
- 作者:老汪软件技巧
- 发表时间:2024-09-26 00:01
- 浏览量:
首先给大家介绍一个很好用的学习地址:/columns
在之前的学习中,我们学习了直线线性回归与多项式回归,我们今天的主题则是逻辑回归,我记得在前面有讲解过这两个回归的区别,那么今天我们主要看下逻辑回归有哪些特征需要我们识别的。
逻辑回归
逻辑回归主要用于解决二元分类问题,帮助我们预测某个事件是否会发生,例如判断某种糖果是否为巧克力、某种疾病是否具有传染性,或者某位顾客是否会选择特定的产品,使我们能够将复杂的数据转化为简单的“是”或“否”的结果,适用于许多实际场景。这种通常是逻辑回归解决的问题。
与线性回归不同,逻辑回归专注于预测二元分类结果,而线性回归则旨在预测连续值。例如,在线性回归中,我们可以根据南瓜的起源、收获时间以及其他相关特征来预测其价格可能上涨的幅度。然而,这个预测并不是绝对确定的,因为它依赖于历史数据的趋势和模式。通过分析过往的价格变动及其影响因素,线性回归能够提供一个合理的估计值
其他分类
当然,除了二元分类问题,逻辑回归还可以扩展到多元分类问题。在多元分类中,目标变量可以有多个可能的固定答案,而每个答案都是明确的、可识别的正确选项。
除了多元分类之外,还有一种特别的分类问题称为有序分类问题。在有序分类中,我们不仅关注类别的存在与否,还需要对结果进行逻辑上的排序,这在某些情况下非常有用。
例如,假设我们想根据南瓜的大小将其分类为不同的等级,如“迷你”(mini)、“小”(sm)、“中等”(med)、“大”(lg)、“超大”(xl)和“特超大”(xxl)。在这种情况下,这些类别之间存在明确的顺序关系。
这里单独说一下顺序逻辑回归,它是一种广义线性模型,它适用于因变量是有序分类的情况。简单来说就是:设定多个阈值 (T1,T2,T......,Tk−1)( T_1, T_2, T_......, T_{k-1} )(T1,T2,T......,Tk−1),将连续变量 Y∗Y^*Y∗划分为 k个类别。假设 Y 有 k个类别,那么有序逻辑回归的模型可以表示为:
还不懂的话,可以举个例子:例如,一位野外生物学家想研究蝾螈的生存时间,而且希望确定生存时间是否与区域和水中毒性水平相关。该生物学家将生存时间分为三个类别:小于 10 天、11 到 30 天和 30 天以上。由于响应是顺序变量,因此该生物学家使用顺序逻辑回归。
什么是因变量和自变量
再简单说一下,怕有人不明白(其实我也忘记了),因变量和自变量是统计学和回归分析中的两个基本概念,常用于建立模型以理解变量之间的关系。
仍然是线性的
为什么说逻辑回归仍然是线性的呢?主要是因为逻辑回归实际上可以视为线性回归的一种扩展。尽管它的主要应用是进行类别预测,但其基础模型仍然依赖于线性关系。但是如果线性相关性更好的话,仍然能提高模型的效果。
如果自变量与因变量之间存在强烈的线性关系,模型就能够更有效地捕捉这种关系,从而显著提高预测的准确性。当线性关系十分明确时,模型在拟合数据时能够更精准地反映变量之间的联系,从而减少预测误差。
当自变量与因变量之间存在明显的线性关系时,模型能够更清晰地划分类别边界。以二维空间为例,如果不同类别的数据点分布在一条直线的两侧,线性模型便能够更准确地识别并确定这条分隔线。
变量不必相关
线性回归通常要求自变量与因变量之间存在一定程度的线性关系,这是其有效性的基础。当这种关系较强时,模型能够更准确地预测因变量的值。此外,线性回归对自变量之间的相关性也非常敏感,特别是在面对多个相关自变量的情况下,可能会导致多重共线性问题的出现,从而影响模型的稳定性和解释能力。我们之前讲解的时候是有一张图的,大家可以去看一下。
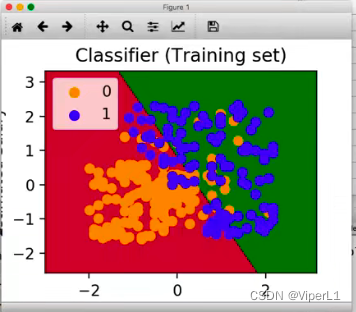
逻辑回归模型则表现出更大的灵活性,它允许自变量与因变量之间的关系不必是严格的线性关系。这意味着,自变量可以在不必具有强相关性的情况下,依然影响因变量的分类结果。这种灵活性使得逻辑回归能够适应多种不同的数据分布和类别边界,捕捉到更复杂的模式和趋势。比如下面这种图:
开始练习
我们还使用之前的南瓜数据集进行模型训练。为了确保数据的质量和可靠性,首先需要对数据集进行适当的清理。具体而言,我们会删除所有空值,以避免缺失数据对模型训练造成的不利影响。
此外,我们将仅选择与我们的分析目标相关的一些特定列,以简化数据集并提高模型的效率。
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
pumpkins.head()
new_columns = ['Color','Origin','Item Size','Variety','City Name','Package']
new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
#删除空值
new_pumpkins.dropna(inplace=True)
#字符串类型的变量转换为数值型变量
new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)
new_pumpkins.info
接下来,让我们展示打印出来的数据,这样大家就可以清晰地了解该数据集的具体内容和结构。
2 1 3 4 3 3 0
3 1 3 4 17 3 0
4 1 3 4 5 2 0
5 1 3 4 5 2 0
6 1 4 4 5 3 0
... ... ... ... ... ... ...
