
- 作者:老汪软件技巧
- 发表时间:2024-11-18 11:05
- 浏览量:
一、引言
在 JavaScript 编程中,正则表达式是一种强大的工具,用于处理文本模式匹配和搜索、替换等操作。它能够让开发者以简洁而高效的方式处理复杂的字符串操作任务,无论是验证用户输入(如电子邮件地址、电话号码的格式验证)、解析文本内容(如从 HTML 文件中提取特定标签内的信息),还是在代码中进行文本替换和格式化等,正则表达式都有着广泛的应用。掌握正则表达式的使用可以极大地提升 JavaScript 开发的效率和质量。
二、正则表达式的基本概念(一)什么是正则表达式
正则表达式是一种用于描述字符模式的工具。它是由普通字符(如字母、数字、标点符号等)和特殊字符(称为元字符)组成的文本模式。这个模式可以用来匹配、查找、替换字符串中的特定内容。例如,正则表达式/abc/可以用来在一个字符串中查找是否存在连续的abc字符序列。
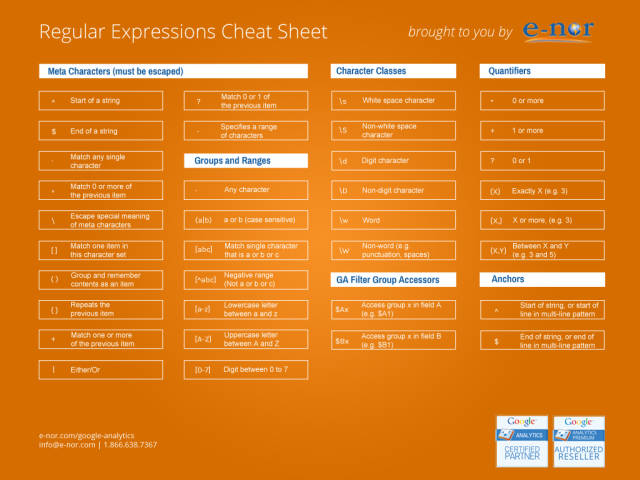
(二)元字符
常见元字符及其含义
字符类相关元字符
边界相关元字符
(三)转义字符
在正则表达式中,一些字符本身有特殊含义,如果要匹配这些字符的字面意义,需要使用转义字符。例如,要匹配一个点号`.`,正则表达式应该是`/./`,这里的告诉正则表达式引擎将.作为普通字符处理,而不是元字符。
三、JavaScript 中创建和使用正则表达式的方法(一)字面量表示法
使用正则表达式字面量是创建正则表达式的一种简单方式。正则表达式字面量由两个斜杠/包围,中间是正则表达式的模式。例如:
var pattern = /abc/;
这创建了一个可以匹配字符串中abc的正则表达式。可以使用test()方法来测试一个字符串是否匹配该正则表达式:
var str = "abcdef";
console.log(pattern.test(str)); // true
(二)构造函数表示法
使用RegExp构造函数也可以创建正则表达式。构造函数接受两个参数,第一个参数是正则表达式的模式字符串,第二个参数是可选的修饰符字符串。例如:
var pattern = new RegExp('abc');
var str = "abcdef";
console.log(pattern.test(str)); // true
使用构造函数的好处是可以动态地创建正则表达式。例如,可以根据用户输入来生成正则表达式模式:
var userInput = 'def';
var dynamicPattern = new RegExp(userInput);
var str = "abcdef";
console.log(dynamicPattern.test(str)); // true
(三)正则表达式的修饰符
i(忽略大小写)修饰符
i修饰符使正则表达式在匹配时忽略大小写。例如:
var pattern = /abc/i;
var str1 = "ABC";
var str2 = "abc";
console.log(pattern.test(str1)); // true
console.log(pattern.test(str2)); // true
g(全局匹配)修饰符
g修饰符用于进行全局匹配。当使用g修饰符时,在对一个字符串进行匹配操作(如exec()或match()方法)时,会匹配所有符合条件的子串,而不仅仅是第一个。例如:
var pattern = /a/g;
var str = "aabaa";
var matches = str.match(pattern);
console.log(matches); // ["a", "a", "a"]
m(多行匹配)修饰符
m修饰符用于多行匹配。在多行模式下,^和$可以匹配每行的开始和结束位置。例如:
var pattern = /^a/m;
var str = "a\nba";
var matches = str.match(pattern);
console.log(matches); // ["a"]
四、正则表达式在字符串匹配中的应用(一)test()方法
test()方法是正则表达式对象的一个方法,用于测试一个字符串是否匹配该正则表达式。它返回一个布尔值,如果匹配成功则为true,否则为false。例如:
