
- 作者:老汪软件技巧
- 发表时间:2024-11-21 11:03
- 浏览量:
首先给大家介绍一个很好用的学习地址:/columns
在上一章节中,我们重点探讨了聚类的可视化分析方法,帮助我们更好地理解数据之间的关系和结构。今天,我们将直接进入实际应用,使用聚类算法中的经典方法——k-means,对数据进行训练和预测。好的,我们直接开始。
构建模型
在进行数据清洗之前,我们首先回顾一下K-means聚类算法的核心概念。K-means聚类的主要目标是通过不断迭代优化质心,使得同一簇内的样本之间更加相似,而不同簇之间的样本差异则显著增加,从而实现有效的聚类效果。然而,这种算法也存在明显的缺点:首先,它对异常值极为敏感,异常值可能会对质心的计算产生较大影响;其次,K-means算法需要事先设定K个质心的数量,而这个预定的K值会直接影响模型的聚类效果。
尽管存在这些挑战,幸运的是,我们有一些方法可以帮助我们更好地分析和选择适合的K值。接下来,我们将开始清洗数据,为K-means聚类算法的应用做好准备。
数据准备
首先,我们需要对数据进行清理,去除那些不必要的字段以及包含大量异常值的特征。因为在K-means训练过程中,无用的特征和异常值会对模型的效果产生干扰,影响聚类的准确性和有效性。为此,我们将采用箱型图分析,这是一种直观有效的工具,可以帮助我们识别和处理异常值。
箱型图
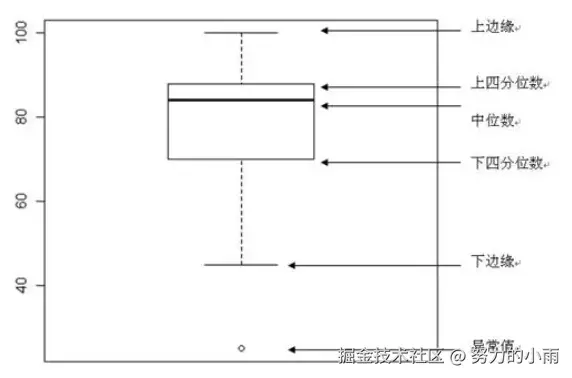
箱型图由五个重要的数值点构成,分别是最小观察值(下边缘)、25%分位数(Q1)、中位数、75%分位数(Q3)以及最大观察值(上边缘)。这些统计指标能够有效地概括数据的分布特征,帮助我们了解数据的集中趋势和离散程度。
在分析数据时,如果存在离群点,即异常值,它们的数值会超出最大或最小观察值的范围。在箱型图中,这些离群点通常以“圆点”的形式呈现,便于我们直观识别和处理。这些异常值需要特别关注,因为它们可能会对后续的K-means聚类分析产生负面影响。而对于箱型图中其他的数值点,如分位数和中位数,目前我们可以暂时不做过多关注,重点放在识别和处理这些离群点上,以确保数据的质量和聚类分析的有效性。
数据清洗
在开始清洗数据之前,首先请确保已安装所有相关的依赖包,以便顺利进行后续操作。
pip install seaborn scikit-learn
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv("../data/nigerian-songs.csv")
df = df[(df['artist_top_genre'] == 'afro dancehall') | (df['artist_top_genre'] == 'afropop') | (df['artist_top_genre'] == 'nigerian pop')]
df = df[(df['popularity'] > 0)]
这段代码的编写主要是基于我们在上一章节的分析结果,发现头三个流派的数据量最多。因此,我们决定直接保留这三个流派的相关数据,而不再保留其他流派的数据,以便更集中地进行后续分析和处理。
plt.figure(figsize=(20,20), dpi=200)
plt.subplot(4,3,1)
sns.boxplot(x = 'popularity', data = df)
plt.subplot(4,3,2)
sns.boxplot(x = 'acousticness', data = df)
plt.subplot(4,3,3)
sns.boxplot(x = 'energy', data = df)
plt.subplot(4,3,4)
sns.boxplot(x = 'instrumentalness', data = df)
plt.subplot(4,3,5)
sns.boxplot(x = 'liveness', data = df)
