
- 作者:老汪软件技巧
- 发表时间:2024-11-21 21:03
- 浏览量:

一、 主流多模态模型介绍
本文首先从多模态模型的基本思想、模型结构、损失设计及训练数据集情况对经典模型进行整理,太长不看版总结如下:
(1)CLIP
论文: Learning Transferable Visual Models From Natural Language Supervision
模型介绍
CLIP采用双塔结构,其核心思想是通过海量的弱监督文本对,通过对比学习,将图片和文本通过各自的预训练模型获得编码向量,通过映射到统一空间计算特征相似度,通过对角线上的标签引导编码器对齐,加速模型收敛。CLIP是一种弱对齐,可应用于图文相似度计算和文本分类等任务。
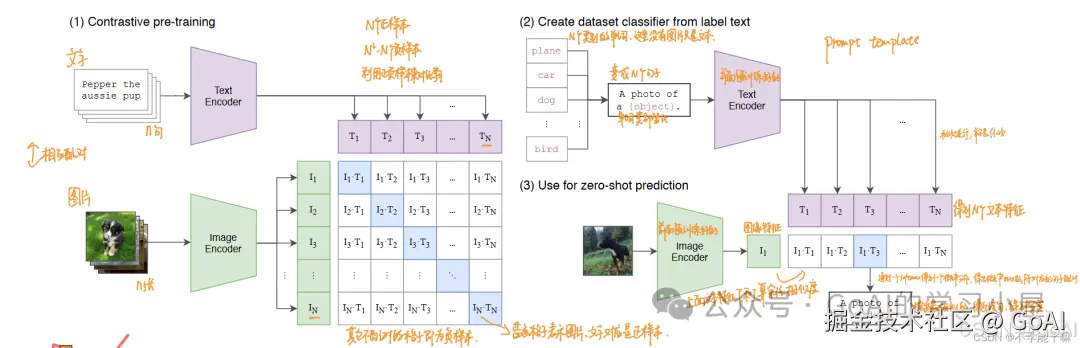
模型结构
1.图像编码器:使用的是之前文章提到的ViT网络,而且是效果比较好的ViT-L/14@336px
具体实现
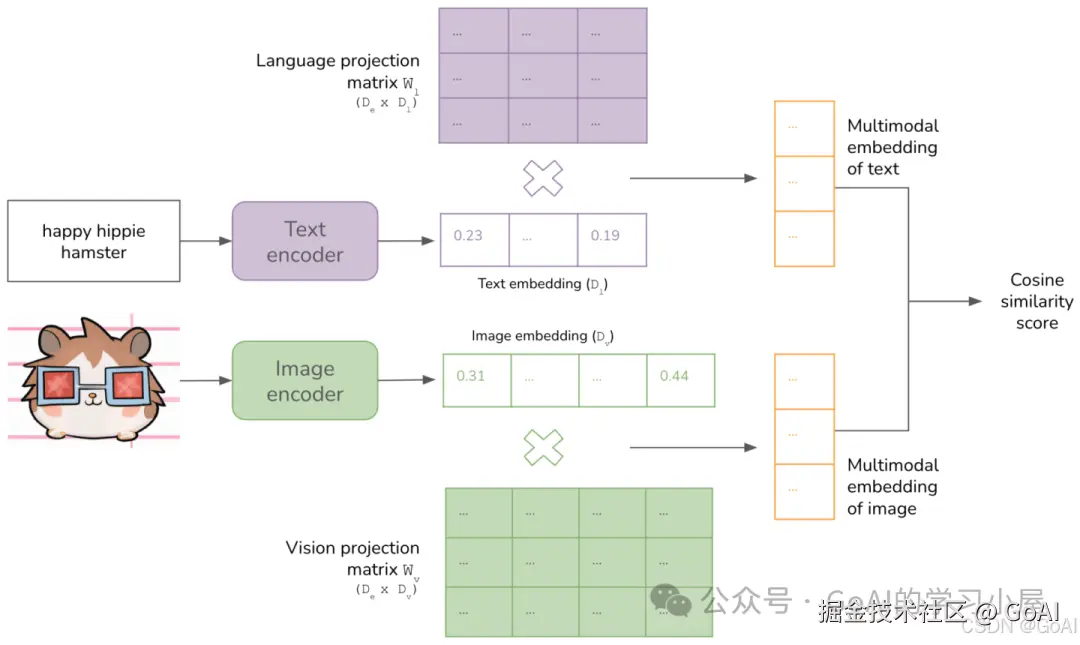
在这里插入图片描述
CLIP将图像和文本先分别输入一个图像编码器image_encoder和一个文本编码器text_encoder,得到图像和文本的向量表示 I_f 和 T_f 。其中 Image Encoder是 ResNet 或 Vision Transformer,Text Encoder 为 GPT-2。将图像和文本的向量表示映射到一个多模态空间(不同类型的数据整合到一个统一的空间),得到新的可直接进行比较的图像和文本的向量表示 I_e 和T_e 。计算图像向量和文本向量之间的cosine相似度。上述得到n x n矩阵,对角线为正样本为 1,其他为负样本0。有了n个图像的特征和n 个文本的特征之后,计算 cosine similarity,得到的相似度用来做分类的logits。对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。logits 和 ground truth 的labels 计算交叉熵损失,loss_i,loss_t分别是 Image 和 Text 的 loss,最后求平均就得到loss。(2)BLIP模型结构
BLIP由四个模块组成,分别是image encoder、text encoder(和image encoder 统一称为unimodal encoder)、image-grounded text encoder、image-grounded text decoder。
