
- 作者:老汪软件技巧
- 发表时间:2024-11-03 04:01
- 浏览量:
01 背景
B站湖仓一体平台数据规模约60PB,主要服务于BI报表、指标服务、A/B Test、人群圈选、日志等场景,日查询量超过400万,查询P99响应时间约为3s。平台架构如图所示:
湖仓一体平台架构图
平台使用Iceberg作为数据表的格式。Iceberg有独立开放的元数据管理体系,在Spark、Flink、Trino等主流计算引擎有完备的社区支持,且与Hive表相比具有以下优势:
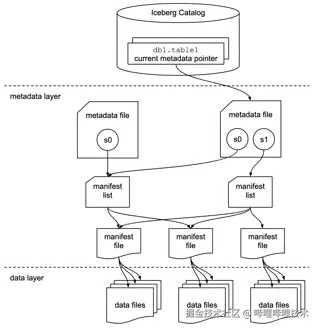
Iceberg表结构示意图
在Iceberg的基础上我们拓展和支持了多项查询加速能力,以满足用户多样化的分析需求:
这些查询优化手段能够应用到Iceberg表,实现百万级别查询的秒级响应,离不开Magnus服务。Magnus是我们自研的Iceberg表智能数据优化服务,其主要功能有:
本文将介绍Magnus的表管理、数据优化和智能推荐等功能的设计思路与实践成果。
02 表管理
表管理是Magnus服务的基本功能,负责调度Iceberg表的维护(Maintenance)操作,减轻存储压力,提升元数据的查询性能。Magnus调度的维护操作包括ExpireSnapshots、DeleteOrphanFiles以及RewriteManifests三种:
单次commit写入过多文件,产生一个较大的manifest,成为planFiles瓶颈
频繁写入产生大量小manifest,小文件读取性能差
同分区数据文件没有聚集到同一个manifest中,分区条件无法直接过滤掉整个manifest
RewriteManifests可以把manifest重写到预期大小,并让相同分区的数据文件尽量聚集到少量manifest中,提升planFiles性能,调度周期是天级别的。
03 数据优化
数据优化是Magnus服务的核心功能,我们基于Iceberg实现的多项查询加速技术,需要通过异步数据优化才能生效,是保障Iceberg表查询性能的关键。Magnus每天提交超过5万个优化任务,成功率超过99.9%,实时表优化延迟为15-30分钟,为平台百万级别查询的秒级响应提供了保证。
数据优化的流程如下图所示,主要包括优化任务的生成以及提交两个阶段。
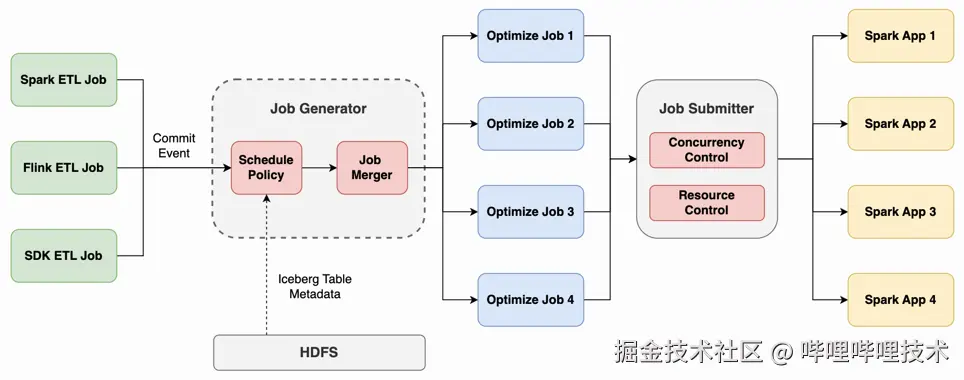
数据优化流程示意图
3.1 优化任务生成
当ETL任务提交数据写入时,会生成一个commit event并通过HTTP请求发送到Magnus。Commit event里面有写入的表名、snapshot id以及类型等信息。结合表的元数据信息,Magnus就能知道写入修改的分区,每个分区新增或者删除的文件名以及数据量。任务生成器中的调度策略根据这些信息生成多个优化任务。
调度策略是优化任务生成的核心,接下来介绍调度策略的设计思路。
我们支持的Iceberg表优化项共有五个:小文件合并、排序、分布、创建索引文件、创建预计算文件。其中分布优化是应用场景最广、查询加速效果最明显的优化手段,因此保证分布优化的效果是调度策略设计的一个关键点。在部分实时场景中,用户有查询小时内写入数据的需求,此时优化延迟会显著影响用户的查询体验,这是调度策略设计的另一个关键点。
