
- 作者:老汪软件技巧
- 发表时间:2024-10-05 11:01
- 浏览量:
访问文件
文件 = 文件内容 + 文件属性(例如:文件名称、文件拥有者、修改时间)
在系统里新建一个空文件也要占磁盘空间
但文件在磁盘放着,磁盘是硬件,只有os能访问磁盘
所以访问文件,本质是进程调用系统接口访问文件
linux文件权限什么是文件权限
权限就是是一件事情是否允许被某个用户"做"
即权限 = 用户 + 事物属性
linux的文件权限 = 用户 + 文件属性
用户有三种:拥有者、所属组、other
文件属性也有三种:读、写、执行
如何查看linux文件的权限
ll可以查看当前目录下文件的属性详情,里面就包含了文件的权限
文件权限:-rw-rw-r--
1 第一列的第一个字符,表示该文件的文件类型
d:目录
-:普通文件
p:管道文件
b:块设备/磁盘设备
c:字符设备,例如:键盘或显示器
l:链接文件,例如快捷方式
2 剩下的固定9个字符,3个字符为一组,分别表示拥有者、所属组、other
rwx的位置是固定的,如果要表示没有对应权限,用-表示
3 -rw-rw-r--
表述文件的权限:
该文件是普通文件
拥有者具有读权限、写权限,没有可执行权限
所属组具有读权限、写权限,没有可执行权限
other具有读权限,没有写权限和执行权限
4 由于linux权限可以用固定的9个字符表示,且每个字符是二态的,要么有要么没有,
所以可以用三个8进制数来表示文件的权限。0是8进制的前缀,例如:
0777:换成二进制就是 111 111 111,表示拥有者、所属组、other都拥有读、写、执行权限
umask权限掩码
linux默认:一个目录被创建,起始权限是从777开始;
一个普通文件被创建,起始权限是从666开始。
但最终权限 = 起始权限 & ~umask
凡是在权限掩码中出现的权限,都不能出现在最终权限中
umask是1个三位八进制数,以0002为例: 000 000 010,表示创建文件时,other的写权限要被去掉
语言对文件系统调用接口的封装
1 系统调用接口要懂系统 —— 难度较高,语言会对这些接口做封装,让这些接口更好用
不同语言,有不同的文件访问接口,但封装的都是系统调用接口
2 跨平台 —— 一份代码,放在linux上运行,也能放在windows上运行
如果语言不提供对文件系统调用接口的封装,所有访问文件的操作,都必须使用os的接口,
windows和linux的文件系统调用接口是不一样的!!!
而用户要访问文件,一旦使用系统接口编写文件相关代码,就无法在其他平台中直接运行。
C文件访问接口
// 以写入方式打开,当前路径指的是进程的cwd
FILE *fp = fopen("log.txt", "w");
if (fp == NULL)
{
perror("fopen");
return 1;
}
const char *s1 = "hello fwrite\n"; // '\0'结尾是c语言的规定,文件不需要遵守!文件只保存有效数据
fwrite(s1, strlen(s1), 1, fp);
const char *s2 = "hello fprintf\n";
fprintf(fp, "%s", s2);
const char *s3 = "hello fputs\n";
fputs(s3, fp);
fclose(fp);
return 0;
void usage(const char* proc)
{
cout << "Usage:"<" filename" << endl;
}
int main(int argc,char* argv[])
{
if(argc != 2)
{
usage(argv[0]);
return 1;
}
FILE* fp = fopen(argv[1],"r");
if(fp == NULL)
{
perror("fopen");
return 2;
}
char buffer[1024];
//fgets是c语言函数接口,会自动在字符结尾添加'\0'
while(fgets(buffer,sizeof(buffer)-1,fp) != NULL)
{
fprintf(stdout,"%s",buffer);
}
return 0;
}
linux文件类系统调用接口open和close
const char* pathname:要打开的文件路径
int flags:选项,打开文件时可以传递多个选项,表明要如何打开文件(例如读方式打开)
常用的选项有:O_CREAT(文件不存在就创建文件)、O_TRUNC(打开文件后先清空文件内容)
O_WRONLY(以只写方式打开文件)、O_RDONLY(以只读方式打开文件)、O_RDWR(读写方式打开文件)
O_APPEND(追加)
mode_t mode:8进制文件权限,代表创建新文件时,文件的权限是什么
返回值:成功返回文件描述符 >= 0,失败返回-1
int main()
{
//以只读方式打开
int fd = open("log.txt",O_RDONLY);
if(fd < 0){
perror("open error");
return 1;
}
printf("open success,fd:%d\n",fd);
//关闭文件
close(fd);
return 0;
}