var emailPattern = /^[a - z0 - 9._%+-]+@[a - z0 - 9.-]+.[a - z]{2,}$/i;
var email1 = "example@example.com";
var email2 = "invalid_email";
console.log(emailPattern.test(email1)); // true
console.log(emailPattern.test(email2)); // false
这个例子使用正则表达式来验证电子邮件地址的格式,test()方法用于快速检查给定的字符串是否符合电子邮件的格式要求。
(二)exec()方法
exec()方法用于在一个字符串中执行匹配搜索。它返回一个数组,数组的第一个元素是匹配的子串,如果有捕获组(后面会介绍),则后续元素是捕获组匹配的内容。如果没有匹配,则返回null。例如:
var pattern = /(\w+)@(\w+).(\w+)/;
var str = "example@example.com";
var result = pattern.exec(str);
console.log(result);
// ["example@example.com", "example", "example", "com"]
exec()方法在需要获取匹配详细信息(如捕获组内容)时非常有用。它在每次调用时会记住上次匹配的位置,当使用g修饰符进行全局匹配时,可以通过多次调用exec()来获取所有匹配的子串。
(三)match()方法
match()方法用于在字符串中检索匹配正则表达式的子串。如果没有g修饰符,它的行为与exec()类似,返回一个数组,包含匹配的子串和捕获组内容(如果有)。如果有g修饰符,则返回所有匹配的子串组成的数组。例如:
var pattern1 = /\d+/;
var pattern2 = /\d+/g;
var str = "123abc456";
console.log(str.match(pattern1)); // ["123"]
console.log(str.match(pattern2)); // ["123", "456"]
五、捕获组的概念和应用(一)什么是捕获组
捕获组是正则表达式中用括号()括起来的部分。它可以捕获匹配括号内模式的子串,并在匹配完成后可以通过一些方法获取这些捕获的内容。例如,在正则表达式/(\w+)@(\w+).(\w+)/中,(\w+)就是捕获组,分别捕获电子邮件地址中的用户名、域名和域名后缀。
(二)使用捕获组获取匹配内容
在exec()和match()方法中的应用
如前面提到的,当使用exec()或match()方法时,捕获组的内容会作为结果数组的一部分返回。在exec()方法中,结果数组的第一个元素是整个匹配的子串,后续元素是捕获组匹配的内容。在match()方法中,如果没有g修饰符,情况类似;如果有g修饰符,只返回所有匹配的子串,不包含捕获组内容(除非使用matchAll()方法,后面会介绍)。
命名捕获组(ES2018 及以后)
在 ES2018 及以后,可以使用命名捕获组,它使得捕获组的内容更易于理解和使用。命名捕获组的语法是(?pattern),其中name是捕获组的名称,pattern是要匹配的模式。例如:
var pattern = /(?\w+)@(?\w+).(?\w+)/;
var str = "example@example.com";
var result = pattern.exec(str);
console.log(result.groups.username); // "example"
console.log(result.groups.domain); // "example"
console.log(result.groups.extension); // "com"
六、正则表达式在字符串替换中的应用(一)replace()方法
replace()方法用于在字符串中用指定的字符串替换匹配正则表达式的子串。它接受两个参数,第一个参数是正则表达式或要被替换的字符串,第二个参数是用于替换的字符串。例如:
var str = "Hello, world!";
var newStr = str.replace(/world/, 'JavaScript');
console.log(newStr); // "Hello, JavaScript!"