image encoder:visual transformer,VITtext encoder:BERT(双向自注意力机制+FFN),加一个 cls token放在text input前面总结整句话image-grounded text encoder:将image encoder的输出一起输入的cross attention中,输入端加一个任务特定的encoder token,attention采用Bi self-attention,使得text全部可见。image-grounded text decoder:将image encoder的输出一起输入的cross attention中,输入端加一个任务特定的decoder token,attention采用causal self-attention,使得text只能见到当前和历史的文本。损失函数
BLIP由三个损失函数监督,前两个是理解任务基础,另一个是生成任务基础 。具体损失如下:
Image-Text Contrastive Loss (ITC)
ITC通过对比学习,鼓励正向的图像-文本对在特征空间内靠近,而与负向对相远离,对齐视觉和文本转换器的特征空间。研究表明,ITC有效地促进了视觉和语言理解的提升。为了强化这一过程,ITC引入了动态编码器以产生特征,并利用软标签作为训练目标,以识别负对中潜在的正对。
Image-Text Matching Loss (ITM)
ITM专注于学习精细的视觉-语言对齐多模态表示。作为一个二分类任务,ITM用于预测图像-文本对是否匹配,通过线性层(ITM头)和它们的多模态特征。采用硬负采样策略,选择批次中对比相似度较高的负对参与损失计算,以获得更信息丰富的负样本。与ITC不同,ITM直接处理图像输入,以更精确地判断图像与文本的一致性。
Language Modeling Loss (LM)
LM旨在基于给定图像生成文本描述。LM通过交叉熵损失优化,以自回归形式训练模型,最大化文本可能性。在计算损失时,采用了0.1的标签平滑策略。不同于VLP中广泛使用的Masked Language Modeling损失,LM赋予模型根据视觉信息生成连贯文本描述的泛化能力。
数据生产
在这里插入图片描述