//以只写方式打开,且打开文件时清空文件内容,相当于fopen的"w"
int fd = open("log.txt",O_WRONLY | O_CREAT | O_TRUNC);
if(fd < 0){
perror("open error");
return 1;
}
//关闭文件
close(fd);
open传递多个标志位的原理
flags的选项,本质是位图的某一个比特位,
传递时可以和其他比特位组合,实现不同的功能。
#include read和write
从文件描述符中读取最多count个字符,放到buf中
返回实际读到的字节数/字符数
int fd = open("log.txt",O_RDONLY);
if(fd < 0){
perror("open error");
return 1;
}
char buffer[1024];
ssize_t s = read(fd,buffer,sizeof(buffer));
if(s > 0)
{
buffer[s] = '\0';
}
cout << buffer << endl;
close(fd);
//该进程创建的文件,权限掩码都为0
umask(0);
//O_TRUNC:打开文件时,清空文件
//O_APPEND:向文件结尾追加
int fd1 = open("log1.txt",O_WRONLY|O_CREAT|O_TRUNC,0666); //相当于 fopen("log.txt","w")
int fd2 = open("log2.txt",O_WRONLY|O_CREAT|O_APPEND,0666);//相当于 fopen("log.txt","a")
string str = "hello world\n";
write(fd1,str.c_str(),str.size());
write(fd2,str.c_str(),str.size());
close(fd1);
close(fd2);
fd与FILE
FILE里封装了文件描述符fd,在系统层面只认fd
umask(0);
int fd1 = open("log1.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
int fd2 = open("log2.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
int fd3 = open("log3.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
int fd4 = open("log4.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
cout << fd1 << fd2 << fd3 << fd4 << endl;
以fd的0、1、2为例:
c语言默认会打开3个文件流:stdin、stdout、stderr 都是FILE*类型
0 —— 标准输入
1 —— 标准输出
2 —— 标准错误
fprintf(stdout,"hello\n");
const char* str = "hello\n";
//1 - 标准输出
write(1,str,strlen(str));
char buffer[1024];
//实际读到的byte数
ssize_t s = read(0, buffer, sizeof(buffer));
buffer[s] = '\0';
cout << buffer;
cout << stdin->_fileno << endl;
cout << stdout->_fileno << endl;
cout << stderr->_fileno << endl;
写一个cat命令
void usage(const char* proc)
{
printf("Usage:%s filename\n",proc);
}
int main(int argc,char* argv[])
{
if(argc != 2)
{
usage(argv[0]);
return 1;
}
int fd = open(argv[1],O_RDONLY);
char buffer[1024];
ssize_t s = read(fd,buffer,sizeof(buffer));
buffer[s] = '\0';
write(1,buffer,strlen(buffer));
close(fd);
return 0;
}
文件描述符fd文件描述符是什么
进程要访问文件,必须先打开文件!
一个进程可以打开多个文件,一般而言:
进程:打开的文件 = 1:n
一个文件要被访问,前提是加载到内存,才能被访问!!!
如果多个进程都打开文件,系统中会存在大量被打开的文件!!!
os要把这些被打开的文件管理起来 —— 先描述,再组织
在内核中,os要为了管理每一个被打开文件,构建struct file结构体,
每打开一个文件,就要创建struct file对象
struct file{
struct file* next;
struct file* pre;
//包含一个被打开文件的几乎所有内容(不仅仅属性)
//文件属性从哪里来 —— 磁盘
}
一个进程可能打开多个文件,怎么把该进程和打开的文件关联起来呢?