如果使用g修饰符,可以替换所有匹配的子串:
var str = "aaabbb";
var newStr = str.replace(/a/g, 'x');
console.log(newStr); // "xxxbbb"
(二)在替换字符串中使用捕获组
在替换字符串中,可以使用$符号加上数字来引用捕获组。$1表示第一个捕获组,$2表示第二个捕获组,以此类推。例如:
var str = "John Doe " ;
var newStr = str.replace(/(\w+) (\w+) <(\w+)@(\w+).(\w+)>/, '$2, $1 <$3@$4.$5>');
console.log(newStr); // "Doe, John "
如果使用命名捕获组,可以使用$来引用,例如:
var pattern = /(?\w+) (?\w+) <(?\w+)@(?\w+).(?\w+)>/;
var str = "John Doe " ;
var newStr = str.replace(pattern, '$, $ <$@$.$>' );
console.log(newStr); // "Doe, John "
七、正则表达式在字符串分割中的应用(一)split()方法
split()方法用于将一个字符串分割成数组。它接受一个正则表达式或字符串作为参数,根据匹配的子串来分割原字符串。例如:
var str = "a,b,c";
var parts = str.split(',');
console.log(parts); // ["a", "b", "c"]
当使用正则表达式时,可以实现更复杂的分割。例如,使用\s+(匹配一个或多个空白字符)来分割一个包含多个空格分隔单词的字符串:
var str = "Hello World";
var parts = str.split(/\s+/);
console.log(parts); // ["Hello", "World"]
八、复杂正则表达式的构建和应用案例(一)验证 URL 格式
var urlPattern = /^(https?://)?([\w-]+.)+[\w-]+(/[\w-./?%&=]*)?$/i;
var url1 = "https://www.example.com";
var url2 = "http://example.com/page";
var url3 = "invalid_url";
console.log(urlPattern.test(url1)); // true
console.log(urlPattern.test(url2)); // true
console.log(urlPattern.test(url3)); // false
这个正则表达式可以验证常见的 URL 格式,包括是否有协议(http或https)、域名和可选的路径部分。
(二)解析 HTML 标签
var html = '<p class="intro">Hello, <b>worldb>!p>';
var tagPattern = /<(\w+)(?:\s+([\w-]+="[^"]*"))*>/g;
var matches = html.matchAll(tagPattern);
for (const match of matches) {
console.log("Tag:", match[1]);
if (match[2]) {
var attributes = match[2].split(' ');
for (const attribute of attributes) {
var parts = attribute.split('=');
console.log("Attribute:", parts[0], "Value:", parts[1].replace(/^"|"$/g, ''));
}
}
}
这个正则表达式可以用于解析 HTML 中的标签,获取标签名和属性信息。虽然在实际应用中,不建议使用正则表达式完全解析 HTML(因为 HTML 的复杂性和不规则性),但对于简单的 HTML 片段处理,这种方法可以是一种快速的解决方案。
(三)匹配日期格式
var datePattern = /^(\d{4})-(\d{2})-(\d{2})$/;
var date1 = "2024-01-01";
var date2 = "01-01-2024";
var result = datePattern.exec(date1);
if (result) {
console.log("Year:", result[1], "Month:", result[2], "Day:", result[3]);
}
