- 作者:老汪软件技巧
- 发表时间:2024-09-29 21:01
- 浏览量:
前言
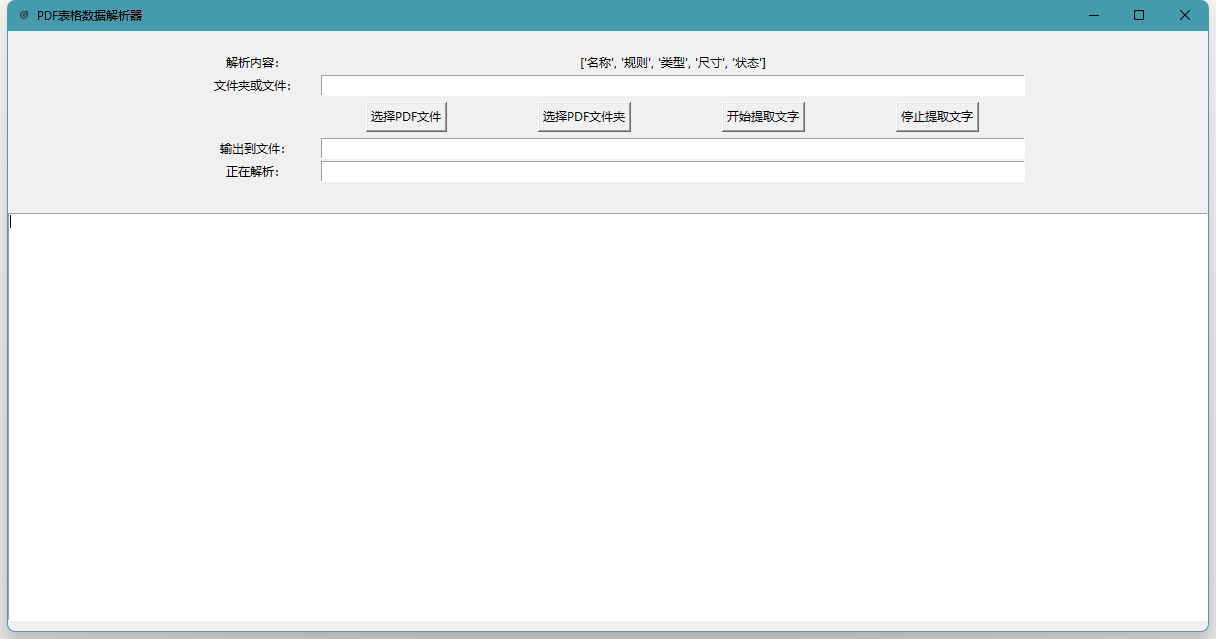
目标:PDF文档表格中的内容基本相同,需要批量提取PDF表格中的文字内容,导出到CSV文件中。开发语言:python
经过大致尝试,以下几种PDF文字提取工具提取效果:
11,400~2000,0.3,0.8,,名称,,,编号,,,,,,,,,,,,,,
- pdfplumber:提取结果为矩阵(二维数组),即tables->table->row->cell,较为理想
最终采用:pdfplumber
外部依赖标准库依赖关键代码递归读取文件夹中的所有PDF文件
def read_dir2(parser: PdfParser, path: str):
'''os.walk() 递归遍历文件夹'''
global START
if os.path.isdir(path):
for root, dirs, files in os.walk(path):
for f in files:
if START == False:
return
if f.lower().endswith('.pdf'):
sub_path = os.path.join(root, f)
parse_file(parser, sub_path)
elif path.lower().endswith('.pdf'):
parse_file(parser, path)
START = False
msgbox.showinfo('提示', '解析完成')
提取PDF所有文字

def readpdf(self, pdf_path):
with pdfplumber.open(pdf_path) as pdf:
first_page = pdf.pages[0]
tables = first_page.extract_tables()
return tables
根据设定标题提取对应的文字内容
注意:尽量将所有表格内的标题设置完,以免误将标题当成提取的文字内容。
def extract_text(self, tables = []):
row_data = dict()
for table in tables:
for row in table:
for cell in row:
if cell is None:
continue
key = cell.strip().replace(' ', '')
if key in self.titles:
if not row_data.get(key):
# 可能为:重 量, None, 7.89KG
if row.index(cell) +1 < len(row):
value = row[row.index(cell) + 1]
# 若为空,再尝试取第三个单元格(当然这里可尝试更多后续值,只要不是标题)
if value is None and row.index(cell) + 2 < len(row):
value = row[row.index(cell) + 2]
# 若不为空,则排除key值的情况
if value is not None :
value = value.replace(' ', '')
if value in self.titles:
continue
else:
row_data[key] = value.strip()
# print(row_data)
# print(row_data)
return row_data
exe打包
采用pyinstaller.
pip install pyinstaller
pyinstaller -i favicon.ico -F -w win.py
附:源代码
/opensource1…