在内核中,为了维护进程和被打开文件的关系,每个进程各自私有一个指针数组
数组的元素是被打开的文件的地址,而文件描述符fd —— 就是该数组的下标
文件描述符分配规则
close(0);//本质是将进程文件描述符表中下标为0的元素置NULL
int fd = open("log.txt",O_WRONLY|O_TRUNC|O_CREAT);
cout << fd << endl; //0
int fd1 = open("log1.txt",O_WRONLY|O_CREAT|O_TRUNC);
cout << fd1 << endl; //3
int fd2 = open("log2.txt",O_WRONLY | O_CREAT | O_TRUNC);
cout << fd2 << endl; //4
从头扫描文件描述符表fd_array[],找到最小的、没有被占用的位置,将下标/文件描述符返回
open打开文件,系统做了什么
1 在内核中创建一个struct file对象(如果该文件没有被打开)
2 从头遍历进程的文件描述符表中,找到第一个NULL位置,把struct file对象的地址填进去,
同时把对应的数组下标fd返回给用户
重定向原理
进程被创建,它的文件描述符表的0 1 2 下标的值,会填写标准输入、标准输出和标准错误对应的struct file地址
给进程默认关联打开的三个文件
在打开文件之前,把文件描述符1关闭了 close(1)
然后打开一个新文件时,根据文件描述符分配规则,将新打开的文件对象地址填入 fd_array[1]
上层printf、cout等输出函数,只负责把内容写入给stdout(fileno =1),但下层的1已经指向log.txt
重定向的本质:在os内核更改fd对应的文件指向
close(0);//关闭标准输入
int fd = open("log.txt",O_RDONLY);
char buffer[1024];
fgets(buffer,sizeof buffer,stdin);//本来从标准输入/键盘读取,变成从文件中读取,按行读取
printf("%s",buffer);
int dup2(int oldfd, int newfd);
简单来说:让newfd指向的文件,和oldfd指向的文件保持一致
int fd = open("log.txt",O_RDONLY);
dup2(fd,0);//此时0也指向fd对应的文件
close(fd);//fd是要手动关的
char buffer[1024];
ssize_t s = read(0,buffer,sizeof(buffer));
if(s > 0)
{
buffer[s] = '\0';
write(1,buffer,strlen(buffer));
}
else{
cout << "读取文件描述符0的内容失败"<linux下一切皆文件广义上的文件
狭义上的文件:普通磁盘文件
广义上的文件:几乎所有外设,都可以称为文件
站在系统角度,可以Input读取,或者能够Output写入的设备就叫文件
理解一切皆文件
一切皆文件是linux的设计哲学
linux是用c写的!!!
类:包含成员属性和成员方法
c结构体怎么包含成员方法 —— 函数指针
struct file{
mode_t mode;//权限
long size;
int user;
int (*read)(int fd,void* buffer,int length); //读方法
int (*write)(int fd,void* buffer,int length);//写方法
}
所有外设的核心访问函数,都可以是read和write,
因为read->Input,write->Output。在冯诺依曼体系,对外设的操作无非是IO
当打开一个磁盘文件时,在内核里创建一个struct file对象,让read指针和write指针指向磁盘文件的读写方法
当打开显示器(默认就打开了),在内核里创建struct file对象,让read指针和write指针指向显示器的读写方法(涉及到驱动开发)
于是linux下有一切皆文件的理念!!!
