
- 作者:老汪软件技巧
- 发表时间:2024-11-07 17:01
- 浏览量:
本文首发于公众号【DeepDriving】,欢迎关注。
0. 前言
OpenVINO(Open Visual Inference and Neural network Optimization)是英特尔推出的一个用于深度学习推理的开源工具套件,旨在帮助开发人员优化和部署深度学习模型,以在各种硬件平台上实现高性能的推理。OpenVINO的主要特点和功能:
跨平台支持:OpenVINO支持多种硬件平台,包括英特尔的CPU、集成显卡、FPGA以及神经计算棒(Neural Compute Stick),这使得开发人员能够在各种设备上进行高效的深度学习推理。
模型优化:OpenVINO提供了一系列工具和技术,可用于优化和转换深度学习模型,以便在目标硬件上实现更高的性能和效率,这包括模型压缩、量化、剪枝等技术。
推理加速:OpenVINO利用英特尔的硬件加速器(如英特尔集成显卡、FPGA等)以及优化的软件库(如英特尔数学核心库)来加速深度学习推理,提高推理速度和效率。
模型部署:OpenVINO提供了用于将优化过的深度学习模型部署到各种硬件平台上的工具和库,包括C/C++、Python、Java的API,以及支持各种框架(如TensorFlow、PyTorch等)的模型转换工具。
端到端解决方案:OpenVINO提供了端到端的解决方案,涵盖了从模型训练到推理部署的整个深度学习工作流程,使开发人员能够更轻松地构建和部署深度学习应用程序。
本文将以部署YOLOv10b为例介绍使用OpenVINO部署模型的基本流程和模型量化工具NNCF的使用方法。
1. 安装OpenVINO
OpenVINO有很多种安装方式,如果只想用Python版的API,可以直接用pip进行安装:
pip install openvino
如果还想用C/C++版的API,可以选择使用Archive文件进行安装。下文展示在Ubuntu 22.04系统中使用Archive文件安装OpenVINO的基本步骤:
创建安装目录并下载压缩包文件
# 创建目录
mkdir -p ~/intel && cd ~/intel/
# 下载文件
curl -L https://storage.openvinotoolkit.org/repositories/openvino/packages/2024.4/linux/l_openvino_toolkit_ubuntu22_2024.4.0.16579.c3152d32c9c_x86_64.tgz --output openvino_2024.4.0.tgz
# 解压包
tar -xf openvino_2024.4.0.tgz
# 重命名目录
mv l_openvino_toolkit_ubuntu22_2024.4.0.16579.c3152d32c9c_x86_64/ openvino_2024.4.0
#创建软链接
ln -s openvino_2024.4.0/ openvino_2024
安装必要的依赖库:
cd openvino_2024/
sudo -E ./install_dependencies/install_openvino_dependencies.sh
pip install python/requirements.txt
设置环境变量:
source setupvars.sh
为了方便,可以在~/.bashrc文件的最后添加一行命令用来设置OpenVINO的环境变量:
source ~/intel/openvino_2024/setupvars.sh
完成以上步骤后,可以执行下面的Python脚本查询当前OpenVINO可用的设备:
python samples/python/hello_query_device/hello_query_device.py
如果输出可用设备(一般只有CPU)的信息,说明OpenVINO已经安装成功。
2. 用OpenVINO部署模型2.1 模型格式转换
OpenVINO支持PyTorch、TensorFlow、PaddlePaddle、ONNX、OpenVINO IR等多种格式的模型,部署模型的时候可以选择先将其他格式的模型转换为OpenVINO IR格式再部署,也可以直接使用原来的格式进行部署。
将其他格式的模型转换为OpenVINO IR格式有两种方法,第一种方法是使用Python接口进行转换:
import openvino as ov
ov_model = ov.convert_model('yolov10b.onnx')
ov.save_model(ov_model, 'yolov10b.xml')
另一种方法是使用ovc命令:
ovc yolov10b.onnx
转换好的OpenVINO IR格式模型分为.xml和.bin两个文件。
2.2 基本部署流程
本文将介绍如何使用OpenVINO的Python接口部署ONNX格式的YOLOv10b模型。
用OpenVINO部署模型的流程非常简单,只需要以下几个步骤:
导入openvino包并创建Core对象
import openvino as ov
core = ov.Core()
加载并编译模型
compiled_model = core.compile_model("yolov10b.onnx", "AUTO")
模型的所有输入/输出信息可以通过下面的方式获取
inputs = compiled_model.inputs
outputs = compiled_model.outputs

如果模型只有一个输入/输出,也可以这样获取
input = compiled_model.input()
output = compiled_model.output()
或者通过索引来获取某个输入/输出的信息
input = compiled_model.input(0)
output = compiled_model.output(0)
然后可以获取模型输入/输出的维度和数据类型等信息
input_shape = input.shape
data_type = input.get_element_type()
创建推理请求
infer_request = compiled_model.create_infer_request()
绑定模型输入数据
# input_data是图片经过预处理后以NCHW的通道顺序排列的数据
input_tensor = ov.Tensor(array=input_data, shared_memory=True)
infer_request.set_input_tensor(input_tensor)
执行模型推理操作
infer_request.start_async()
infer_request.wait()
这里的推理方式采用异步模式,wait()是要一直等到推理完成。如果想设置一个最大等待时间,可以使用wait_for()函数:
infer_request.wait_for(100) #单位是毫秒
也可以采用同步方式进行推理(不推荐):
infer_request.infer()
获取推理结果,进行必要的后处理
output_tensor = infer_request.get_output_tensor()