平衡实时表的优化延迟和分布优化效果是调度策略的难点。分布优化的原理是提高数据在特定字段上的聚集性,利用Iceberg表文件级别的最大值和最小值统计信息来过滤文件,提升查询性能。如果对整个分区的数据执行分布优化,优化效果是最好的,但是需要等到分区数据全部写入,优化延迟高,小时内写入数据的查询性能会比较差。如果对每批写入的数据单独执行分布优化,优化延迟低,但优化后数据在指定字段的聚集性就会比较差。
为了解决这个难题,我们采取分级优化的策略(见下图),用少量计算资源换取更好的即时查询性能,同时也保证分区的整体优化效果。优化共分三个等级:
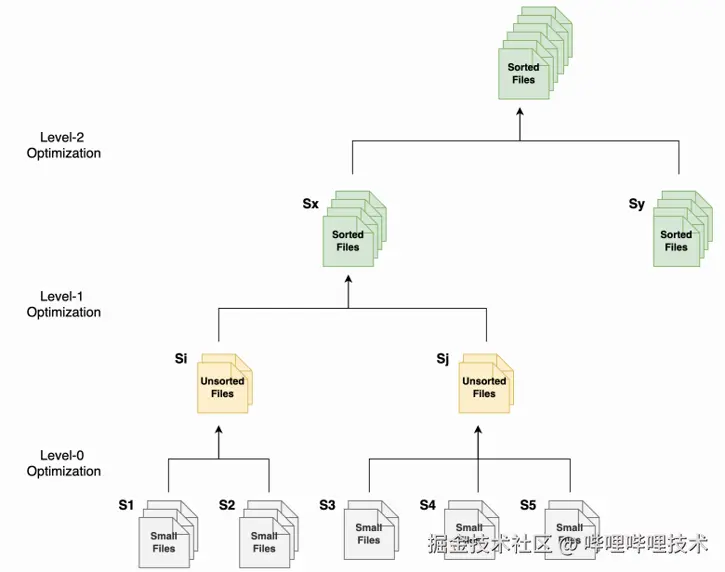
分级优化策略
优化任务调度的最小单位是snapshot,即分区内同一个snapshot写入的数据文件会被同时优化。Iceberg表的snapshot对应一次commit,而且仅通过snapshot id就可以关联到当次commit写入的所有数据文件。相比于调度数据文件粒度的优化,调度snapshot粒度的优化会更自然、更简单。
分级优化策略将Iceberg表的优化任务拆分成多个批次,如果每个批次都需要使用独立的Spark Application提交的话,会有很大的调度开销,甚至超过了计算本身的开销。因此我们会将同一张表多个批次的优化合并到同一个任务中,提交到同一个Spark Application执行。
3.2 优化任务提交
生成后的优化任务通过任务提交器提交到Spark执行优化。任务提交器内部维护一个优先队列,它对任务提交作以下这些管控:
3.3 优化结果展示
数据优化对Iceberg表查询性能影响重大,数据优化比例是处理生产慢查询时重点关注的指标。我们对Iceberg表优化详情做了分区级别的展示,包括文件数、文件大小、优化比例和最后写入时间等指标。
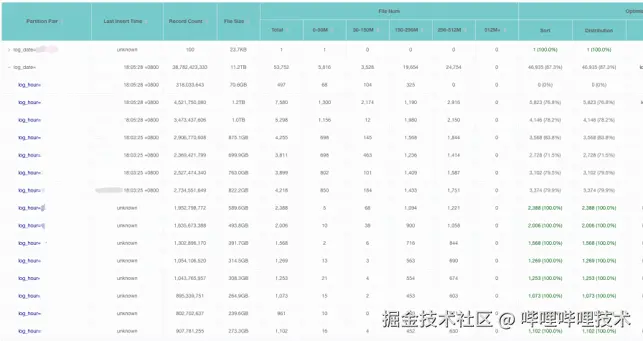
Iceberg表分区级别优化详情展示
04 智能推荐
智能推荐是Magnus服务的重要功能。我们在生产实践中发现,虽然开发支持的优化手段能够为查询带来数倍到数十倍的性能提升,但对用户的使用门槛较高。用户需要对业务的查询模式有清晰的认知,并了解相关的基础知识才能进行合理配置,达到最佳的优化效果。智能推荐的目标就是根据用户的查询历史,自动为Iceberg表配置合理的优化手段,透明地实现查询加速,降低Iceberg表的用户使用门槛,其主要流程图如下所示:
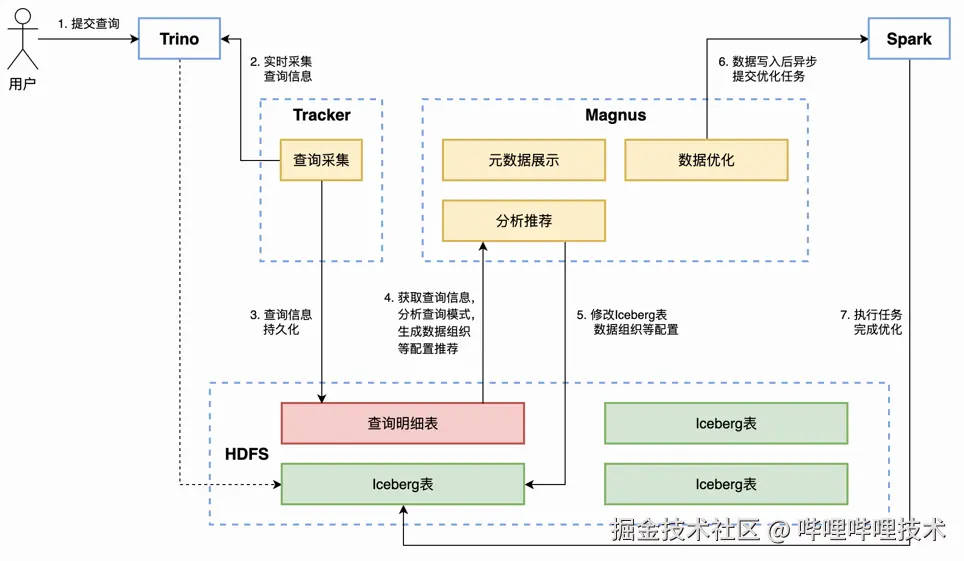
智能推荐流程示意图
4.1 查询采集
查询采集服务实时从Trino获取查询信息,并通过实时链路写入查询明细的Iceberg表。采集的查询信息分为四类:

值得注意的是,查询模式的提取是在Trino查询的planning阶段实现的,而不是通过一个独立的服务或模块解析原始sql实现的,这是出于开发和计算成本的考量。以过滤条件的提取为例,不能下推到Iceberg表的过滤条件是无法在存储层做优化的,而下推的逻辑是在优化器中实现的,独立的模块需要执行完整的analysis和planning操作才能把这部分过滤条件正确剔除掉,成本比较高。
