
- 作者:老汪软件技巧
- 发表时间:2024-11-29 15:05
- 浏览量:
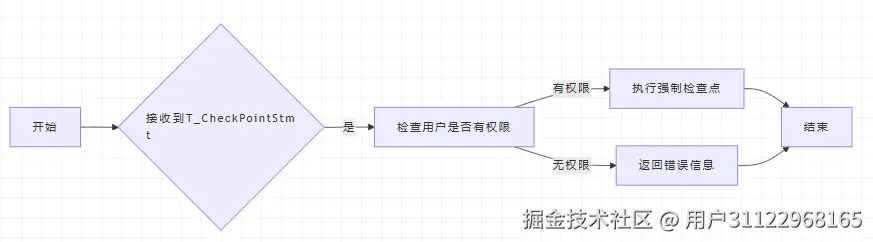
standard_ProcessUtility()函数中CheckPoint语句执行过程概述
在 PostgreSQL 中,T_CheckPointStmt 标签与执行检查点(checkpoint)操作相关。 CHECKPOINT 命令会强制数据库进行一次检查点操作,这个操作会更新所有数据文件,以确保事务日志中的信息被刷新到磁盘上,保证数据的持久性。
T_CheckPointStmt标签执行过程:T_CheckPointStmt标签的代码实现:
case T_CheckPointStmt:
if (!has_privs_of_role(GetUserId(), ROLE_PG_CHECKPOINT))
ereport(ERROR,
(errcode(ERRCODE_INSUFFICIENT_PRIVILEGE),
errmsg("must be superuser or have privileges of pg_checkpoint to do CHECKPOINT")));
RequestCheckpoint(CHECKPOINT_IMMEDIATE | CHECKPOINT_WAIT |
(RecoveryInProgress() ? 0 : CHECKPOINT_FORCE));
break;
CheckPoint语句的执行过程:
has_privs_of_role()函数的执行过程:直接检查两个传入参数是否相等,如果相等就表示当前user拥有执行checkpoint权限。
/* Fast path for simple case */
if (member == role)
return true;
调用superuser_arg()函数检查当前用户的权限。
/* Superusers have every privilege, so are part of every role */
if (superuser_arg(member))
return true;
superuser_arg()函数的执行过程:
这个函数通过查询 PostgreSQL 的系统表 pg_authid 来检查一个角色是否是超级用户,并且使用了缓存来提高性能。它还处理了一些特殊情况,如数据库初始化过程中的超级用户检查。
bool result;
HeapTuple rtup;
声明了一个布尔变量 result 来存储结果,以及一个 HeapTuple 类型的变量 rtup 来存储系统缓存中的元组。
if (OidIsValid(last_roleid) && last_roleid == roleid)
return last_roleid_is_super;
如果上次查询的角色 ID (last_roleid) 有效,并且与当前的角色 ID 相同,函数将直接返回上次查询的结果 (last_roleid_is_super)。
if (!IsUnderPostmaster && roleid == BOOTSTRAP_SUPERUSERID)
return true;
如果当前不在 Postmaster 进程下运行(例如,在初始化数据库或恢复过程中),并且角色 ID 是引导超级用户 ID (BOOTSTRAP_SUPERUSERID),则直接返回 true。
rtup = SearchSysCache1(AUTHOID, ObjectIdGetDatum(roleid));
使用系统缓存查询函数 SearchSysCache1 来查找 pg_authid 系统表中对应 roleid 的元组。
if (HeapTupleIsValid(rtup))
{
result = ((Form_pg_authid) GETSTRUCT(rtup))->rolsuper;
ReleaseSysCache(rtup);
}
else
{
result = false;
}
如果找到的元组有效,从元组结构体中获取 rolsuper 字段的值,并将其存储在 result 中。然后释放系统缓存中的元组。如果元组无效,设置 result 为 false。
if (!roleid_callback_registered)
{
CacheRegisterSyscacheCallback(AUTHOID,
RoleidCallback,
(Datum) 0);
roleid_callback_registered = true;
}
如果尚未注册缓存回调,使用 CacheRegisterSyscacheCallback 函数注册一个回调,以便在系统缓存发生变化时更新本地缓存。这确保了本地缓存与系统缓存的一致性。
return result;
返回 result,表示给定的角色 ID 是否是超级用户。
这个函数通过查询 PostgreSQL 的系统表 pg_authid 来检查一个角色是否是超级用户,并且使用了缓存来提高性能。它还处理了一些特殊情况,如数据库初始化过程中的超级用户检查。
RecoveryInProgress()函数的执行过程:
这个函数通过检查共享内存中的状态来确定系统是否仍在恢复模式中。如果系统不在恢复模式中,函数会立即返回false;如果系统在恢复模式中,函数会更新本地状态并返回true。
这里检查LocalRecoveryInProgress变量,如果它为false,则直接返回false,表示系统不在恢复模式中;如果LocalRecoveryInProgress为true,则执恢复过程。
if (!LocalRecoveryInProgress)
return false;
将XLogCtl全局变量的地址赋给volatile类型的指针xlogctl。这里使用volatile指针是为了确保对共享变量进行新的读取,防止优化器对其进行优化处理。
/*
* use volatile pointer to make sure we make a fresh read of the
* shared variable.
