
- 作者:老汪软件技巧
- 发表时间:2024-11-18 10:04
- 浏览量:
原文链接:…
更多精彩内容尽在南大通用GBase技术社区,南大通用致力于成为用户最信赖的数据库产品供应商。
基于审计日志的冷温热数据分析摘要
数据生命周期管理是项目中常见问题,一般解决方案为:
根据数据表创建时间和使用时间,计算出数据表的使用频率,从而将数据表分类为冷、温、热数据,以便客户进行数据清理或数据迁移。
但当表数据量较多时,该类信息无法快速或者直接从集群元数据中获取。
因此需要通过程序多维度地提取元数据中的信息,梳理出客户业务中常用、不常用的数据表,并经过加工整合归类分析,最终解决该类问题。
分析思路
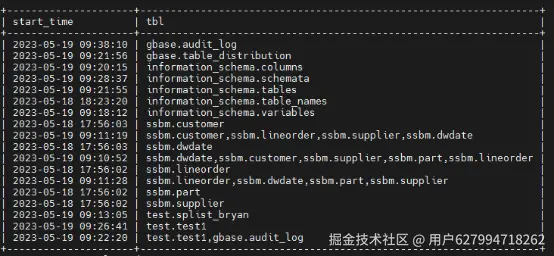
数据库中audit_log表的table_list字段,表示每个SQL语句所使用到的表,所有表名存储在与SQL对应的每一行上,且用逗号分隔。如果需要时间和表名的明细数据,需要做单行转多行的操作,该操作似于group_concat函数的反操作。
审计日志如下图:
审计日志表内数据整理后,期望格式如下:
期望实现效果如下:
难点分析解决方案新建表test.splist_bryan,作为自建笛卡尔积cross join时的伪参数表。
CREATE TABLE test.splist_bryan (
`id` int(19) NOT NULL,
`num` int(19) DEFAULT NULL
);
2. 新建存储过程,对伪参数表test.splist_bryan进行初始化操作。插入100行行号。
注: 这里假定每个sql 中涉及到的表不会超过100个(一般也不会超过)。如果有类似场景需要单行转多行,且拆分出的行数最大超过100个,在如下存储过程还可以再修改添加。
delimiter //
create procedure test.splist_init()
begin
declare num int;
set num=1;
while num < 100 do
insert into test.splist_bryan(id, num) values(num, num);
set num=num+1;
end while;
end //
delimiter ;
call test.splist_init() ;
3. 新建表test1 对audit_log表进行分类汇总统计。start_time是表最近访问时间,tbl是对应的表名(表名列表)。
注: 此处audit_log是根据集群中每个节点中的gbase.audit_log汇总而来的express引擎表,这里只为描述方便, 未作引用。
跨引擎迁移表内数据需要打开\_gbase\_query\_path参数。
create table test.test1 (start_time timestamp,tbl varchar(5000));
set global _gbase_query_path=1;
insert into test.test1 as
select max(start_time) as start_time,
replace( trim(regexp_replace(table_list,';|`|WRITE:|READ:|OTHER:','')),' ',',' ) as tbl
from gbase.audit_log
where length(trim(regexp_replace(table_list,';|`|WRITE:|READ:|OTHER:','')))<>0
and not regexp_like(db, 'gbase|information_schema|performance_schema|gctmpdb|gclusterdb', 'i')
group by replace( trim(regexp_replace(table_list,';|`|WRITE:|READ:|OTHER:','')),' ',',' )
集群新audit_log表各字段含义:
新建表test2,通过corssjoin自建笛卡尔积实现一行变多行;
通过substring_index函数实现对串的不同部分按照行号进行截取,进而统计出每张表最近的访问时间;
结果需要过滤掉系统库的表。

create table test.test2 as
select * from
(
select max(start_time) mydate,col as tblist
from
(
SELECT
t.start_time,
substring_index(
substring_index(
t.tbl,
',',
b.num
),
',',
- 1
) as col
FROM test.test1 as t
cross JOIN test.splist_bryan as b
on b.num <= LENGTH(t.tbl) - LENGTH(REPLACE(t.tbl, ',', '')) + 1
) as m
group by 2
) as p
where not regexp_like(tblist, 'gbase|information_schema|performance_schema|gctmpdb|gclusterdb', 'i')
以下结果显示,test2表中,每张表最近的使用日期。每张表占用一行,无重复表名。这样就可以根据这个日期,针对表进行使用热度分析。
冷温热数据分析
冷温热数据总量及明细
以移动通讯行业举例,一般1年内为热数据,1-3年内为温数据,3+为冷数据。可以对冷温热数据的不同定义进行分析。也可根据数据实际分布情况定义冷温热数据。
示例:
create table test3 as
select mydate,tblist,substring(tblist,1, INSTR(tblist, '.')-1) as dbname,substring(tblist,INSTR(tblist, '.')+1) as tbname,
case when diff<=256 then 'hot'
when diff>256 and diff<3*256 then 'warm'
else 'cold' end as class
from (select date(mydate) mydate,datediff(sysdate(),date(mydate)) as diff , tblist from test.test2 ) as p;
三种表的明细(查看部分数据)
三种表的总量:
分库分析冷温热数据
有时会需要弄清楚哪些库下的冷数据较多,需要先行清理,哪些可以后续清理,可以参考如下方式分析:
select class,dbname,count(tblist) from test.test3 group by class,dbname ;
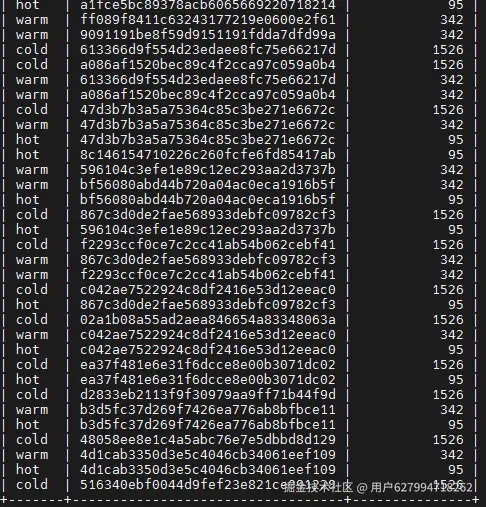
示例:
select dbname,sum(decode(class,'cold',1,0)),
sum(decode(class,'warm',1,0)),
sum(decode(class,'hot',1,0))
from test.test3 group by dbname ;
可以看出gbaserpt、gbaseods、gbasedwd、gbasemsm这4个库下的冷数据最多,应先行迁移或清理数据。
原文链接:…
更多精彩内容尽在南大通用GBase技术社区,南大通用致力于成为用户最信赖的数据库产品供应商。



