
- 作者:老汪软件技巧
- 发表时间:2024-09-16 11:02
- 浏览量:178
【哈希图详解】结合哈希表与链表的高效数据结构及优化实践
在计算机科学中,哈希图(HashMap with LinkedList)是一种结合了哈希表和链表的数据结构。这种数据结构的设计目的是为了既能提供快速的查找、插入和删除操作,又能保持数据的顺序性。本文将深入探讨哈希图的结构、实现以及其在实际应用中的优势与劣势。
1. 哈希表与链表的简介1.1 哈希表
哈希表是一种通过哈希函数将键映射到特定值的快速查找数据结构。哈希表的时间复杂度通常为 O(1),因为通过哈希函数可以在常数时间内定位到元素的存储位置。
然而,哈希表并没有顺序的概念。元素的存储顺序依赖于哈希函数的计算结果,这意味着哈希表无法保证数据按照插入顺序存储或迭代。
1.2 链表
链表是一种线性的数据结构,由节点组成,每个节点包含数据和指向下一个节点的指针。链表有序存储数据,通常用于实现队列或栈等结构,或者作为更复杂数据结构的一部分。
链表的优势在于数据插入和删除操作非常高效,特别是在中间位置。但其查找操作的时间复杂度为 O(n),不适合高效查找。
2. 哈希图:两者结合的产物
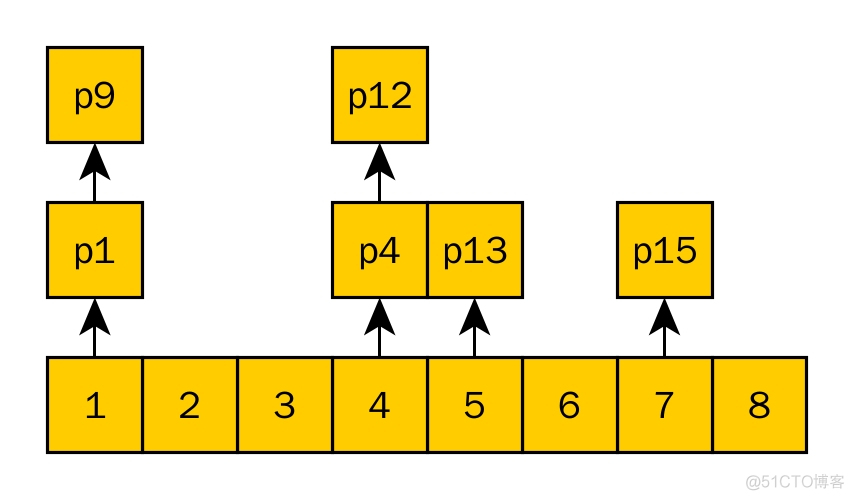
哈希图结合了哈希表的高效查找性能和链表的顺序性。在哈希图中,每个哈希桶不仅存储键值对,还维护了一个链表,用于保存插入顺序。这样,哈希图可以同时支持快速查找和顺序访问。
2.1 哈希图的基本结构
哈希图的实现通常包括以下几部分:
哈希桶数组:用于存储哈希函数计算后的值,这些值映射到相应的链表。链表:每个哈希桶的链表节点中存储了键值对以及指向下一个节点的指针。这样可以维护插入顺序,允许顺序访问数据。
2.2 哈希图的插入操作
哈希图的插入操作与普通哈希表类似,首先通过哈希函数计算键的哈希值,将其映射到哈希桶中。如果哈希桶中已经存在链表,则在链表末尾插入新的键值对。
伪代码实现如下:
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class HashMap:
def __init__(self, capacity=100):
self.capacity = capacity
self.buckets = [None] * capacity
def hash(self, key):
return hash(key) % self.capacity
def put(self, key, value):
index = self.hash(key)
if not self.buckets[index]:
self.buckets[index] = Node(key, value)
else:
current = self.buckets[index]
while current.next:
if current.key == key:
current.value = value # Update existing key
return
current = current.next
current.next = Node(key, value)
2.3 哈希图的查找操作
查找操作通过哈希函数计算键的哈希值,再顺序遍历链表来寻找目标键。由于链表的存在,时间复杂度可能退化为 O(n),但通常情况下查找性能接近 O(1)。
伪代码实现如下:
def get(self, key):
index = self.hash(key)
current = self.buckets[index]
while current:
if current.key == key:
return current.value
current = current.next
return None # Key not found
2.4 哈希图的删除操作
删除操作与查找类似,首先定位到哈希桶,然后遍历链表,找到需要删除的节点,将其从链表中移除即可。
伪代码实现如下:
def remove(self, key):
index = self.hash(key)
current = self.buckets[index]
prev = None
while current:
if current.key == key:
if prev:
prev.next = current.next
else:
self.buckets[index] = current.next
return
prev = current
current = current.next
3. 哈希图的优势与劣势3.1 优势3.2 劣势
4. 哈希图的应用场景
哈希图在许多实际应用中非常有用,特别是在需要同时支持快速查找和顺序访问的场景中。以下是一些典型的应用场景:
5. 哈希图的性能优化
哈希图在设计和实现上有许多可以优化的地方,以提高其性能和效率。主要的优化方向包括哈希函数的选择、负载因子控制、链表替代结构等。
5.1 哈希函数的选择
哈希函数的好坏直接影响到哈希图的性能。如果哈希函数分布不均匀,导致大量元素集中在某些哈希桶中,哈希图的性能就会退化。因此,选择一个能够均匀分布键值的哈希函数非常关键。
5.1.1 理想的哈希函数
一个理想的哈希函数应该具备以下特性:
