
- 作者:老汪软件技巧
- 发表时间:2024-11-22 10:03
- 浏览量:
最近在对项目进行国际化,借此机会优化下AI项目结构。此次优化借助设计模式来满足新的需求以及历史代码优化。具体如下:
1、项目背景
AI项目主要是增加平台智能化能力(比如根据标题生成大纲、推荐热门主题等),底层逻辑是使用不同功能指定的提示词去调用大模型进行实现。
由于各厂商的大模型能力不同以及项目的客观因素,可能会存在不同租户调用不同模型(比如港澳台需要繁体,因此和大陆不会使用同一个大模型【公司有自研大模型(繁体中文能力较弱),因为成本原因,大陆优先使用公司自研大模型】)。
但也有特殊情况,比如对于复杂功能 ,公司大模型并不能实现,因此对于复杂功能也需要特定的大模型来进行处理,就是同一用户使用不同的功能也会调用不同的大模型。
2、现状2.1、现有设计不满足新需求
现在AI提示词表中提示词、模型枚举值,主要字段如下
CREATE TABLE `prompt` (
......
`func_code` varchar(64) CHARACTER DEFAULT NULL COMMENT '功能code',
`model` int(11) DEFAULT NULL COMMENT '模型枚举',
`prompt_text` text DEFAULT '' COMMENT '提示词',
......
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='功能配置';
从现有的表中可以看出,提示词和功能配置在同一表中,当切换不同的语言环境时,提示词并不能切换(有些功能的提示词需要进行页面展示),因此需要新建一张表,用于存放不同语言环境下的提示词内容。
2.2、历史代码
不同类型的功能可能会根据配置使用不同的大模型,比如基础问答可以选择模型(豆包、Kimi、公司自研大模型),对于AI绘图也可以选择不同模型(豆包、Kimi、公司自研大模型)。同样,语音解析、文档识别也是如此。
代码现状是,不同类型的功能模块在选择模型时都是使用swtich-case来实现,伪代码如下:
基础问答:
switch (model) {
case 1:
// 访问chartGPT
break;
case 2:
// 访问豆包
break;
case 3:
// 访问Kimi
break;
case 4:
.....
break;
case 5:
// 访问公司自研模型
break;
default:
// 访问公司自研模型
AI绘图:
switch (model) {
case 1:
// 访问豆包
break;
case 2:
// 访问公司自研模型
break;
default:
// 访问公司自研模型
语音解析:
switch (model) {
case 1:
// kimi
break;
case 2:
// 访问公司自研模型
break;
default:
// 访问公司自研模型
从伪代码块可以看出,不同大模型的能力分散在不同类型功能的代码中,无法快速知道某个模型目前有哪些能力。除此之外,项目中多处使用相同类型的能力时(比如两个地方都使用了AI绘图能力),多次出现相同的swtich-case代码块,极大的增加了代码的维护成本。
3、解决方案3.1、表设计
为支持国际化需求,根据不同语言环境切换不同的提示词,因此需要将语言环境和提示词放入一张新表,然后根据功能code和当前上下文的语言环境来获取提示词和模型,具体设计表如下:
提示词表:为了实现特定功能,需要增加一些隐藏提示语(比如英文环境,有些功能需要在提示词后面增加【输出结果使用英文】),而这些隐藏提示语并不能让用户看见。因此增加字段append_prompt来做隐藏。
CREATE TABLE `prompt` (
......
`language` varchar(64) DEFAULT 'zh_CN' COMMENT '语言类型:zh_CN-简体中文,zh_HK-繁体中文,en-英文',
`question_type_code` varchar(64) DEFAULT '' COMMENT '问答类型',
`prompt` text COMMENT '提示词',
`append_prompt` varchar(255) DEFAULT '' COMMENT '拼接提示词',
......
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='提示词表';
功能表:这张表我们主要存放AI功能相关信息,比如不同功能的前置处理是什么、后置处理是什么、以及简介等一些信息。
CREATE TABLE `ai_question` (
.......
`question_type_code` varchar(64) DEFAULT '' COMMENT '问答类型',
`before_handler` text DEFAULT '' COMMENT '前置处理',
`post_handler` text DEFAULT '' COMMENT '后置处理',
.......