*/
volatile XLogCtlData *xlogctl = XLogCtl;
这里更新LocalRecoveryInProgress变量的状态。它检查xlogctl指向的共享内存中的SharedRecoveryState字段是否不等于RECOVERY_STATE_DONE(恢复完成状态)。如果不等于,说明恢复尚未完成,LocalRecoveryInProgress被设置为true;否则设置为false。
LocalRecoveryInProgress = (xlogctl->SharedRecoveryState != RECOVERY_STATE_DONE);
最后,函数返回LocalRecoveryInProgress的值,这个值表示系统是否仍在恢复模式中。在恢复模式中不需要内存屏障(memory barrier)。因为即使函数返回true,调用者也不能依赖这个返回值来确定系统仍在恢复模式中。
/*
* Note: We don't need a memory barrier when we're still in recovery.
* We might exit recovery immediately after return, so the caller
* can't rely on 'true' meaning that we're still in recovery anyway.
*/
return LocalRecoveryInProgress;
RequestCheckpoint()函数的执行过程:
该函数用于在后端进程中请求一个检查点(checkpoint)。检查点是数据库系统中的一个操作,用于将事务日志(WAL)中的更改刷新到磁盘上,以确保数据的持久性。下面是逐行解释该函数的源码执行过程:
声明了三个整型变量ntries、old_failed和old_started,用于记录尝试发送信号的次数,以及检查点失败和开始的次数。
int ntries;
int old_failed, old_started;
检查是否处于独立后端环境(不是由postgres的postmaster进程管理)。
/*
* If in a standalone backend, just do it ourselves.
*/
if (!IsPostmasterEnvironment)
{
/*
* There's no point in doing slow checkpoints in a standalone backend,
* because there's no other backends the checkpoint could disrupt.
*/
CreateCheckPoint(flags | CHECKPOINT_IMMEDIATE);
/*
* After any checkpoint, close all smgr files. This is so we won't
* hang onto smgr references to deleted files indefinitely.
*/
smgrcloseall();
return;
}
设置请求标志,并获取计数器的快照。
/*
* Atomically set the request flags, and take a snapshot of the counters.
* When we see ckpt_started > old_started, we know the flags we set here
* have been seen by checkpointer.
*
* Note that we OR the flags with any existing flags, to avoid overriding
* a "stronger" request by another backend. The flag senses must be
* chosen to make this work!
*/
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
old_failed = CheckpointerShmem->ckpt_failed;
old_started = CheckpointerShmem->ckpt_started;
CheckpointerShmem->ckpt_flags |= (flags | CHECKPOINT_REQUESTED);
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
定义一个循环,用于发送信号请求检查点。如果检查点进程尚未启动或正在重启,可能会需要重试。
#define MAX_SIGNAL_TRIES 600 /* max wait 60.0 sec */
for (ntries = 0;; ntries++)
检查检查点进程的PID是否为0,如果是,表示检查点进程尚未启动。并检查如果尝试次数达到最大值或者flags中没有设置CHECKPOINT_WAIT,则记录错误并退出循环。
if (CheckpointerShmem->checkpointer_pid == 0)
{
if (ntries >= MAX_SIGNAL_TRIES || !(flags & CHECKPOINT_WAIT))
{
elog((flags & CHECKPOINT_WAIT) ? ERROR : LOG,
"could not signal for checkpoint: checkpointer is not running");
break;
}
}
如果向检查点进程发送SIGINT信号失败,则检查是否达到了最大尝试次数或者flags中是否设置了CHECKPOINT_WAIT。并检查如果尝试次数达到最大值或者flags中没有设置CHECKPOINT_WAIT,则记录错误并退出循环。
else if (kill(CheckpointerShmem->checkpointer_pid, SIGINT) != 0)
{
if (ntries >= MAX_SIGNAL_TRIES || !(flags & CHECKPOINT_WAIT))
{
elog((flags & CHECKPOINT_WAIT) ? ERROR : LOG,
"could not signal for checkpoint: %m");
break;
}
}
如果信号发送成功,则退出循环。
else
break; /* signal sent successfully */
在每次循环中检查中断,并等待0.1秒后重试。
CHECK_FOR_INTERRUPTS();
pg_usleep(100000L); /* wait 0.1 sec, then retry */
如果flags中设置了CHECKPOINT_WAIT,则等待检查点完成。
/*
* If requested, wait for completion. We detect completion according to
* the algorithm given above.
*/
if (flags & CHECKPOINT_WAIT)
{
int new_started, new_failed;
/* Wait for a new checkpoint to start. */
ConditionVariablePrepareToSleep(&CheckpointerShmem->start_cv);
...
}
进入一个循环,等待检查点开始。
for (;;)
{
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
new_started = CheckpointerShmem->ckpt_started;
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
if (new_started != old_started)
break;
ConditionVariableSleep(&CheckpointerShmem->start_cv,
WAIT_EVENT_CHECKPOINT_START);
}
ConditionVariableCancelSleep();
/*
* We are waiting for ckpt_done >= new_started, in a modulo sense.
*/
ConditionVariablePrepareToSleep(&CheckpointerShmem->done_cv);
准备等待检查点完成的条件变量。
for (;;)
{
int new_done;
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
new_done = CheckpointerShmem->ckpt_done;
new_failed = CheckpointerShmem->ckpt_failed;
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
if (new_done - new_started >= 0)
break;
ConditionVariableSleep(&CheckpointerShmem->done_cv,
WAIT_EVENT_CHECKPOINT_DONE);
}
ConditionVariableCancelSleep();
如果新的失败计数与旧的不同,表示检查点请求失败,记录错误并退出函数。
if (new_failed != old_failed)
ereport(ERROR,
(errmsg("checkpoint request failed"),
errhint("Consult recent messages in the server log for details.")));
至此,完成执行检查点(checkpoint)的所有操作。