具体来说,BLIP首先以从网络爬取的可能不匹配的数据和部分人工标注的匹配数据(如COCO数据集)组成的数据集D进行预训练。BLIP利用人工标注的数据和内部的ITC&ITM模块微调Filter,筛选出不匹配的图像-文本对。接着,使用同样的标注数据和BLIP的Decoder微调Captioner,使其能根据图像生成匹配的文本,这些新文本再通过Filter判断其与原图像的匹配程度。通过这种方法,BLIP能构建一个高质量的新数据集D。
(3)BLIP2
动机:CLIP通过相似性计算,对图像和文本算是粗对齐(因为文本和图像只对最后的结果比较,打比方,装修房子,问两个装好的房子像不像,只能看到一些表面的,具体的材料是看不到的)。
总结: 为减少计算成本并避免灾难性遗忘的问题, BLIP-2 在预训练时冻结预训练图像模型和语言模型,在中间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂 (modality gap)。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。
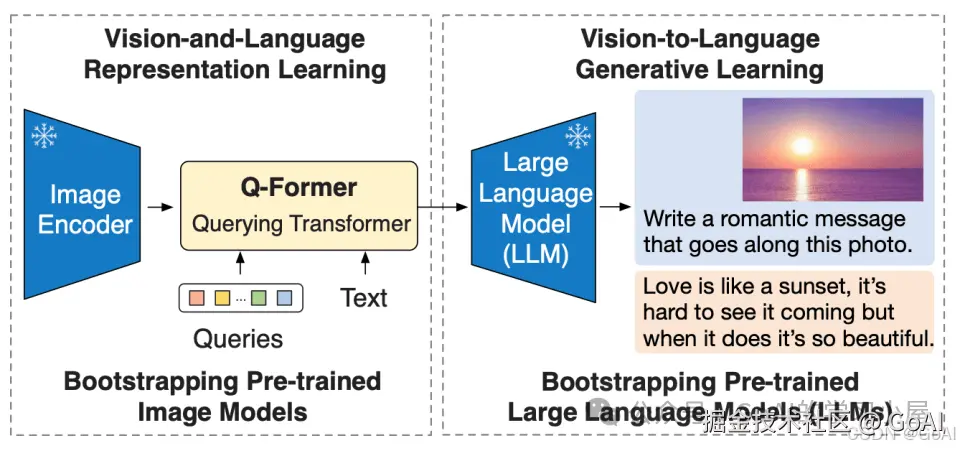
在这里插入图片描述
论文中作者提出了一种预训练框架,利用 预训练frozen冻结的图像编码器 + 可学习的Q-Former 和 预训练frozen冻结的LLM大规模语言模型 来进行图像和语言的联合预训练。
1)Image Encoder:负责从输入图片中提取视觉特征,本文试验CLIP 训练的 ViT-L/14和EVA-CLIP训练的 ViT-g/14两种网络结构。
2)Large Language Model:负责文本生成,本文试验decoder-based LLM and encoder-decoder-based LLM。
3) Q-Former :为BLIP2核心使用用两阶段预训练 Q-Former 来弥补模态差距,共分为表示学习阶段和生成学习两个阶段。
第一阶段:表征学习第二阶段:从大规模语言模型学习视觉到语言生成
BLIP2在Decoder-only 和Encoder-Decoder 架构的模型上均进行了实验。
注:目前BLIP系列已经更新到BLIP3 :《xGen-MM (BLIP-3): A Family of Open Large Multimodal Models》,在各方面进行升级:
(4 )LLaVa系列
论文动机: 通用LLM中指令遵循数据在Zero-shot场景下取得突破性进展,然而多模态领域探索的很少。