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='ai提问表';
3.2、代码设计
代码优化的思想指导是:高内聚、低耦合。我们从这两个方面进行设计代码结构。
3.2.1、AI能力接口
我们希望AI能力相关的代码能够高内聚,我们使用ai能力时,直接调用ai接口便能够获取到相应的服务,而不是AI相关能力分散在不同接口,使用时还需要调用多个接口(比如基础聊天、语音识别、文档识别等)。因此我们设计AI接口能力如下:
public interface AiService {
// 基础问答
JsonResult<String> startAsk(AIRequest aiRequest);
// 基础问答-流式输出
void startAskStream(AIRequest aiRequest);
// AI绘图
JsonResult<String> startDraw(AIRequest aiRequest);
// AI翻译
JsonResult<String> startTranslate(AIRequest aiRequest);
// AI文档解析
JsonResult<String> startDocAnalysis(AIRequest aiRequest);
// AI语音识别
JsonResult<String> startVoiceAnalysis(AIRequest aiRequest);
}
对于能力的具体实现,我们主要分为两个步骤(也可以再加一个步骤,就是当我们请求对应服务没有返回结果或结果不理想时,我们可以加一个兜底逻辑)
public class AiServiceImpl implements AiService {
....
/**
* 基础问答-非流式输出
*/
@Override
public JsonResult<String> startAsk(AIRequest aiRequest) {
// 1、根据请求及上下文获取提示词及模型配置
// 2、根据配置获取对应的模型服务
// 3、如果调用异常或者结果不服务预期,则进行兜底调用
return null;
}
....
}
3.2.2、获取模型配置
在获取提示词、模型配置时,我们希望能跟AI能力一样,有关配置相关的逻辑更加内聚,即调用获取配置接口返回相关配置,而不是选择配置的逻辑出现在功能的业务代码中,因此,我们将两个表【prompt、ai_question】中的数据统一包装成一个配置实体类对外提供【AiAbilityConfigDTO】
public class AiAbilityConfigDTO {
....
/**
* 语言类型:zh_CN-简体中文,zh_TW-繁体中文,en-英文
*/
private String language;
/**
* 问答类型
*/
private String questionTypeCode;
/**
* 提示词
*/
private String prompt;
/**
* 隐藏拼接提示词
*/
private String appendPrompt;
/**
* 模型
*/
private Integer model;
....
}
我们在对外提供的配置接口的实现类中处理判断逻辑
public class AiAbilityConfigServiceImpl implements AiAbilityConfigService {
.....
@Override
public AiAbilityConfigDTO getAiPrompt(String questionTypeCode) {
// 1、根据 问答code+上下文语言环境 获取问答相关配置(是否指定模型等其他功能元数据)
// 2、根据上下文环境及问答相关配置设置要请求的模型(如果功能指定模型,则使用指定模型,否则使用租户配置的模型)
return aiAbilityConfigDto;
}
.....
}
获取配置相关sql如下(根据语言环境获取):
SELECT *
FROM ai_question
LEFT JOIN ai_prompts ON ai_question.question_type_code = ai_prompts.question_type_code