output_data = output_tensor.data
# 对output_data进行后处理......
完整的推理流程代码如下:
import cv2
import numpy as np
import openvino as ov
# 读取测试图片
image = cv2.imread("soccer.jpg")
print("image shape: ", image.shape)
image_height, image_width, _ = image.shape
# 创建Core对象
core = ov.Core()
compiled_model = core.compile_model("yolov10b.onnx", "AUTO")
# 获取模型输入输出信息
inputs = compiled_model.inputs
outputs = compiled_model.outputs
input_shape = inputs[0].shape
model_height, model_width = input_shape[2:]
print("model_height: ", model_height)
print("model_width: ", model_width)
# 对图像数据进行预处理
input_data, ratio, x_offset, y_offset = preprocess(
image, image_width, image_height, model_width, model_height
)
# 创建推理请求
infer_request = compiled_model.create_infer_request()
# 把输入数据绑定到infer_request
input_tensor = ov.Tensor(array=input_data, shared_memory=True)
infer_request.set_input_tensor(input_tensor)
# 执行推理
infer_request.start_async()
infer_request.wait()
# 获取模型推理数据
output_tensor = infer_request.get_output_tensor()
output_data = output_tensor.data
# 后处理,省略...
对输入图片做预处理和对YOLOv10模型推理结果做后处理的代码在之前的文章已经贴过,这里就不再重复了。感兴趣的读者可以看下面这篇文章:
检测结果如下:
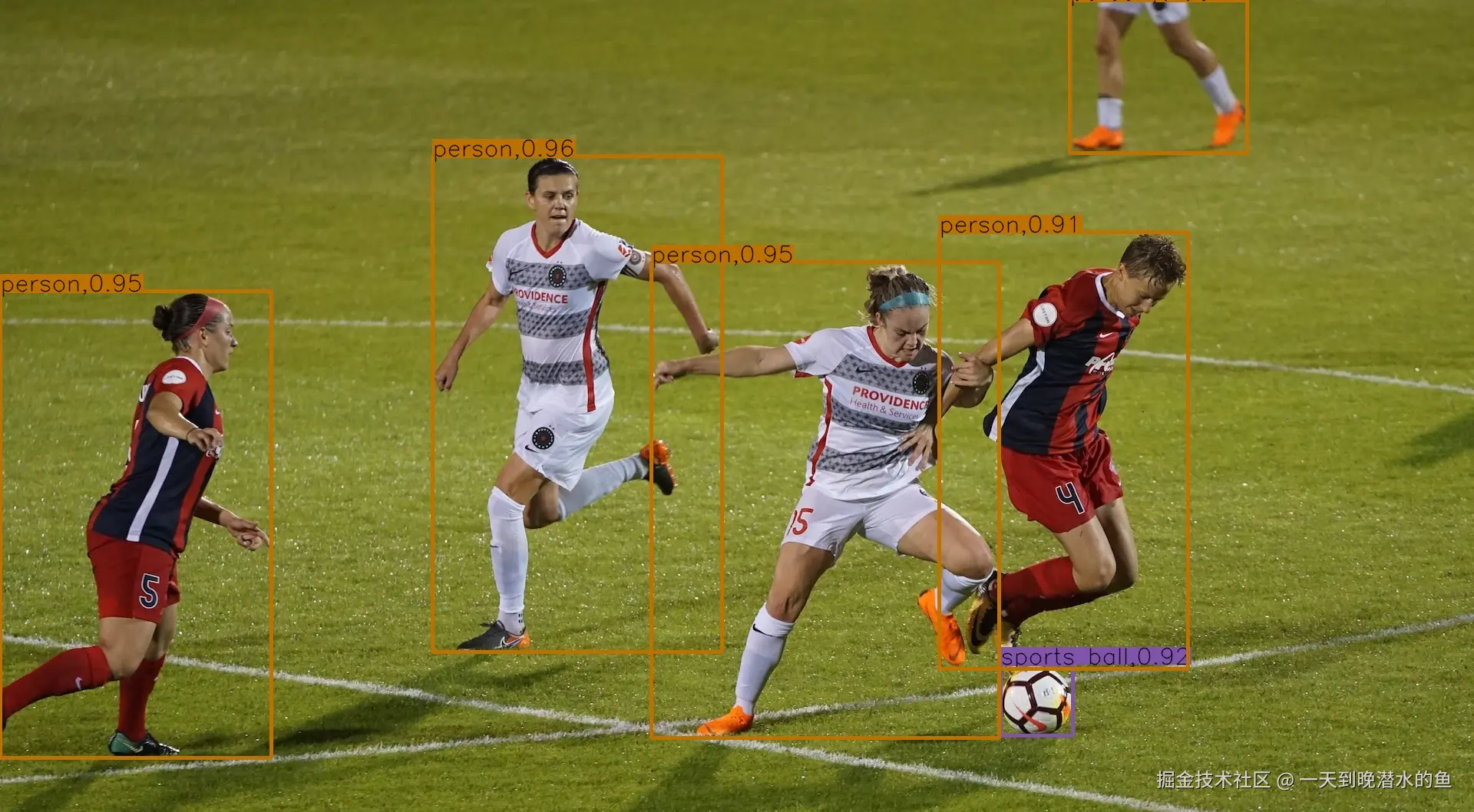
可以看到,OpenVINO推理结果与用ONNXRuntime推理的结果是一致的。但是由于是用CPU进行推理,整个处理过程耗时超过了400毫秒!
