
- 作者:老汪软件技巧
- 发表时间:2024-11-11 17:02
- 浏览量:
嗨,大家好,我是小华同学,关注我们获得“最新、最全、最优质”开源项目和高效工作学习方法
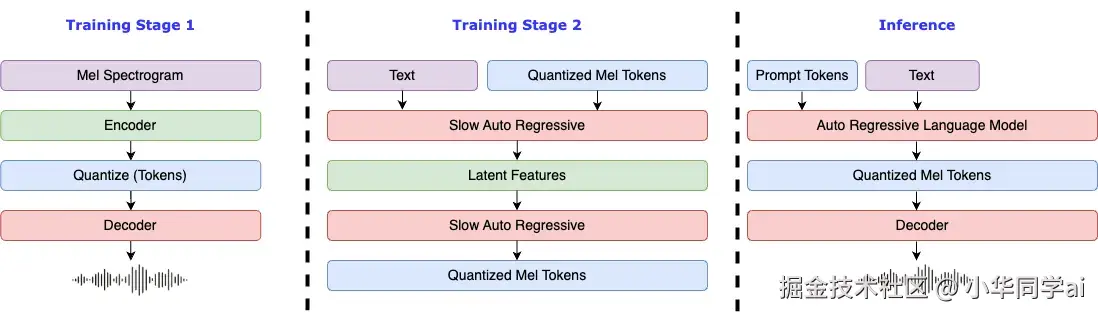
Fish Speech是一个基于深度学习的语音合成系统,它集成了VQGAN和LLAMA模型,能够简单方便的实现高质量的语音合成。同时还支持丰富的api接口
系统要求功能特点高质量语音合成
Fish Speech利用先进的VQGAN和LLAMA模型,能够生成接近真人发音的语音。它支持多种语音风格和效果,用户可以根据需求进行选择。
灵活的部署方式
无论是Linux、Windows还是macOS用户,Fish Speech都提供了详细的安装和配置指南。同时,通过Docker容器化部署,让用户在不同环境中快速启动服务。
易用的接口
Fish Speech提供了简单的API接口,开发者可以轻松地将语音合成功能集成到自己的应用程序中。
实时语音合成
用户可以通过WebUI界面实时地听到合成的语音,也可以通过命令行工具进行批量处理。
应用场景自动化阅读
Fish Speech可以用于自动化阅读,例如将电子书、新闻文章等文本内容转换为语音,方便用户在开车、做家务等场合收听。
语音助手
结合自然语言处理技术,Fish Speech可以用于开发智能语音助手,提供语音交互体验。
教育辅助
在教育领域,Fish Speech可以帮助制作有声教材,提高学习效率。
Windows 配置专业用户
Windows 专业用户可以考虑使用 WSL2 或 docker 来运行代码库。
# 创建一个 python 3.10 虚拟环境, 你也可以用 virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# 安装 pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# 安装 fish-speech
pip3 install -e .
# (开启编译加速) 安装 triton-windows
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
非专业用户
Windows 非专业用户可考虑以下为免 Linux 环境的基础运行方法(附带模型编译功能,即 pile):
解压项目压缩包。
点击 install_env.bat 安装环境。
若需要开启编译加速则执行这一步:
下载完 LLVM-17.0.6-win64.exe 后,双击进行安装,选择合适的安装位置,最重要的是勾选 Add Path to Current User 添加环境变量。
确认安装完成。
下载安装 Microsoft Visual C++ 可再发行程序包,解决潜在 .dll 丢失问题。
下载安装 Visual Studio 社区版以获取 MSVC++ 编译工具, 解决 LLVM 的头文件依赖问题。
下载安装 CUDA Toolkit 12.x
双击 start.bat 打开训练推理 WebUI 管理界面. 如有需要,可照下列提示修改API_FLAGS.
可选配置推理 WebUI 界面
想启动 推理 WebUI 界面?编辑项目根目录下的 API_FLAGS.txt, 前三行修改成如下格式:
--infer
# --api
# --listen ...
...
API 服务器
想启动 API 服务器?编辑项目根目录下的 API_FLAGS.txt, 前三行修改成如下格式:
# --infer
--api
--listen ...
...
命令行环境
双击 run_cmd.bat 进入本项目的 conda/python 命令行环境
Linux 配置
有关详细信息,请参见 pyproject.toml。
# 创建一个 python 3.10 虚拟环境, 你也可以用 virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# 安装 pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# (Ubuntu / Debian 用户) 安装 sox + ffmpeg
apt install libsox-dev ffmpeg
# (Ubuntu / Debian 用户) 安装 pyaudio
apt install build-essential \
cmake \
libasound-dev \
portaudio19-dev \
libportaudio2 \
libportaudiocpp0
# 安装 fish-speech
pip3 install -e .[stable]
MacOS 配置
如果您想在 MPS 上进行推理,请添加 --device mps 标志。 有关推理速度的比较,请参考 。
警告
compile 选项在 Apple Silicon 设备上尚未正式支持,因此推理速度没有提升的保证。
# create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# install pytorch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# install fish-speech
pip install -e .[stable]
Docker 配置安装 NVIDIA Container Toolkit
Docker 如果想使用 GPU 进行模型训练和推理,需要安装 NVIDIA Container Toolkit :
对于 Ubuntu 用户:
# 添加远程仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 安装 nvidia-container-toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# 重启 Docker 服务
sudo systemctl restart docker
对于使用其他 Linux 发行版的用户,安装指南请参考:NVIDIA Container Toolkit Install-guide。
注:对于中国大陆的用户,您可能需要使用代理来完成相关工具的安装。
拉取并运行 fish-speech 镜像
# 拉取镜像
docker pull fishaudio/fish-speech:latest-dev
# 运行镜像
docker run -it \
--name fish-speech \
--gpus all \
-p 7860:7860 \
fishaudio/fish-speech:latest-dev \
zsh
# 如果需要使用其他端口,请修改 -p 参数为 YourPort:7860
下载模型依赖
确保您在 docker 容器内的终端可用
同类项目结语
Fish Speech是一个非常有潜力的开源项目,它为开发者提供了一个简单而强大的语音合成工具。无论是用于个人项目还是商业应用,Fish Speech都能满足多样化的需求。
项目地址
https://github.com/fishaudio/fish-speech/