VFS :虚拟文件系统
缓冲区什么是缓冲区
就是一段内存空间
//用户定义的用户层缓冲区
char buffer[1024];
int a;
scanf("%s %d",buffer,&a);
为什么要有缓冲区
1 写透模式WT:直接将数据写到硬件里
2 写回模式WB:先将数据写到缓冲区,缓冲区积累足够多的数据后,再一次性把数据刷新到硬件上
冯诺依曼体系结构里IO的效率是很低的,尽量减少IO次数,就需要使用缓冲区
缓冲区的刷新策略
1 立刻刷新
2 行刷新(遇到\n就把\n以前的数据刷新)
3 满刷新(把缓冲区写满才刷新)
4 特殊情况:
(1) 用户强制刷新,例如:fflush
(2) 进程退出
所有的设备,倾向于全缓冲,因为缓冲区满了才刷新,就需要更少次的io操作
其他刷新策略,是结合具体情况做的妥协,例如:
显示器:直接给用户看的,一方面要照顾效率,一方面要照顾用户体验
极端情况,可以自定义规则的 —— 立即刷新
往磁盘文件里写时,用户不需要立刻看到文件内容,当进程退出或强制刷新时,写到文件里就可以了,因此磁盘文件采用全缓冲
c语言库的缓冲区
int main()
{
//c库函数
fprintf(stdout,"hello fprintf\n");
const char* str = "hello fputs\n";
fputs(str,stdout);
//系统调用
const char* ss = "hello write\n";
write(1,ss,strlen(ss));
fork();//最后调用,上面函数已经被执行完了
return 0;
}
重定向后,log.txt里,c库函数打印的内容有2份
fputs等c库函数,是先把数据拷贝到c标准库提供的缓冲区中
c标准库再按照刷新规则,将数据刷新到os内核中 -> 调用write接口
fputs等c库函数,其实是拷贝工作,将数据拷贝到缓冲区,按照刷新规则,调用write接口写入到os内核中
//c库函数
fprintf(stdout,"hello fprintf\n");
const char* str = "hello fputs\n";
fputs(str,stdout);
//系统调用
const char* ss = "hello write\n";
write(1,ss,strlen(ss));
//fork之后的return 0:父子进程各自退出
//进程退出时,数据要被强制刷新
//刷新缓冲区,也是一种写入,清空缓冲区的数据,会发生写时拷贝
//所以缓冲区里的数据,会出现两份
fork();//fork之后,上面的函数已经执行完了,不代表数据已经刷新了
//3 之前谈的"缓冲区",一定是由c标准库维护的
1 如果向显示器打印,刷新策略是行刷新,最后执行frok时,一定是数据已经刷新了
2 如果进行了重定向,向磁盘文件打印 —— 满刷新.
上面函数执行完了,但数据没有刷新,还在当前进程的c标准库中的缓冲区里
3 c标准库里缓冲区的数据,也是父进程的数据!!!当fork()创建子进程时,父子进程的数据采用写时拷贝
4 进程退出时,数据是要被强制刷新的,即清空缓冲区,发生写时拷贝,父子各自执行一次,
所以上面的c库函数在文件中会打印2份.
5 c标准库的FILE给我们提供的用户级缓冲区
/usr/include/libio.h
一旦拷贝到file里的内核缓冲区,该数据就不属于进程了,属于内核数据,os会刷新
自己设计一个用户层缓冲区
使用c库函数所有IO接口fputs、fclose、fread、fwrite、fflush等,都会涉及FILE*,
因为无论读、写、刷新,文件描述符和缓冲区数据都在FILE*里.
struct MyFILE
{
int fd;
char buffer[1024]; // 缓冲区
int end; // 缓冲区结尾
};
//fopen模拟实现
MyFILE* myfopen(const char* pathname,const char* mode)
{
MyFILE* fp = NULL;
if(strcmp(mode,"r") == 0)
{
int fd = open(pathname,O_RDONLY);
if(fd >= 0)
{
fp = (MyFILE*)calloc(1,sizeof(MyFILE));
fp->fd = fd;
}
}
else if(strcmp(mode,"w") == 0)
{
int fd = open(pathname,O_WRONLY|O_TRUNC|O_CREAT,0666);
if(fd >=0)
{
fp = (MyFILE*)calloc(1,sizeof(MyFILE));
fp->fd = fd;
}
}
else if(strcmp(mode,"a") == 0)
{
int fd = open(pathname,O_WRONLY|O_CREAT|O_APPEND);
if(fd >= 0)
{
fp = (MyFILE*)calloc(1,sizeof(MyFILE));