3. NNCF模型量化工具
由于使用Float32精度的模型进行推理速度太慢了,因此有必要对模型进行量化再做部署。本节将介绍如何使用模型量化工具NNCF(Neural Network Compression Framework)对模型进行INT8量化以加快推理速度。这里的量化指的是训练后量化(PTQ),需要从训练集或者验证集中选一定数量的图片作为校准数据。NNCF支持对OpenVINO IR、PyTorch、TensorFlow、ONNX等格式的模型进行量化,但是在实际使用过程中发现直接使用ONNX进行量化会报莫名其妙的错误(可能对ONNX的支持不太好?),因此下文将使用OpenVINO IR格式的模型进行量化。
NNCF可以直接通过pip命令进行安装:
pip install nncf
量化过程比较简单,只需要以下几个步骤:
准备校准数据
这一步需要创建一个nncf.Dataset类的实例,这个类的构造函数接收两个参数:数据集对象和转换函数。其中数据集对象用来加载校准数据并对数据做预处理操作,可以是深度学习框架中的数据加载器(比如PyTorch中的DataLoader),也可以是任意可迭代对象(比如一个列表);转换函数用于从数据集中取样并返回可传递给模型进行推理的数据。这是官方文档给的示例代码:
import nncf
import torch
calibration_loader = torch.utils.data.DataLoader(...)
def transform_fn(data_item):
images, _ = data_item
return images.numpy()
calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
加载模型并对模型进行量化
import openvino as ov
model = ov.Core().read_model("yolov10b.xml")
quantized_model = nncf.quantize(model, calibration_dataset)
调用nncf.quantize函数对模型进行量化,该函数还有其他参数进行设置:
fast_bias_correction:设置为False时,可启用更准确的偏差校正算法以提高量化模型的准确性(量化过程更耗时),默认为True以最小化量化时间。该参数仅对OpenVINO IR和ONNX格式的模型有效。subset_size:指定用于估计量化参数的校准数据集样本的数量,默认为300。保存量化好的模型
ov.save_model(quantized_model, "yolov10b_quantized.xml")
下面是对YOLOv10b模型进行量化的完整代码:
import os
import onnx
import cv2
import glob
import numpy as np
import nncf
import openvino as ov
import random
# 自定义一个可迭代对象用于加载校正数据
class CalibDataLoader:
def __init__(self, width, height, image_dir, num):
self.index = 0
self.width = width
self.height = height
self.num = num
self.image_list = glob.glob(os.path.join(image_dir, "**", "*.jpg"), recursive=True)
assert (len(self.image_list) >= self.num), "{} must contains more than {} images for calibration.".format(image_dir, self.num)
random.shuffle(self.image_list)
def __next__(self):
if self.index < len(self.image_list):
image_path = self.image_list[self.index]
image = cv2.imread(image_path)
if image is not None:
image_height, image_width, _ = image.shape
# 预处理函数与部署代码中一样
input_tensor = PreProcess(image, image_width, image_height, self.width, self.height)
self.index += 1
return input_tensor
else:
return np.array([])
else:
raise StopIteration
def __iter__(self):
return self
def __len__(self):
return len(self.image_list)
# 加载模型,获取模型输入信息
model = ov.Core().read_model("yolov10b.xml")
inputs = model.inputs
outputs = model.outputs
input_name = [name for name in inputs[0].names][0]
input_shape = inputs[0].shape
model_height, model_width = input_shape[2:]
# 创建DataLoader对象,设置校准数据集的目录和数量
calib_data_loader = CalibDataLoader(model_width, model_height, "/path/to/coco/val", 1000)
# 定义转换函数
def transform_fn(data_item):
return {input_name: data_item}
calibration_dataset = nncf.Dataset(calib_data_loader, transform_fn)
# 对模型进行量化
quantized_model = nncf.quantize(model, calibration_dataset, fast_bias_correction=False, subset_size=1000)
# 保存量化后的模型
ov.save_model(quantized_model, "yolov10b_quantized.xml")
用NNCF对模型进行量化还是很简单的,但是量化过程非常耗内存,设置校正数据量为1000就需要耗好几十G的内存!
量化后的YOLOv10b模型推理耗时约180毫秒,比Float32精度的模型还是快了很多的。
4. 参考资料



