
- 作者:老汪软件技巧
- 发表时间:2024-11-05 00:02
- 浏览量:
最近在忙一些AI相关的项目,也看了一些资料,而很多内容没有系统的总结,虽然研究生阶段是搞机器学习的,但是这个领域的发展太快了,一年不学就已经跟不上了,为了解决系统的总结一些知识点,于是我又开始了漫长的资料整理和学习之旅,本系列主要是如何从0开发大模型,这是第一篇。
本文使用是PyTorch2.0,可以使用python3 -c 'import torch; print(torch.__version__)'打印版本信息。
1、PyTorch简明教程1.1、安装
安装方式有很多教程,用conda或者直接安装都可以,这里我就在自己电脑上粗暴安装:
python3 -m pip install numpy torch torchvision torchaudio --index-url https://mirrors.aliyun.com/pypi/simple
1.2、简明教程
关注过我公众号的应该有读过《PyTorch简明教程上篇》《PyTorch简明教程下篇》,这里介绍的比较简单,有兴趣的可以再读一下,或者搜索相关的文章,这里就只回归一下PyTorch的四则运算,代码如下:
import torch
a = torch.tensor([2, 3, 4])
b = torch.tensor([3, 4, 5])
print("a + b: ", (a + b).numpy())
print("a - b: ", (a - b).numpy())
print("a * b: ", (a * b).numpy())
print("a / b: ", (a / b).numpy())
输出为:
a + b: [5 7 9]
a - b: [-1 -1 -1]
a * b: [ 6 12 20]
a / b: [0.6666667 0.75 0.8 ]
2、使用Transformers库
Transformers 库是一个开源库,其提供的所有预训练模型都是基于 transformer 模型结构的。
Transformers 库支持三个最流行的深度学习库(PyTorch、TensorFlow 和 JAX),我们可以使用 Transformers 库提供的 API 轻松下载和训练最先进的预训练模型,使用预训练模型可以降低计算成本,以及节省从头开始训练模型的时间,这些模型可用于不同模态的任务,例如:
2.1、安装
命令:
python3 -m pip install transformers --index-url https://mirrors.aliyun.com/pypi/simple/
这里需要注意的:如果是从huggingface.co下载模型,由于国内不能访问,所以建议先配置一下环境变量(国内镜像站点),export HF_ENDPOINT=
2.2、生成式模型
以下是一段古诗词生成的模型加载代码:
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-poem")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-poem")
text_generator = TextGenerationPipeline(model, tokenizer)
result = text_generator("昨日西风出佛面,", max_length = 50, do_sample = True)
print(result)
执行:HF_ENDPOINT= python3 from0_1.py代码
输出如下:
[{'generated_text': '昨日西风出佛面, 天 如 穹 盖 水 如 月 。 云 月 茫 茫 真 一 夜 , 千 古 高 人 骨 屡 热 。 今 老 去 诗 且 病 , 一 杯 径 欲 醉 中 别 。 眼 中'}]
3、用PyTorch尝试深度学习模型
这里以经典的MNIST数据集作为样例,简单回顾一下深度学习模型的流程,以下是对MNIST数据集使用PyTorch进行降噪处理。
3.1、下载数据源
使用网上的数据集或者下载当前数据集也可以:
https://s3.amazonaws.com/img-datasets/mnist.npz
3.2、加载数据
这里用numpy加载数据,代码如下:
import numpy as np
def load_data(path='mnist.npz'):
path = './mnist.npz'
f = np.load(path)
x_train, y_train_label = f['x_train'], f['y_train']
x_test, y_test_label = f['x_test'], f['y_test']
f.close()
return (x_train, y_train_label), (x_test, y_test_label)
train, test = load_data()
x_train = train[0]
y_train_label = train[1]
print("x_train: ", x_train.shape, ", y_train_label: ", y_train_label.shape)
输出:
x_train: (60000, 28, 28) , y_train_label: (60000,)
3.3、构建Unet
Unet是2015年提出的UNet模型是我们学习语义分割必学的一个优秀模型,它兼具轻量化与高性能,因此通常作为语义分割任务的基线测试模型,至今仍是如此。
UNet从本质上来说也属于一种全卷积神经网络模型,它的取名来源于其架构形状:模型整体呈现"U"形。它的出生是为了解决医疗影像语义分割问题的,但之后几年的发展,也证实了它是语义分割任务中的全能选手。
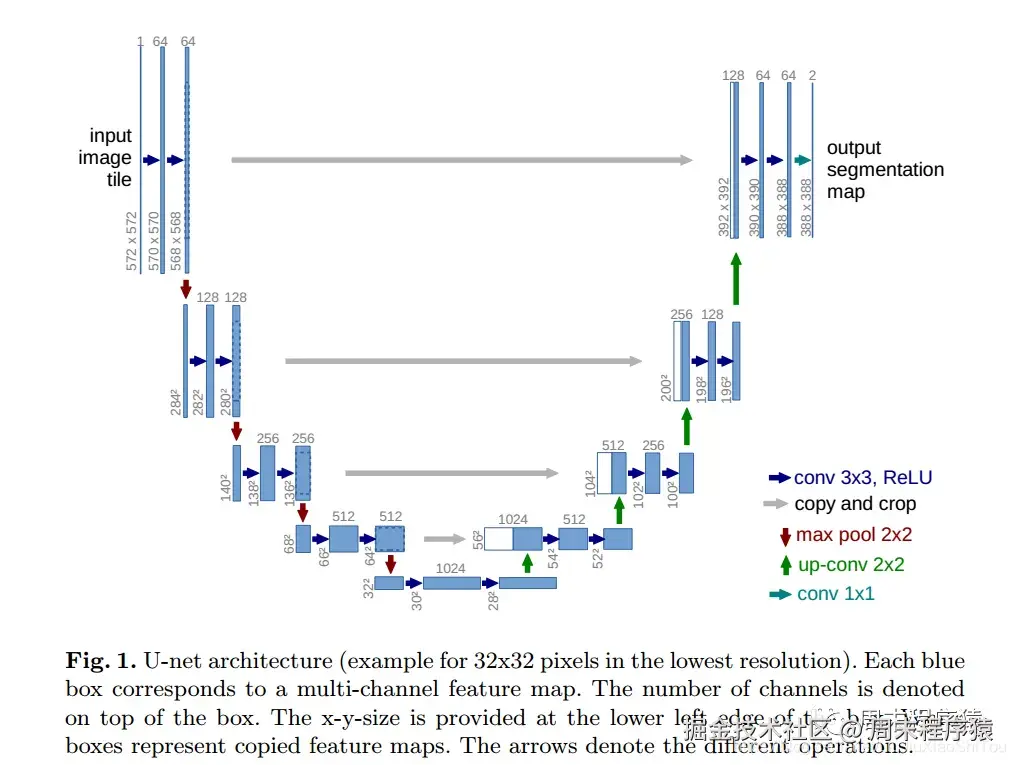
架构图
代码如下:
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.down1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.down2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.latent = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