fp->fd = fd;
}
}
return fp;
}
void myfputs(const char* str,MyFILE* fp)
{
int preLength = fp->end;
strcpy(fp->buffer+fp->end,str);
fp->end += strlen(str);
if(fp->fd == 1 || fp->fd == 2)
{
//标准输出/标准错误的刷新策略
const char* flag = strrchr(str,'\n');//从尾部开始找'\n',找到返回地址
if(flag != nullptr)
{
//在str中,'\n'对应的下标
int target = flag - str;
//因为str的内容被拷贝到了fp->buffer的尾部,所以在fp->buffer中,'\n'的下标是target + preLength
//将fp->buffer[target+preLength]以前的数据全部刷新
write(fp->fd,fp->buffer,target+preLength+1);
syncfs(fp->fd);//把数据从内核刷新出去
strcpy(fp->buffer,fp->buffer + target + preLength + 1);
fp->end = strlen(fp->buffer);
}
}
}
void myfflush(MyFILE* fp)
{
if(fp->end > 0)
{
write(fp->fd,fp->buffer,fp->end);
syncfs(fp->fd);//把内核数据刷新
fp->end = 0;
}
}
void myfclose(MyFILE* fp)
{
myfflush(fp);
close(fp->fd);
free(fp);
}
MyFILE *fp1 = (MyFILE*)calloc(1,sizeof(MyFILE));
fp1->fd = 1;
myfputs("hello\n world1",fp1);//先打印出hello
sleep(2);
myfputs("hello\n world2",fp1);//过2秒,打印出world1 hello
sleep(2);
myfclose(fp1);//再过2秒,打印world2
缓冲区的刷新策略,是在c标准库中的代码逻辑实现的
stdout和stderr
cout << "hello cout 1 " << endl;//stdout -> 1
cerr << "hello cerr 2" << endl;//stderr -> 2
const char* str1 = "hello 1\n";
write(1,str1,strlen(str1));
const char* str2 = "hello 2\n";
write(2,str2,strlen(str2));
文件描述符 1 和 2 都指向显示器文件,但是是不同的显示器文件。
重定向只会改变1号文件描述符,把标准输出的内容重定向到其他文件,追加也一样
./myproc 2>err.txt
把本来应该显示到2号文件描述符的内容,显示到err.txt中
把本来应该显示到2号文件描述符的内容,写到文件描述符为1指向的文件中
机械硬盘基本认识
内存 —— 掉电易失存储介质
机械硬盘 —— 永久性存储介质,断电后也不会丢失数据
机械硬盘是一个外设,在冯诺依曼体系中承担输入输出设备的角色,也是唯一的机械设备(慢)
机械硬盘的物理结构
机械硬盘包括磁盘盘片、磁头、伺服系统(硬件电路)、音圈马达.....
3D NAND技术发展迅速,SSD取代HDD硬盘明年可待-CFM闪存市场 ()
机械硬盘运转的基本过程
通电后,盘片在主轴马达的带动下进行快速旋转.
盘片转的同时,磁头进行左右摇摆(线性马达控制)来寻址
有一摞盘片,每一个面都有一个磁头
盘面上存储数据,计算机只认识二进制,本质存二进制
内存可以用有电和没电区分0/1,磁铁是两态的 -> 有南极和北极
有无数的小磁铁颗粒形成盘面.
向磁盘写入本质就是:改变磁盘上的南极北极
磁头来回在读写磁盘时,磁头上是一些电子信号,可以在磁盘的特定位置,产生放电行为,改变磁盘某些区域的正负性,从而向磁盘写入二进制。
笔记本最好不要开机状态来回搬运,因为磁盘盘片在高速旋转,磁头悬浮在盘片之上读取/写入,磁头上下震动,磕到盘片,容易丢失数据
机械硬盘存储规则
磁盘盘片有存储数据的规则,分门别类,方便快速找到某个区域
(1)盘面由一系列同心圆构成,数据并不是在磁盘的任意位置做写入的,
只能写在这些同心圆之上,这些同心圆叫磁道
(2)磁道一圈容量太大,可能只用磁道的一部分,所以以圆心为起点,将磁盘划分成多个块
一圈叫做磁道,一小块叫扇区
(3) 因为磁盘有一摞盘片,半径相同的多个磁道 -> 柱面(与磁道等价)
(4) 扇区是磁盘存储数据的基本单位!!!一般是512字节,所有的扇区都是512byte,它是通过密度来实现的,外部的密度低,内部的密度高
在物理上,怎么把数据写到扇区里?