4.2 分析推荐
Magnus将一定周期内所有查询的统计信息按照表维度进行聚合,再结合Iceberg表分区级别的统计信息,通过一系列规则给出一组推荐的优化配置。对于不同的优化手段,我们根据其优化原理和生产实践的经验,推导出需要分析的查询模式以及推荐依据(如下表),生成推荐规则。由规则构成的推荐策略在实现上比较简单,对于不是特别复杂的查询模式也会有较好的推荐效果。分析推荐任务每周对每张Iceberg表执行一次,当用户的查询场景发生变化时,推荐配置也会相应调整,以达到最佳的优化效果。
优化手段
优化原理
分析的查询模式
推荐数据
分布
Distribution
提高数据在特定字段上的聚集性,利用文件级别MinMax统计信息过滤数据
SELECT*
FROM*
WHERE a =2
索引
Index
文件级别数据过滤,原理取决于索引类型
排序
SortOrder
文件内部排序,节省局部排序的计算成本
SELECT*
FROM t
ORDER BY a ASC,b DESC
LIMIT 10
预计算
Aggregation
Index
文件级别预聚合,减少读取数据量
SELECT a,b,
count(x)
max(y)
FROM t
GROUP BY a,
分析推荐任务完成后,服务会把推荐结果配置到Iceberg表中,同时也会将推荐结果持久化,并展示到前端。前端展示的内容如下图,包括推荐配置与当前配置的对比,以及推荐使用的统计信息,方便我们进行跟踪分析,优化推荐策略。
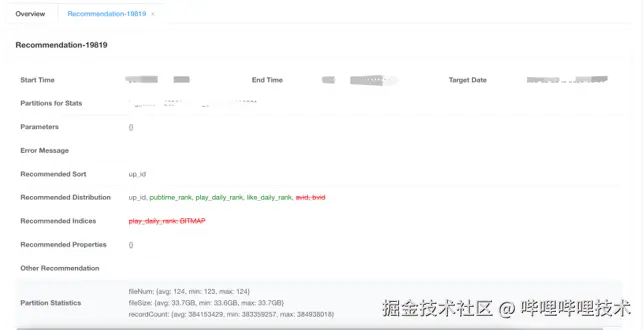
推荐结果展示
4.3 成果
我们目前针对一些没有进行任何优化配置的Iceberg表,开放了智能推荐功能。截至目前为止,已经对30多张表进行了优化。在这30多张表经过优化后的30天总体扫描数据量减少了28%。其中有超过60%的表扫描量减少了30%以上。目前项目的推荐策略还相对比较保守。在实际的生产环境中,有许多表已经由用户配置了一些优化手段,但由于配置不够合理,所以无法达到良好的加速效果。对这部分表开启智能优化功能,查询加速的收益会更高。
05 未来展望5.1 提高数据优化调度的承载能力和稳定性
虽然Magnus现阶段能够稳定、低延迟地完成Iceberg表的数据优化任务,但数据优化任务的链路上依然存在一些风险点。另外随着入仓链路从Hive表到Iceberg表的切换,未来Iceberg表的数量和数据量会有比较快的增长,Magnus也需要调整架构来处理海量的优化任务,保障优化任务的稳定运行。我们将从以下几个方面着手:
5.2 迭代优化智能推荐策略
目前智能推荐功能已经具备对简单查询场景的推荐能力,但推荐准确率有待提高,尤其是针对有复杂查询模式的Iceberg表的推荐,因此在实践中的应用受到限制。比如分布和索引的推荐中,影响推荐准确率的关键因素之一是过滤效果的判断,因此我们会考虑使用更详细的统计信息,如实际数据分布,来辅助推荐决策。随着参考统计信息的增加,决策模型的参数将变得更加复杂,我们也将考虑利用机器学习或人工智能算法来进一步提高推荐准确性。