1694 12 3 5 4 6 1
1695 12 3 5 4 6 1
1696 12 3 5 4 6 1
1697 12 3 5 4 6 1
1698 12 3 5 4 6 1
[991 rows x 6 columns]>
可视化
正如我们在学习线性回归时所做的那样,我们通过热力图成功识别出了所有变量之间的相关性,并找到了相关性最高的两个字段。对于逻辑回归而言,我们同样需要借助一些工具和方法,而不是手动逐一检查每个值。今天,我们将重点学习并列网格这一技术。
Seaborn 提供了一系列巧妙而强大的方法来可视化数据,使得数据分析变得更加直观和易于理解。例如,使用并列网格,我们可以清晰地比较每个点的数据分布。
import seaborn as sns
g = sns.PairGrid(new_pumpkins)
g.map(sns.scatterplot)
PairGrid:这是 Seaborn 提供的一个工具,用于创建变量之间成对的散点图矩阵。
map:这个方法用于将一个绘图函数应用到 PairGrid 中的每一对变量上。
那么最后呈现的结果就是这样的:
这张图片你能看出很多东西,就比如那两个最特别的跟大家说一下:
自己对自己的时候是一条直线:因为每个数据点的值与其自身完全相等。也就是说,对于任意一个变量 X,它与自己的关系是完全线性的,形成一个斜率为 1 的对角线。
在散点图中,Color 变量对其他变量(如 Origin, Item Size, Variety, City Name, Package)显示出两排散点:这是因为color是有限的分类值、一个分类变量(如“红色”、“蓝色”),每个颜色对应的数据点在散点图中形成不同的组。这种情况下,不同颜色的值可能在其他变量上表现出明显的差异。
使用小提琴图
从上述分析中,我们可以得出结论,color 变量是一个二元类别,具体而言,它可以分为“橙色”或“非橙色”。这种类型的变量被称为“分类数据”,因此需要采用更专业和有效的方法来进行可视化。
此外,还有许多其他技术和工具可以用来展示该类别与其他变量之间的关系,例如箱线图、条形图和小提琴图等。
sns.catplot(x="Color", y="Item Size",kind="violin", data=new_pumpkins)
没了解过小提琴图的,我来讲解一下,下面是一张标准的小提琴图:
小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。
小提琴图可以是一种单次显示多个数据分布的有效且有吸引力的方式,但请记住,估计过程受样本大小的影响,相对较小样本的小提琴可能看起来非常平滑,这种平滑具有误导性。如果还不懂的话,我们可以拿身高举例。来看下比如南方、北方人的身高分布是咋样的(数据仅学习为主)
一眼是不是就可以看出来南方人普遍身高了,而北方的很平滑基本看不出什么,所以只能依靠其他手段分析了,小提琴就不能用来分析了。
好的,到此结束,现在我们已经了解了颜色的二元类别与更大的尺寸组之间的关系,让我们探索逻辑回归来确定给定南瓜的可能颜色。
数学知识点
还记得我们当时在学习线性规划时那个最小二乘法吗?来计算最佳的直接来让所有数据散点达到直线距离最小。在逻辑回归同样也有一个数学推理算法叫做Sigmoid 函数看起来像“S”形。它接受一个值并将其映射到0和1之间的某个位置。它的曲线也称为“逻辑曲线”。它的公式如下所示:
他的图像是这样的:
其中 sigmoid 的中点位于 x 的 0 点,L 是曲线的最大值,k 是曲线的陡度。如果函数的结果大于 0.5,则所讨论的标签将被赋予二进制选择的类“1”。否则,它将被分类为“0”。
当然,现在可用的工具和手段非常丰富,我们完全不必亲自进行复杂的计算,因为各种框架和库已经为我们封装好了这些功能。然而,理解背后的原理依然至关重要。
建立你的模型
和线性回归一样,使用 Scikit-learn 来构建模型来查找这些二元分类,首先第一步永远是从整体数据中分割出来一些测试集和训练集。
from sklearn.model_selection import train_test_split
Selected_features = ['Origin','Item Size','Variety','City Name','Package']
X = new_pumpkins[Selected_features]
y = new_pumpkins['Color']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
接着就是使用训练集数据训练我们的模型了
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
print('Predicted labels: ', predictions)
print('Accuracy: ', accuracy_score(y_test, predictions))
我来解释一下新出现的方法classification_report。
classification_report是 Scikit-learn 中用于评估分类模型性能的一个函数。它提供了一些关键指标,帮助你理解模型在测试集上的表现,你可以看到传了两个参数,一个是实际结果的y_test,另一个是我们训练模型根据测试集推测出来的测试结果。拿来作比较。显示结果如下:
precision recall f1-score support