plt.subplot(4,3,6)
sns.boxplot(x = 'loudness', data = df)
plt.subplot(4,3,7)
sns.boxplot(x = 'speechiness', data = df)
plt.subplot(4,3,8)
sns.boxplot(x = 'tempo', data = df)
plt.subplot(4,3,9)
sns.boxplot(x = 'time_signature', data = df)
plt.subplot(4,3,10)
sns.boxplot(x = 'danceability', data = df)
plt.subplot(4,3,11)
sns.boxplot(x = 'length', data = df)
plt.subplot(4,3,12)
sns.boxplot(x = 'release_date', data = df)
我们可以直接根据各列的数据绘制箱型图,这样能够有效地展示数据的分布情况和离群值。如图所示:
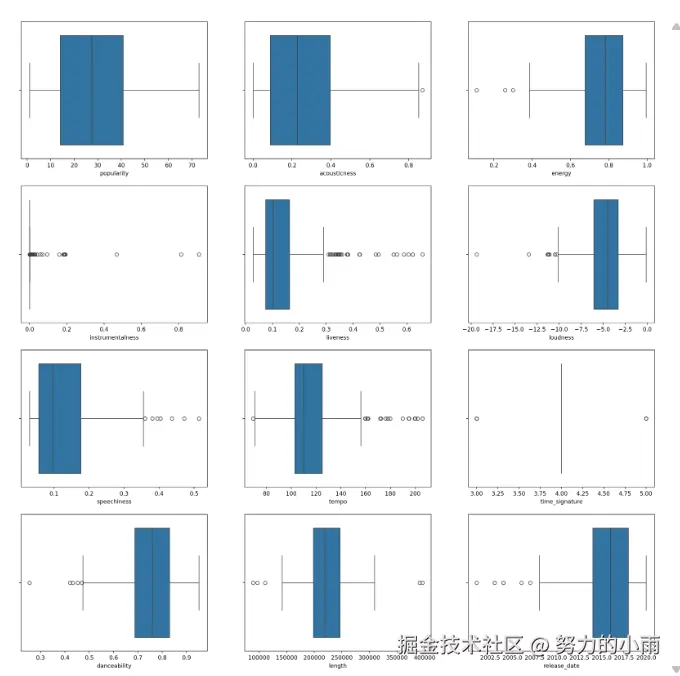
接下来,我们将删除那些显示异常值的箱型图,以便更好地集中于数据的主要趋势和特征。最终,我们将只保留如下所示的箱型图:
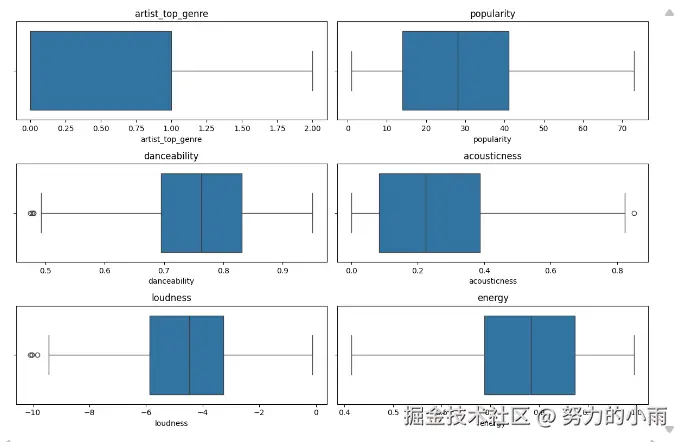
接下来,我们都知道数值特征在模型训练中起着至关重要的作用,因此有必要对这些特征进行适当的转换。此前我们已经讨论过相关的转换方法,这里就不再详细赘述。下面是实现该转换的代码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X = df.loc[:, ('artist_top_genre','popularity','danceability','acousticness','loudness','energy')]
y = df['artist_top_genre']
X['artist_top_genre'] = le.fit_transform(X['artist_top_genre'])
y = le.transform(y)
KMeans 聚类
由于数据来源于上一章节的观察与分析,尽管我们对其进行了初步的审视,但在具体的数据特征上,数据本身并不清楚其中存在三种不同的流派。因此,为了确定最佳的质心数量,我们需要借助肘部图进行深入分析,以便找到最合适的聚类设置。
肘部图
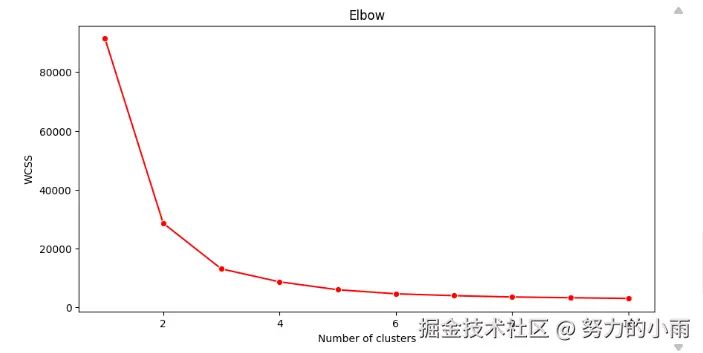
肘部法则(Elbow Method)是一种常用的技术,用于确定 K-Means 聚类中簇的数量 (K)。该方法通过分析不同 K 值下的聚类效果,帮助我们找到一个合适的簇数。其优点在于直观易懂,能够有效地指导聚类数的选择。
通常,随着 K 值的增加,总平方误差(SSE)会逐渐降低,但在某个特定的 K 值之后,误差减少的幅度会显著减小。这一转折点被称为“肘部”,它标志着增加 K 值所带来的收益逐渐减小,从而帮助我们识别出最佳的簇数。接下来,我们将绘制肘部图,以便直观地展示这一过程。
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.figure(figsize=(10,5))
sns.lineplot(x=range(1, 11), y=wcss,marker='o',color='red')
plt.title('Elbow')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
接下来,我将对这段代码进行简单的解释。其主要目的是通过遍历不同的 K 值,计算并存储每个 K 对应的组内平方和(WCSS, Within-Cluster Sum of Squares),以便后续绘制肘部图,帮助选择最佳的簇数。
