
- 作者:老汪软件技巧
- 发表时间:2024-11-13 21:03
- 浏览量:
阿里的 Qwen2.5-Coder: 属于你的编程助手
这几天通义千问团队开源更新了 Qwen2.5-Coder , 目前在社区上最大的参数是32B,
此次更新主要聚焦于两个核心领域的提升:
基于之前开源的 Qwen2.5 系列模型,Qwen2.5-Coder 进一步扩大了训练数据集,覆盖了更多的源代码、文本代码和合成数据,总量达到 5.5 万亿个 token,在更大的代码数据集上面进行训练,也就是说它的代码功能提高了不少,事实上也确实如此,我使用了 32B 的模型实际体验下来,它的代码能力应该在Haiku和4o之间。
而根据它官网的介绍,目前它( 32B Instruct )的代码能力是达到了开源模型最先进的水平。
下面附上它官网的图给大家看下排行榜的情况
模型链接(魔搭社区)放在这:/models/Qwen…
抱抱脸的链接就不放了,能上抱抱脸的应该都能找到,下载速度太慢就上 hf-mirror 镜像站进行下载。
用 ollama 或者 vllm 来跑32B模型的话,大概需要 18~25G的内存,我在我的mac上是正好占用了18G多一些内存,速度的话在18 token/s上下波动,输出速度比较慢,如果用其他规模的模型会快一些。
"Here's a super intelligent coder for free"
这是一个免费的超级智能程序员
这次更新的主要功能:
Qwen2.5-Coder 在 CodeQwen1.5 的基础上实现了以下关键进展:
代码生成、推理和修正能力的显著提升:Qwen2.5-Coder-7B 已成为目前最先进的开源代码大语言模型,其编码能力已接近 GPT-4o。为实际应用如代码代理等提供更为完善的基础:在保持其在数学和综合推理方面的优势的同时,Qwen2.5-Coder 进一步提升了实际应用支持。支持更长文本的处理能力:Qwen2.5-Coder 能处理高达 128K 标记的长文本,涵盖了多达 92 种编程语言。
通过这些更新,Qwen2.5-Coder 将为开发者和研究者在代码相关任务中提供更强大的支持。
Qwen2.5 Coder + VS Code/Cursor
Qwen2.5-Coder 在多项代码相关任务中取得了显著进展,包括代码生成、跨语言代码生成、代码补全和代码修复等。特别值得一提的是,Qwen2.5-Coder 的开源 7B 版本的表现超越了诸如 DeepSeek-Coder-V2-Lite 和 CodeStral-22B 等一些大型模型,展示了其在这些领域的强大能力。
代码修复是编程中的一项关键技能,而 Qwen2.5-Coder-32B-Instruct 能够显著提升用户修复代码错误的效率。Aider 是目前的一个常用的代码修复基准,Qwen2.5-Coder-32B-Instruct 在这个基准上得分 73.7,表现与 GPT-4o 不相上下。这意味着它在代码修复方面具备了强大的能力,能够帮助开发者更快速、更精准地解决问题。
而这个系列的代码推理能力也是得到了很大的提升,官网给出了在CoT的帮助下,推理能力的表现:
可以看到32B参数的模型性能已经能和4o打一打(虽然是5月的4ohhh),这样性能顶尖又是免费的模型,肯定得用在我们的编辑器上帮我们写代码改bug。
continue.dev 有一个免费的插件,能让你在 vscode 或 jet brains 中使用 ollama 等功能,并带有自动完成代码补全的功能,至于 Cursor z则是相当于另一个 vs code,vscode能做的cursor也能做。
对于将本地模型接入编辑器,第一种选择就是用插件来实现,插件商店里应该有不少可以实现对话、写代码这些功能的插件,第二种就是在配置中自定义你的api,我更喜欢在oneapi上面开一个接口,因为oneapi能统一接口到 OpenAI 的API格式,所以在服务器部署多个模型的时候,oneapi能让我自由选择我的模型,方便我切换使用模型。
如果使用本地电脑部署的话,你只能利用ngrok之类的工具暴露你的端口,然后才能在cursor中使用对话功能(没有补全功能)。参考一下这个仓库的解决方案:/audivir/cur…
本地部署
32B 在目前来讲确实看起来是 Qwen 的最佳选择,它在 Llama 系列只有 8B 和 70B 中间填补了空白,其中 8B 太小,性能跟不上,70B 需要的运行资源又太多。两天前在 Reddit 上有人试用了 32B,给你们看看别人的效果,里面用到的UI是open-webui:
里面的提示词:
Create a single HTML file that sets up a basic Three.js scene with a rotating 3D globe. The globe should have high detail (64 segments), use a placeholder texture for the Earth's surface, and include ambient and directional lighting for realistic shading. Implement smooth rotation animation around the Y-axis, handle window resizing to maintain proper proportions, and use antialiasing for smoother edges.
Explanation:
Scene Setup : Initializes the scene, camera, and renderer with antialiasing.
Sphere Geometry : Creates a high-detail sphere geometry (64 segments).