console.log(datePattern.test(date2)); // false
这个正则表达式用于匹配YYYY - MM - DD格式的日期,通过捕获组可以获取年、月、日的信息。
九、正则表达式的性能优化
避免过度使用通配符和贪婪匹配
在构建正则表达式时,过度使用通配符(如.*)和贪婪匹配可能导致严重的性能问题,尤其是在处理大型文本或复杂结构时。
例如,在解析一个大型的 HTML 文件时,如果使用//这样的正则表达式来匹配标签,正则表达式引擎可能需要大量的回溯操作。因为它会从遇到的第一个,然后如果发现不符合要求,再回溯尝试其他可能的匹配。这会消耗大量的时间和内存。
相反,可以更精确地定义匹配模式。如果要匹配特定的 HTML 标签,比如
,可以使用/
]*>/。这里[^>]*表示匹配除了>之外的任意字符零次或多次,这样可以更快地定位到
标签,避免不必要的回溯。
对于贪婪匹配问题,如在处理 XML 或 HTML 中的文本内容时,如果有嵌套结构,贪婪匹配可能会导致错误的结果。例如,在 XML 中有如下内容:
<tag>text1<subtag>text2subtag>text3tag>
如果使用/(.*)/这样的贪婪匹配正则表达式,它会匹配整个text1text2text3,而如果我们希望只匹配最外层的内容,可以使用懒惰匹配/(.*?)/,这样就可以正确地匹配text1。
优化正则表达式的结构
正则表达式的结构复杂度对性能有很大影响。减少不必要的嵌套和复杂分组可以提高匹配速度。
例如,在验证一个字符串是否是有效的十六进制颜色代码时,可能有以下两种正则表达式:
复杂的结构:
var colorCodePattern1 = /^(#)?(([0 - 9a - fA - F]{2})([0 - 9a - fA - F]{2})([0 - 9a - fA - F]{2}))|(([0 - 9a - fA - F]{1})([0 - 9a - fA - F]{1})([0 - 9a - fA - F]{1}))$/;
简化后的结构:
var colorCodePattern2 = /^(#?([0 - 9a - fA - F]{1,2}){3})$/;
在这个例子中,colorCodePattern2通过更简洁的结构实现了相同的功能,减少了分组和条件判断,提高了正则表达式的性能。
另外,使用字符类代替分支结构也可以优化性能。例如,在匹配数字或字母时,/[0 - 9a - zA - Z]+/比/(0|1|2|...|9|a|b|...|z|A|B|...|Z)+/性能更好,因为字符类可以在一次比较中确定字符是否匹配,而分支结构需要逐个尝试每个选项。
利用正则表达式的编译和缓存
在 JavaScript 中,每次创建正则表达式时,浏览器都会对其进行编译。如果在一个频繁执行的函数中创建正则表达式,这种编译开销可能会影响性能。
例如,在一个循环中频繁使用正则表达式进行匹配:
for (var i = 0; i < 1000; i++) {
var pattern = /\d+/;
var text = "123abc";
var result = pattern.test(text);
}
在这个例子中,每次循环都创建了一个新的正则表达式/\d+/,导致了不必要的编译开销。可以将正则表达式的创建移到循环外面:
var pattern = /\d+/;
for (var i = 0; i < 1000; i++) {
var text = "123abc";
var result = pattern.test(text);
}
对于更复杂的应用,尤其是在一个应用中有多个地方使用相同的正则表达式时,可以考虑实现一个缓存机制。例如,可以创建一个对象来存储已经编译的正则表达式:
var regexCache = {};
function getRegex(patternString, flags) {
var key = patternString + flags;
if (!regexCache[key]) {
regexCache[key] = new RegExp(patternString, flags);
}
return regexCache[key];
}
var pattern1 = getRegex('\d+', '');
var pattern2 = getRegex('\w+', 'g');
// 使用 pattern1 和 pattern2 进行操作
通过这种缓存机制,可以避免重复编译相同的正则表达式,提高应用的整体性能。
此外,一些现代 JavaScript 引擎本身也可能会对频繁使用的正则表达式进行一定程度的优化和缓存,但手动实现缓存可以进一步提高性能,尤其是在对性能要求较高的应用中。