基本思想: LLaVA使用仅限语言的GPT-4生成多模态语言图像指令跟随数据,提出一种连接视觉编码器和LLM的端到端训练多模态大模型。
核心点: LLM基座采用更强的LLAMA模型,相比于BLIP-2 舍弃了Q-Former模块,直接将视觉编码器(CLIP)经过线性投影层作为LLM的软提示,再和指令数据一起让LLM生成对应任务回复。
训练流程:
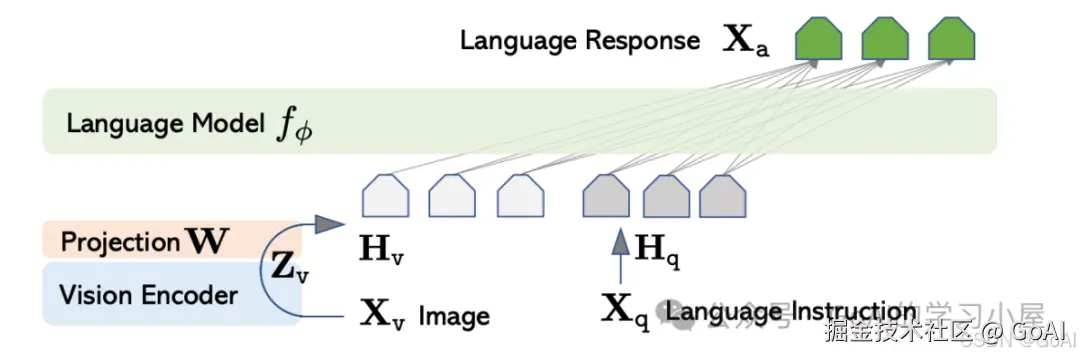
在这里插入图片描述
模型结构:
注:目前LLaVa系列已更新LLaVa-1.5、LLaVa-1.6、LLaVa-NEXT多个版本,具体细节可参考链接:/haotian-liu…
(5 )Qwen-VL系列
Github:/QwenLM/Qwen… 体验地址:/qianwen/ Qwen-VL系列模型是大规模的视觉语言模型,包含两个版本:Qwen-VL和Qwen-VL-Chat。Qwen-VL是一个预训练模型,通过视觉编码器的连接,它扩展了Qwen-7B语言模型的视觉能力,支持更灵活的交互,如多图像输入、多轮对话和定位能力。
模型特点:模型结构
Qwen-VL模型主要分为图像编码器为ViT、连接模块为单层的查询+交叉注意力,改变图像序列的长度及LLM基座为Qwen(7B)器为ViT,大语言型为Qwen连接块为单层的询+交叉注意,改变图像序列的长度
大型语言模型:Qwen-VL采用使用Qwen-7B的预训练权重进行初始化。视觉编码器:位置感知的视觉语言适配器(0.08B):为了缓解长图像特征序列带来的效率问题,Qwen-VL引入了一个压缩图像特征的视觉语言适配器。该适配器包含一个随机初始化的单层交叉注意力模块。训练流程:
Qwen-VL系列作为目前国内主流多模态模型,其模型训练过程采用下图三个阶段进行训练,两个预训练阶段(预训练和多任务训练)和一个指令微调训练阶段。
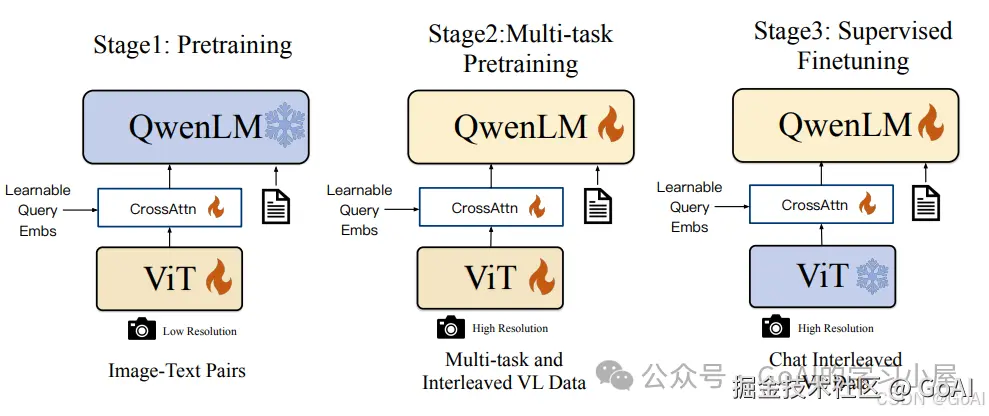
Qwen-VL还通过将边界框到归一化为指定字符串格式并对定位框增加和,边界框对应描述增加
注:目前该系列已更新到Qwen2-VL,学习可参考链接:…
三、多模态模型趋势总结四、全文总结:
本文主要对多模态模型的概念、下游任务类型、数据集、发展时间线的基础理论进行介绍,着重讲解经典多模态大模型(CLIP、BLIP、BLIP2等)原理及,最后对多模态趋势进行总结,欢迎大家在评论区交流学习,作者能力有限,若文中描述有误也欢迎大家指导!