Texture : Loads a placeholder texture using THREE.TextureLoader.
Material & Mesh : Applies the texture to the sphere material and creates a mesh for the globe.
Lighting : Adds ambient and directional lights to enhance the scene's realism.
Animation : Continuously rotates the globe around its Y-axis.
Resize Handling : Adjusts the renderer size and camera aspect ratio when the window is resized.
以下是来自qwen官方的代码,这是一个简单的运行本地模型的代码,其实就是一个“试用版本”,用这种方式会占用很大的内存空间,并且运行一次之后下一次还得重新加载模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
本地部署模型的话,我的推荐是用vllm或者ollama来部署,最大化地利用你的CPU和GPU,在你没有GPU的情况下也能最大限度地发挥Qwen系列的性能。下面给大家介绍一下ollama本地部署qwen以及接入one-api的步骤。
首先我们还是需要来到ollama的官网 /download ,下载ollama。这里以0.5b超小杯模型为例,可以看到在右边有个 ollama run qwen2.5-coder:0.5b,复制这一行命令然后去你的shell运行。
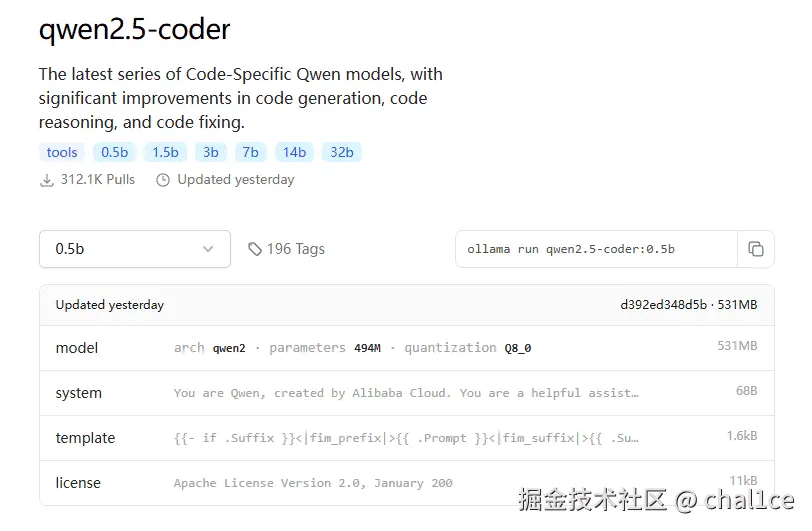
它会自动从网上拉取模型,当下载验证完毕之后它会自动运行,此时就可以在命令行里面和它交互对话了:
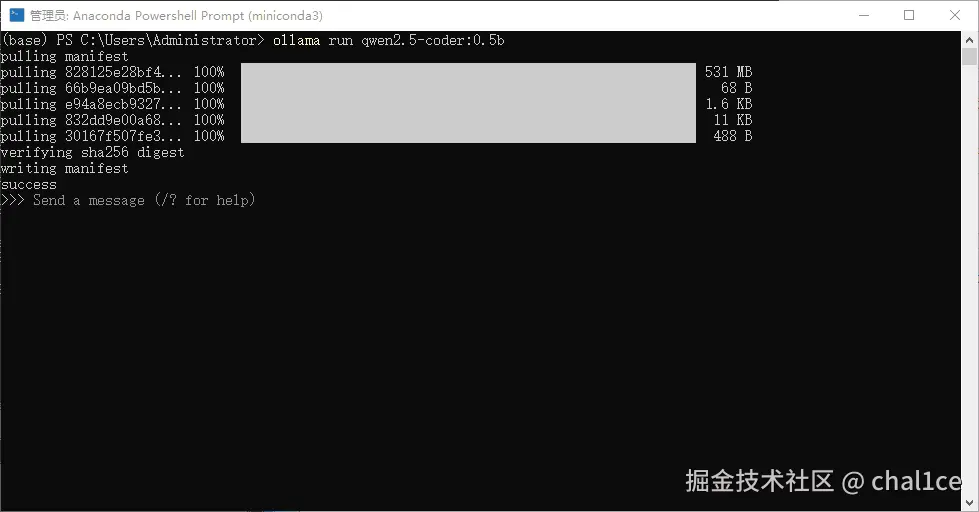
下面是接入one-api的方法,打开你的one-api地址,至于one-api如何安装,直接去网上找教程,这里以win系统为例,win有现成的包可以直接下载,docker部署等其他部署方法自行参考官方仓库教程。
打开你的one-api地址之后,进去设置渠道信息,这里用ollama一定要设置成为自定义渠道,否则在访问模型时会报错。Base url默认是本地11434接口,至于名称、分组、密钥随便填就行,模型重定向可以不填,自定义模型名称要填入qwen2.5-coder:0.5b,也就是你运行的模型的完整名称,忽略掉我里面的4o相关的信息,如图所示:
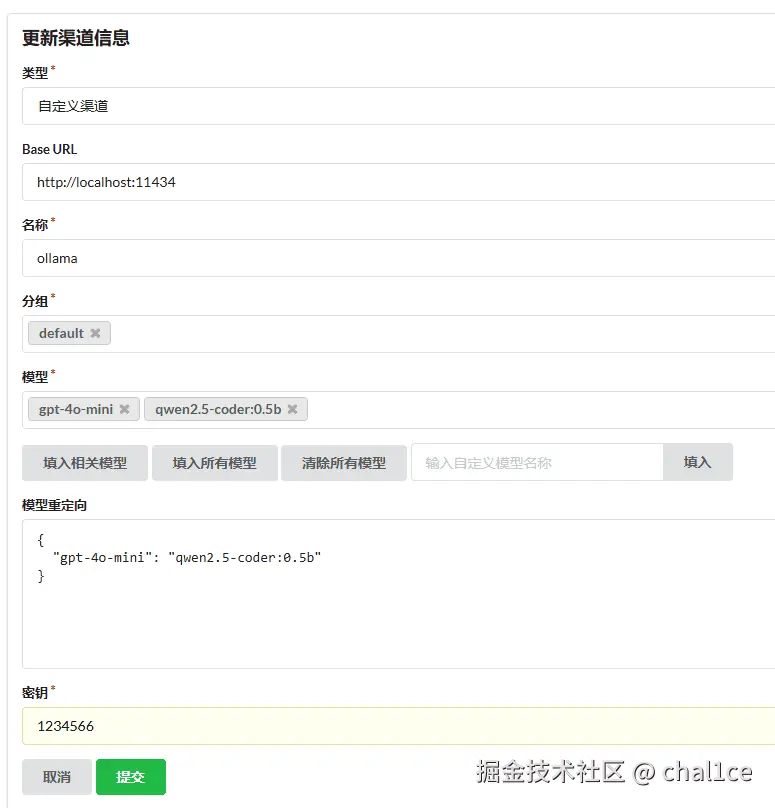
填好之后去外面点击测试,右上角出现测试成功的字样就说明部署成功了。
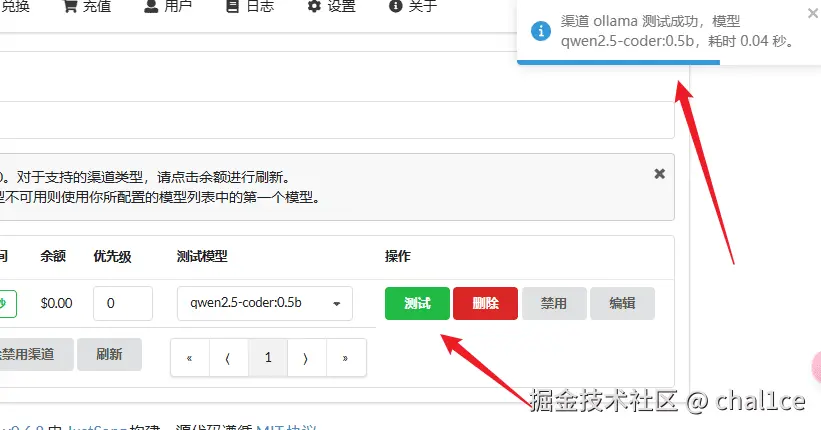
接下来到令牌那一区域,增加一个令牌,也就是你的api key,里面的模型范围把你部署的模型填上去,其他的无所谓,自己按照自己的需求来设置,设置完后记得保存。
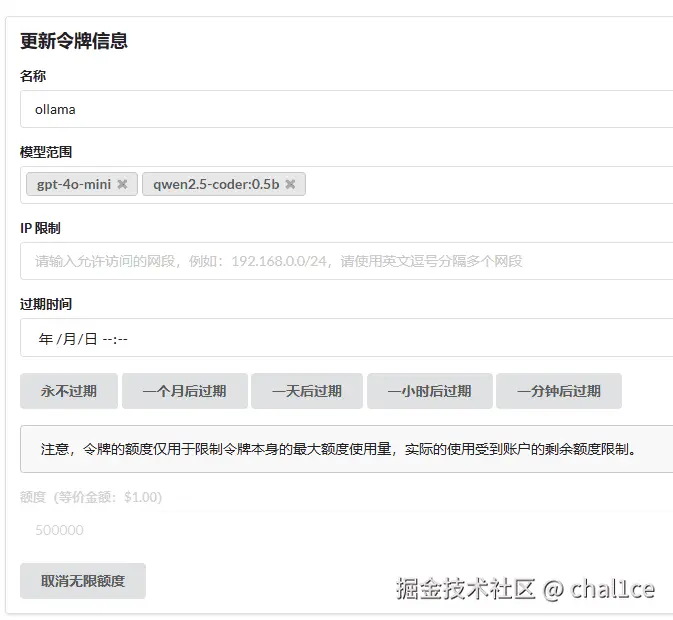
然后我们来到Chat Next Web进行测试,把API和模型换成我们的地址链接、api key和模型之后,就能够正常对话了。
最后,附上Instruct系列各个规模的模型的表现图,大家可以根据自己的需要去下载和部署模型。