先确定在哪一个磁道 —— 也就是确定同心圆
然后确定在哪一个磁头 —— 也就是确定要写到哪一个盘面
最后就能确定在哪一个扇区
CHS寻址:
C:Cylinder同心圆
H:Head磁头
S:Sector扇区
有了CHS,就能找到任意一个扇区,那么所有的扇区都能找到了
机械硬盘的逻辑结构
磁盘可以抽象成一个数组
磁盘访问的基本单位是扇区(512byte),每一个元素大小是512byte
要访问某一个扇区,只要知道该扇区对应的数组下标,在os看来就是在访问数组的一个元素 —— LBA(Logical bload address)
例如:
os访问磁盘上的某个扇区,用的是LBA。要通过LBA转换成CHS寻址,才能访问具体的扇区
抽象过程
将数据存储到磁盘 -> 将数据存储到该数组
找到磁盘特定扇区的位置 -> 找到数组特定的位置
对磁盘的管理 -> 对数组的管理
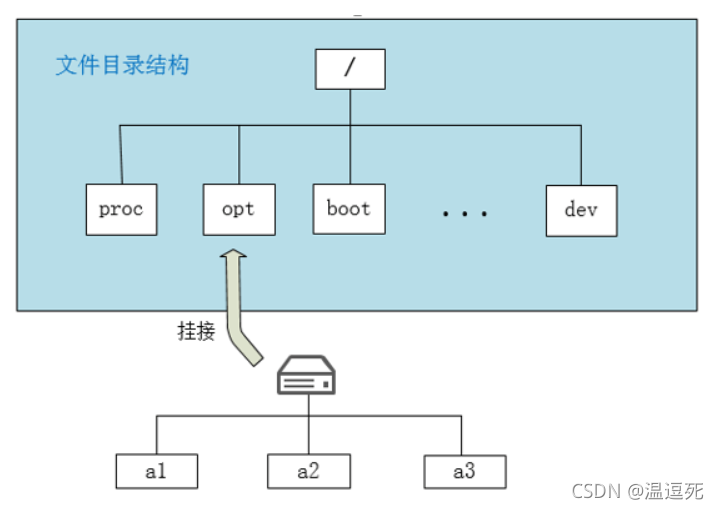
空间太大,不好管理 —— 分区
对磁盘的管理->对一个小分区的管理
但是一个分区仍然很大,继续对分区做拆分!!!
例如:将c盘拆分成多个块组
boot block
每个分区前面都有一个boot block —— 启动块,用于开机时,加载操作系统
计算机开机时,开机程序、对应开机的一些属性信息,是在每个分区的开始,都存在一份
只要一份就够了,但每个分区都有,是为了备份
有时候计算机启动不了,windows会蓝屏并说正在修复/恢复,此时可能是某个分区的boot block出问题,要把其他分区的boot block写到这个分区的boot block
Superblock
提供了整个分区的概览,是整个分区的属性集。例如:在当前的分区,有多少个块组,哪些块组满了,哪些块组没满,总共有多少个数据块可以被写,有哪些数据块已经被占
因为在物理结构上,磁盘的磁头,可能会和盘片有碰撞,导致物理上数据出现丢失
盘片被刮花,此时分区的使用情况可能会乱。所以要给整个分区的属性集做备份,块组里通常都会备份Superblock
Data blocks
Data blocks是多个4KB大小的集合
虽然磁盘的基本单位是扇区512byte,但是linux的文件系统模块和磁盘进行IO的基本单位是4KB!!!也就是8*512byte
哪怕向磁盘写1byte的数据,读取1byte数据,也必须一次写入/读取4KB大小的数据
所以4KB一般也称为block大小,磁盘也被叫做块设备
inode Table
文件 = 内容 + 属性
linux在存储时,将内容和属性是分开存储的.
Data blocks里保存的是文件的内容,而inode就是特定文件的属性
inode是一个大小为128byte的空间,保存对应文件的属性
每一个inode里,都要有一个inode编号
一般而言,一个文件,一个inode,一个inode编号
inode Table:该块组内,所有文件的inode空间的集合,就是多个128byte空间的集合
将来创建一个文件,首先在inode table里,申请128byte的大小,把文件属性写进去,
内容在DataBlocks里申请n个数据块,把内容写进去
Block Bitmap
假设有1万个DataBlock,怎么知道哪些dataBlock已经被占用了,哪些没有被占用呢?