0 0.83 0.98 0.90 166
1 0.00 0.00 0.00 33
accuracy 0.81 199
macro avg 0.42 0.49 0.45 199
weighted avg 0.69 0.81 0.75 199
当然了有很多指标展示,我们来慢慢看下:
Precision(精确率): 哪些标签标记得很好,举个例子:模型标记了 10 张照片为猫,其中 7 张是真正的猫,3 张是狗。精确率 = 真正的猫 / (真正的猫 + 误报的狗) = 7 / (7 + 3) = 0.7(70%)
Recall(召回率): 实际为正类的样本中,预测为正类的比例。在举例子:继续用检测猫的例子:你总共有 15 张真实的猫照片,模型只找到了 7 张。召回率 = 真正的猫 / (真正的猫 + 漏报的猫) = 7 / (7 + 8) = 7 / 15 ≈ 0.47(47%)
F1 Score: 精确率和召回率的调和平均,综合考虑了精确率和召回率。最好为1,最差为0
Support: 每个类的真实样本数量。
Accuracy(准确率): 正确预测的样本占总样本的比例。不要和精确率弄混。举个例子:假设你有 100 张照片,模型正确标记了 90 张(包括猫和狗)。准确率 = 90 / 100 = 0.9(90%),为什么包括猫和狗?因为猫和狗是为了说明分类模型在处理多类问题时的表现。
虽然我们可以通过各种指标得分去看下理解模型,但是通过使用混淆矩阵可以更容易地理解你的模型,帮助我们了解模型的性能。
混淆矩阵
“混淆矩阵”(或“误差矩阵”)是一个表格,用于表示模型的真假阳性和真假阴性,从而衡量预测的准确性。
在一个二分类问题中,混淆矩阵通常是这样的:
预测正类 (Positive)预测负类 (Negative)
实际正类 (Positive)
True Positive (TP)
False Negative (FN)
实际负类 (Negative)
False Positive (FP)
True Negative (TN)
看下代码结果:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, predictions)
array([[162, 4],[ 33, 0]])
举个例子,假设我们的模型被要求对两个二元类别之间的项目进行分类,即类别“南瓜”和类别“非南瓜”。
只要我们的模型的真阳性和真阴性,这意味着模型性能更好。所以如果你想要减少假阳性,请注意关注下召回率指标。
ROC曲线
ROC曲线(接收器操作特征曲线)用于评估二分类模型的性能,根据图示我们可以快速的了解Y 轴上的真阳性率和 X 轴上的假阳性率,我们先看下代码结果吧。
from sklearn.metrics import roc_curve, roc_auc_score
import seaborn as sns
y_scores = model.predict_proba(X_test)
# calculate ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
sns.lineplot(x=[0, 1], y=[0, 1])
sns.lineplot(x=fpr, y=tpr)
理想曲线:理想情况下,曲线应该尽量靠近左上角,这表明模型在低假阳性率下能保持高真正率。
随机猜测线:对角线(从(0,0)到(1,1))代表随机猜测。如果模型的ROC曲线与此线重合,说明模型没有区分能力。
曲线下面积(AUC)AUC值,ROC曲线下的面积,值在0到1之间:
我们计算一下:
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
0.6976998904709749
通过分析ROC曲线和AUC值,你可以更好地理解模型的分类性能,尤其是在面对不同的预测阈值时。
为什么借助这么多可视化工具?
其实每一个工具所反馈的作用都不一样,混淆矩阵直观展示预测结果,分类报告提供全面性能指标,ROC曲线帮助选择最佳阈值和评估整体性能。目的就是更好的去理解模型。然后去改进模型。
当然了,我们本次回归只查看模型现状,并没有根据结果进行优化,那是下面要讲的了。这里先不说了。
总结
在学习了逻辑回归的基本概念和应用后,我们可以看到,这种方法不仅能够处理二元分类问题,还能扩展到多元分类和有序分类的场景。逻辑回归的灵活性使得我们能够在不同的情况下找到合适的解决方案,不论是简单的“是”或“否”判断,还是更复杂的多级分类任务。
值得注意的是,逻辑回归仍然基于线性关系,但与传统的线性回归相比,它的目标和应用场景显著不同。这种方法通过概率模型,利用Sigmoid函数将连续变量映射到0到1之间,为我们提供了对结果的直观理解。
此外,在数据处理和可视化过程中,我们运用了多种工具,如并列网格、小提琴图等,这些工具不仅帮助我们分析数据之间的关系,也增强了数据的直观性和可理解性。通过这些可视化手段,我们能够清晰地识别出变量之间的联系和分类的边界。
在实践环节中,我们对数据进行了清洗和特征选择,并使用Scikit-learn构建了逻辑回归模型。通过混淆矩阵和ROC曲线等方法评估模型性能,使得我们能够更深入地理解模型的准确性和预测能力。
在以后的分类课程中,我们将一起学习如何迭代以提高模型的分数。但是现在,完结撒花!我们已经完成了这些回归课程!
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。