)
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, padding=1),
)
self.up1 = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, padding=1),
)
self.end = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=1, kernel_size=3, padding=1),
nn.Tanh()
)
def forward(self, x):
image = x
image = self.down1(image)
image = self.down2(image)
image = self.latent(image)
image = self.up2(image)
image = self.up1(image)
image = self.end(image)
return image
x_input = torch.randn(2, 1, 256, 256)
net = UNet()
x_input_result = net(x_input)
print(x_input_result.shape)
输出:
torch.Size([2, 1, 256, 256])
3.4、定义损失函数和优化函数
损失函数是用来量化模型预测和真实标签之间差异的一个非负实数函数,其和优化算法紧密联系,深度学习算法优化的第一步便是确定损失函数形式,这里使用MSELoss作为损失函数,其使用方式如下:
loss = torch.nn.MSELoss(reduction='sum')(pred, y_batch)
优化函数在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向进行适合的更新,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小,这里选常用的Adam优化器,其使用方式如下:
optimizer = torch.optim.Adam(model.parameters(), lr = 2e-5)
3.5、训练模型
以下就是组合整个流程代码,这里做了一些简化,其代码如下:
from tqdm import tqdm
batch_size = 640 # 设置每次训练的批次数
epochs = 512 # 设定训练次数
device = "cpu" # cpu or gpu
model = UNet() # 导入模型
model = model.to(device)
model = torch.compile(model)
optimizer = torch.optim.Adam(model.parameters(), lr = 2e-5) # 优化函数
x_train = np.reshape(x_train, [-1, 1, 28, 28])
x_train = x_train / 512.0
train_length = len(x_train) * 20
for epoch in range(epochs):
train_num = train_length // batch_size
train_loss = 0
for i in tqdm(range(train_num)):
x_imgs_batch = []
x_step_batch = []
y_batch = []
for b in range(batch_size):
img = x_train[np.random.randint(x_train.shape[0])]
x = img
y = img
x_imgs_batch.append(x)
y_batch.append(y)
x_imgs_batch = torch.tensor(np.array(x_imgs_batch)).float()
y_batch = torch.tensor(np.array(y_batch)).float()
pred = model(x_imgs_batch)
loss = torch.nn.MSELoss(reduction='mean')(pred, y_batch) / batch_size
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= train_num
print("train_loss: ", train_loss)
...
输出如下:
train_loss: 11.968326873327854
...
注意
(1)错误:RuntimeError: Given groups=1, weight of size [64, 1, 3, 3], expected input[2, 3, 258, 258] to have 1 channels, but got 3 channels instead
解决:检查输入的nn.Sequential的in_channels是否维度和输入的数据一样,如果不一样,修改in_channels为1
(2)错误:OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialized.,然后python代码abort了
解决:引入如下代码
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
(3)在mac机器上跑以上代码,跑着跑着就Fatal Python error: Segmentation fault,也定位不到哪一行挂了
解决:为了定位python具体错误的哪一行,可以加入如下代码
import faulthandler
faulthandler.enable()
再次执行就能打印具体错误的那一行,然后跟着python代码可以定位到错误
(4)在mac上遇到Fatal Python error: Segmentation fault,定位到model = pile(model)Segmentation fault
解决:将这段注释掉即可,只是运行慢一点,不能进行加速,但是程序不会挂
参考
(1)/ - Huggingface 镜像站
(2)/img-dataset…
(3)《从零开始大模型开发与微调》