WHERE ai_question.question_type_code = 'code'
AND ai_prompts.language = 'language'
AND ai_prompts.status = 1
AND ai_question.status = 1
3.2.3、AI多模型
我们希望同一模型的能力能够内聚,不同模型切换能够与业务逻辑进行拆分,做到低耦合。这样的话,顶层业务逻辑只关心功能的实现,底层使用哪个模型以及模型能力的实现不应该交给业务层管理(即每个功能实现的业务逻辑代码中考虑使用哪个模型能力)。我们先定义AI大模型底层能力接口用于承接Ai能力服务接口:
public interface ModelService {
// 基础问答
ModelResultDto<String> ask(AIRequest aiRequest);
// 基础问答-流式输出
void askStream(AIRequest aiRequest, boolean isSync);
// AI绘画
ModelResultDto<String> draw(AIRequest aiRequest);
// AI翻译
ModelResultDto<String> translate(AIRequest aiRequest);
// AI文档分析
ModelResultDto<String> docAnalysis(AIRequest aiRequest);
// 语音分析
ModelResultDto<String> voiceAnalysis(AIRequest aiRequest);
}
高内聚:我们将同一模型中的不同能力写到同一个服务中,同一个模型的相关能力更加内聚。
public class DouBaoModelServiceImpl implements ModelService {
/**
* AI基础问答
*/
@Override
public ModelResultDto<String> ask(AIRequest aiRequest) {
return null;
}
/**
* AI基础问答-流式输出
*/
@Override
public void askStream(AIRequest aiRequest, boolean isSync) {
}
/**
* AI绘画
*/
@Override
public ModelResultDto<String> draw(AIRequest aiRequest) {
return null;
}
/**
* AI翻译
*/
@Override
public ModelResultDto<String> translate(AIRequest aiRequest) {
return null;
}
/**
* AI文档解析
*/
@Override
public ModelResultDto<String> docAnalysis(AIRequest aiRequest) {
return null;
}
/**
* AI语音识别
*/
@Override
public ModelResultDto<String> voiceAnalysis(AIRequest aiRequest) {
return null;
}
@Override
public ModelResultDto<String> searchWeb(AIRequest aiRequest) {
return null;
}
}
低耦合:我们使用工厂模式+策略模式来替换swtich-case。将业务功能代码中的swtich-case逻辑迁移到ModeServiceBeanFactory的getBean方法中。不同的模型都实现AI模型服务接口,在模型实现类中实现对接模型相关代码。
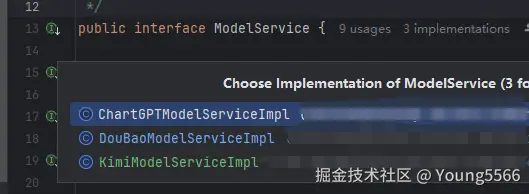
模型工厂代码如下
public class ModeServiceBeanFactory {
@Autowired
private ApplicationContext applicationContext;
@Autowired
private IAiPromptService aiPromptService;
