake”,可以生成梵高风格的日落图像。
3. 教育与科研
在教育和科研领域,扩散模型可用于生成解释性图像或模拟实验场景,从而提升教学效果和科研效率。
高级应用与优化1. 多语言支持
通过使用多语言预训练模型(如mT5或XLM-R),扩散模型可以支持多语言文本到图像生成,进一步扩大其适用范围。
2. 可控生成
在实际应用中,用户可能希望对生成的图像进行更细粒度的控制。以下是一些常见的可控生成技术:
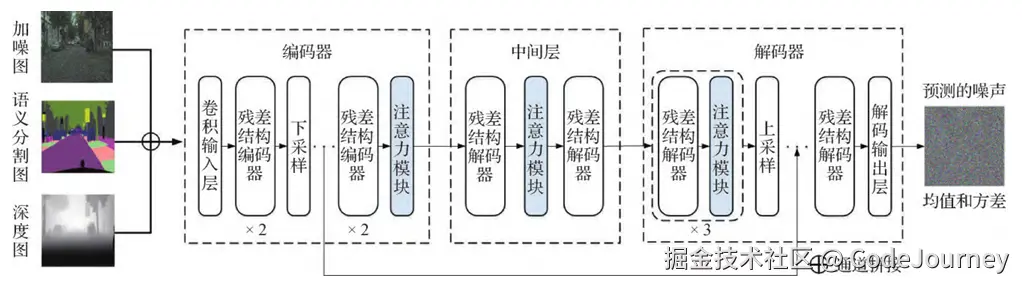
3. 多模态融合
结合其他模态信息(如语音、触觉数据),扩散模型可以生成更复杂的内容。例如,通过输入文本和语音描述生成视频片段。
代码示例:可控生成
# 输入复杂描述
prompt = "A futuristic robot with neon lights, standing in front of a glowing cityscape at night"
# 添加条件约束
pipeline.scheduler.num_inference_steps = 50 # 增加生成步数以提升细节
pipeline.scheduler.guidance_scale = 7.5 # 调整文本指导强度
# 生成图像
image = pipeline(prompt).images[0]
image.save("controlled_image.png")
展望与挑战
扩散模型的跨模态生成技术展现了巨大的潜力,但仍有挑战需要克服:
计算资源需求高:生成过程耗时且需要强大的硬件支持。描述与图像一致性:确保复杂文本描述与生成图像的精准匹配。可控性不足:难以直接控制生成细节。
未来,随着模型架构优化与硬件性能的提升,扩散模型将在文本到图像生成领域发挥更大的作用。
总结
扩散模型为文本到图像生成提供了一种全新的解决方案,其强大的生成能力和灵活性为跨模态生成任务打开了新的可能性。从理论到实践,本文不仅解析了其工作原理,还提供了可操作的代码实例,为相关技术研究和应用奠定了基础。通过进一步探索与优化,扩散模型将在人工智能生成领域释放更大的潜力。