Block Bitmap是标识Data blocks使用情况的位图
假设data blocks里有10000+个block,那么block Bitmap就有10000+个比特位,和特定的blocks一一对应
比特位为1代表block被占用;比特位为0代表没有被占用.
inode Bitmap
inode Bitmap是标识inode Table使用情况的位图
假设inde Table有10000+个inode节点,inode Bitmap就有10000+个比特位,比特位和特定的inode一一对应
其中比特位为1,代表该inode被占用,否则代表可用.
Group Descriptor Table
代表这个块组的使用情况/属性信息
例如:这个块组多大,有多少个inode,已经占用了多少个,还剩多少,还有多少个block等信息
通过inode找到文件内容
一个文件有多个block
(1) 哪些block属于同一个文件?分割分分割(2) 只要通过文件对应的inode编号,就能找到文件的inode属性集合
可是,文件的内容如何找到?
struct node{
//文件大小、inode编号等
int blocks[15];//和他同一个块组的块的编号
}
如果这个文件特别大,要使用非常多的块
data blocks中,不是所有的数据块,只能存文件数据,也能存其他块的块号
例如:block[12] block[13] block[14],存的是其他块号
用内容块去索引文件的块号
格式化
将磁盘的某个分区分隔成上面的内容,并且写入相关的管理数据,整个分区就被写入了文件系统信息,就是格式化.
目录的dataBlocks
目录也是文件,它的dataBlocks里存的是 文件名和inode编号的映射关系
在目录里创建文件/删除文件必须要有w权限
因为目录也是文件,数据块放的是文件名和inode编号的映射关系
必须要有写权限,才能把文件名和inode的映射关系写入或删除
显示目录里的文件名和属性要有r权限
文件名只能从目录的datablock里读取,
同时要拿到文件更多属性,要用inode编号找到inode,才能把文件的属性显示出来
创建文件,系统做了什么?
touch test.txt 文件大小是空的
1 根据文件系统,找到文件目录所在的分区,确定保存新文件的块组
2 遍历inode bitmap,找到第一个为0的比特位,把0置1,同时也拿到对应下标,分配inode编号
3 在inode Table中,根据之前遍历位图的下标,把文件的属性写进去,例如:inode编号、文件权限等,另外因为是空文件,把inode里的block[15]全部清0,
4 返回inode编号,再将用户的文件名和系统返回的inode编号建立映射关系,写到目录的数据块中
删除文件,系统做了什么?
1 找到目录对应的Data blocks,以文件名作为key值,找到inode编号
2 找到文件的inode,将inode bitmap特定的比特位,由1置0
3 将该文件对应的内容块在blockBitmap中由1置0
4 在目录中将文件名和inode编号的映射关系去掉
查看文件内容,系统做了什么?
1 找到目录对应的data Blocks,根据文件名找到要查看文件的inode编号
2 通过inode编号找到文件inode
3 在文件inode的映射数组int block[]里,找到文件内容的数据块所在下标位置
4 将文件的data blocks里的数据块返回给用户
磁盘还有空间,创建文件失败
inode固定,datablock是固定的
1 inode没了,数据块还有
2 数据块没了,inode还有
软硬链接软链接
类似于windows的快捷方式,有独立的inode
ln -s 目标文件 软链接文件
软链接的文件内容,是指向文件对应的路径
硬链接
和目标文件共用inode
ln 目标文件 硬链接文件
创建硬链接,就不是真正的创建新文件
本质是在指定目录下,建立了文件名 和 指定inode的映射关系 —— 仅此而已
文件的属性里有一个硬链接数,一个inode编号可能和多个文件名相关联,只有把这些文件名全部删除,才能把对应的inode删除
这个硬链接数,是一个引用计数,标识该inode与多少个文件关联
当我们删除文件时,不是将文件的inode直接删除,而是先将引用计数--
当引用计数= 0时,该文件才真正删除
创建一个普通文件,引用计数是1
创建一个目录,引用计数是2
我们进入到dir目录中,隐藏文件 . 就是dir的硬链接