private static final ImmutableMap MODEL_MAP = ImmutableMap.of(
1, "com.young.service.aiService.impl.DouBaoModelServiceImpl",
2, "com.young.service.aiService.impl.KimiModelServiceImpl",
3, "com.young.service.aiService.impl.ChartGPTModelServiceImpl"
);
public ModelService getBean(AIRequest aiRequest){
// 根据自定义规则获取相关模型
// 根据模型获取相关beanName
// 获取bean
return (ModelService) applicationContext.getBean(MODEL_MAP.get(aiRequest.getModel()));
}
}
至此,我们已经将AI能力封装完成,对于外部的功能实现代码,我只需要调用一个【AiService】接口便能根据请求参数或上下文环境获取到对应的提示词和模型。
3.2.4、扩展
为了应对更多的场景功能,在访问各个厂商大模型时,增加了前置处理和后置处理方法。当我们需要进行一动态调整参数或者动态处理返回结果时便可以轻松应对,再结合SpEL表达式,进一步增强前后处理器的功能。
我们将前置处理和后置处理方法放在抽象类父类中,然后各个大模型类继承抽象类在执行前后调用对应的处理器方法,处理器使用spEL表达式动态执行方法。
public class AbstractModelServiceImpl {
@Autowired
private IAiPromptService aiPromptService;
protected String beforeHandler(AIRequest aiRequest){
// 1、获取配置的前置处理器方法
// 2、执行spEL表达式
return null;
};
protected String postHandler(AIRequest aiRequest, String result){
// 1、获取配置的后置处理器方法
// 2、执行spEL表达式
return null;
};
}
大模型类使用方法如下:
public class ChartGPTModelServiceImpl extends AbstractModelServiceImpl implements ModelService {
@Override
public ModelResultDto<String> ask(AIRequest aiRequest) {
// 访问大模型前置处理
beforeHandler(aiRequest);
// 访问大模型
String text = askChatGPT(aiRequest);
// 访问大模型后置处理
postHandler(aiRequest, text);
return null;
}
}
根据以上设计思路,设计出了如下类图:
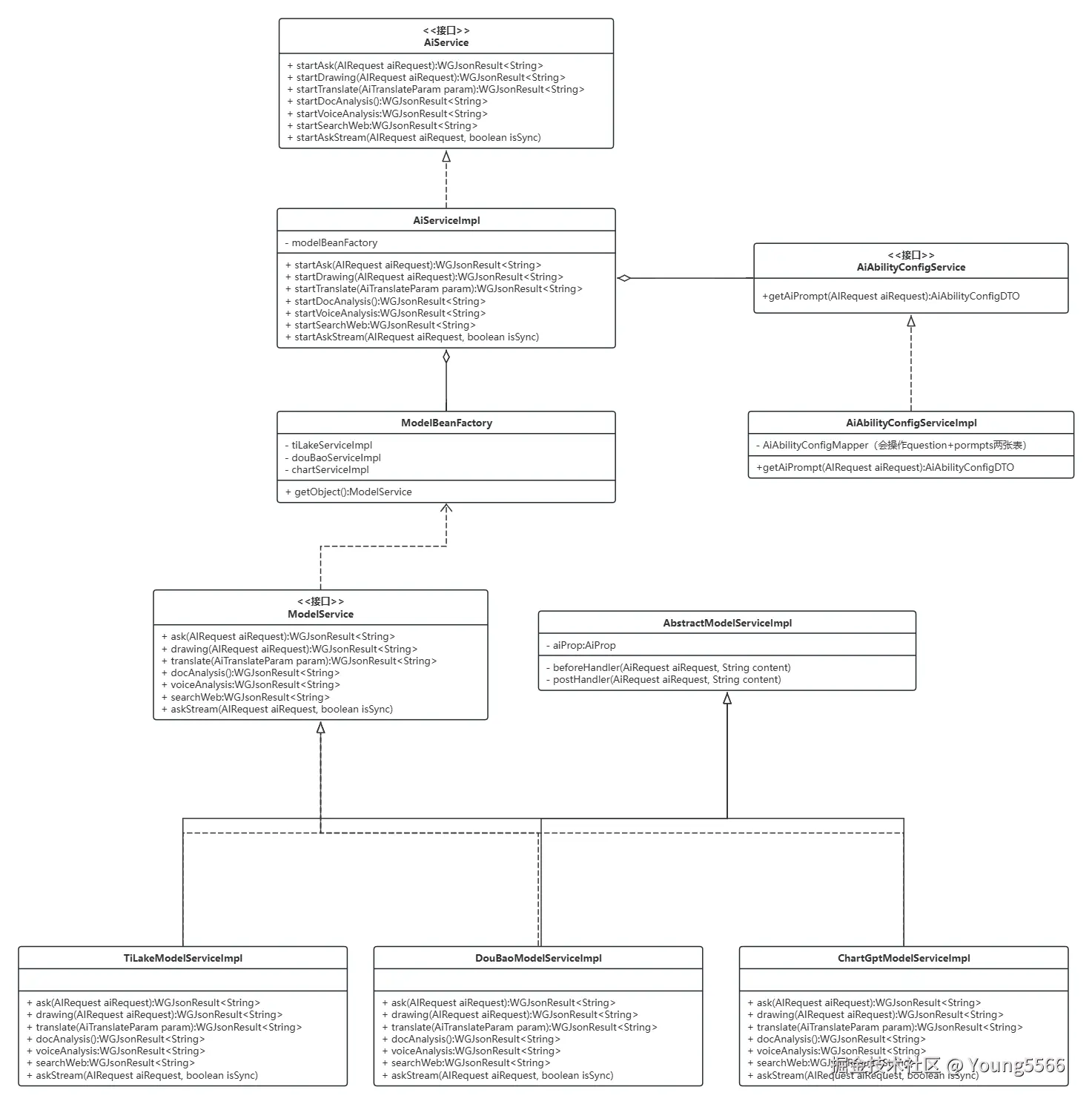
4、总结
通过这次改造,业务层使用ai能力时,直接调用【AiAbilityConfigService】接口即可,业务层不再关心具体使用哪个大模型能力,这样使得业务层的逻辑更加内聚,与模型选择的逻辑进行解耦。最终达到了我们高内聚、低耦合的目标。
我们在项目设计或优化时,除了实现功能之外,要设计出一个可维护性高、扩展性高、的项目结构,而这些指标都是建立在高内聚、低耦合的思想之上。因此,要深入理解高内聚、低耦合,多看一些组件和框架的实现思路,拓宽我们的视野,给我们的优化思路提供一些输入。
5、未来规划
其实对于ai功能来说,就是组合使用不同的ai能力(ai语音识别、文档解析、基础问答等)或者是使用不同的提示词调用多次基础问答来完成某一个功能。因此我们可以借助工作流来进行流程编排组合,这样,当我们新加ai功能时,可以设置完提示词后,进行流程编排,这样我们就不用再次发版。
后期打算将工作流引入ai相关项目,进一步增强ai的可扩展性和可维护性。