在成功绘制肘部图之后,如图所示,我们可以清晰地观察到 WCSS 随着 K 值变化的趋势。通过分析这张图,可以明显看出,当 K 值为 3 时,误差的减少幅度显著减小,形成了一个明显的转折点。这个转折点表明,选择 K 为 3 是最优的,因为在此点之后,增加簇的数量对聚类效果的改善不再显著。
训练模型
接下来,我们将应用 K-Means 聚类算法,并设置质心的数量为 3,以评估模型的准确性和聚类效果。下面是实现这一过程的代码:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init = 'k-means++', random_state = 42)
kmeans.fit(X)
labels = kmeans.labels_
correct_labels = sum(y == labels)
print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size))
print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))
Result: 105 out of 286 samples were correctly labeled.Accuracy score: 0.37
令人失望的是,模型的准确性竟然不如随机猜测。这一结果促使我们回顾之前分析的箱型图,除了识别出一些明显不正常的特征外,我们还注意到许多保留下来的特征同样存在异常值。这些异常值无疑会对 K-Means 聚类的结果产生负面影响,因此,我们决定对这些特征进行标准化处理,以提高模型的稳定性和准确性:
from sklearn.preprocessing import StandardScaler
kmeans = KMeans(n_clusters = 3, init = 'k-means++', random_state = 42)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
kmeans.fit(X_scaled)
labels = kmeans.labels_
correct_labels = sum(y == labels)
print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size))
print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))
Result: 163 out of 286 samples were correctly labeled.Accuracy score: 0.57
在使用 K-Means 聚类时,采用 StandardScaler 进行数据标准化通常能够显著提升聚类效果。这主要是因为 StandardScaler 会将每个特征的均值调整为 0,标准差调整为 1,从而使得所有特征在同一尺度上进行比较。这种处理方式有效地消除了不同特征之间因尺度差异而导致的影响,避免了某些特征因其数值范围较大而在距离计算中占据主导地位的情况。
因此,通过标准化,我们能够更公平地评估每个特征对聚类结果的贡献,从而提升 K-Means 算法的整体性能和准确性。
总结
在本文中,我们深入探讨了K-means聚类算法及其在数据分析中的应用,特别是如何有效清洗和准备数据以提高聚类效果。通过利用箱型图,我们识别并处理了异常值,为后续的聚类分析奠定了坚实的基础。在确定适合的质心数量时,我们运用了肘部法则,成功找到了最佳的K值。
虽然初步模型的准确性并不理想,但通过数据标准化,我们显著提升了聚类效果,准确率达到了57%。这一过程不仅展示了K-means聚类的基本原理,也强调了数据预处理的重要性。清晰的数据不仅可以提高模型的可靠性,还能为数据分析提供更有意义的洞察。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。