5.2 负载因子的控制
哈希图的负载因子(load factor)指的是哈希图中元素的数量与哈希桶数量的比值。负载因子过高会导致大量哈希冲突,使得查找、插入和删除操作退化为 O(n) 的复杂度。相反,负载因子过低则意味着哈希桶的利用率低,导致空间浪费。
5.2.1 负载因子的动态调整
为了保持哈希图的高效性,通常会在插入新元素时动态调整哈希图的负载因子。当负载因子超过某个预设阈值时,哈希图会触发扩容操作,将哈希桶的数量增加,并对所有已有元素重新进行哈希计算,以确保桶的均匀分布。
伪代码如下:
def resize(self):
new_capacity = self.capacity * 2
new_buckets = [None] * new_capacity
for i in range(self.capacity):
current = self.buckets[i]
while current:
new_index = hash(current.key) % new_capacity
# Move elements to the new bucket array
if not new_buckets[new_index]:
new_buckets[new_index] = Node(current.key, current.value)
else:
temp = new_buckets[new_index]
while temp.next:
temp = temp.next
temp.next = Node(current.key, current.value)
current = current.next
self.capacity = new_capacity
self.buckets = new_buckets
5.3 链表替代结构
当哈希冲突较多时,哈希桶中的链表长度增加,会降低哈希图的性能。为了解决这一问题,可以用其他数据结构替代链表,如红黑树或跳表,以优化冲突处理。
5.3.1 红黑树
红黑树是一种自平衡的二叉搜索树,其查找、插入和删除的时间复杂度为 O(log n)。在现代的哈希图实现中(如 Java 的 HashMap),当哈希桶中的链表长度超过某个阈值时,会将链表转换为红黑树,从而提高查找和插入的效率。
伪代码说明如下:
if chain_length > threshold:
# Convert linked list to red-black tree
convert_to_red_black_tree(bucket)
这种转换的代价是引入了额外的复杂度,但在数据量较大的场景下,能够显著提高性能。
6. 哈希图在现代编程语言中的实现
在现代编程语言中,哈希图的实现通常以标准库中的数据结构形式提供,并进行了高度优化。以下是一些主流语言中哈希图的实现方式。
6.1 Java 的 HashMap
Java 中的 HashMap 是一个常用的数据结构,具备哈希图的典型特性:通过哈希表实现快速查找和插入,并通过链表或红黑树解决哈希冲突。
Java 8 引入了在冲突较多时,将链表转换为红黑树的机制,以提高查找性能。HashMap 的默认负载因子为 0.75,当哈希图的负载因子超过此值时会触发扩容操作。
6.2 Python 的 dict
Python 的 dict 实现类似于哈希图,它使用了开放寻址(open addressing)来处理哈希冲突,而不是使用链表。Python 3.6 以后,dict 保证了插入顺序的维护,这使得它在处理有序数据时更加方便。
# 示例:Python dict
hash_map = {}
hash_map['key1'] = 'value1'
hash_map['key2'] = 'value2'
# 查找操作
print(hash_map['key1']) # 输出 'value1'
6.3 C++ 的 unordered_map
在 C++ 标准库中,unordered_map 是哈希图的实现,它使用哈希表来提供快速的查找和插入操作。与 Java 类似,unordered_map 通过链表解决哈希冲突,并且同样可以动态扩容。
#include 7. 哈希图的实际应用
哈希图在多个实际应用场景中广泛使用,特别是在处理需要快速查找和顺序访问的数据时。以下是一些常见的应用场景。
7.1 缓存系统
在缓存系统中,哈希图常用于存储键值对数据,并且可以通过链表维护数据的顺序,以便实现如 LRU(最近最少使用)缓存替换策略。哈希图的高效查找特性使得它能够快速定位缓存中的数据,而链表则帮助维护数据的访问顺序。
7.2 数据库索引
在数据库中,哈希图可以用作一种索引结构,快速定位数据。哈希表可以根据键值将数据分散到不同的桶中,而链表则保证数据按插入顺序存储和访问。
7.3 图数据结构
在图的数据结构中,哈希图常用于表示图中的邻接表。每个节点作为键,邻接的节点通过链表或其他数据结构存储。这种表示方式能够快速查找某个节点的邻居,同时保持图的结构和连通性。
7.4 键值存储
许多键值存储系统,如 Redis 和 Memcached,都使用了类似哈希图的结构来存储和管理数据。哈希图提供了快速的键值查找,并且通过链表或其他顺序结构维护了数据的插入顺序。
8. 哈希图的扩展与改进
哈希图的基本结构虽然强大,但在特定场景下,进一步的扩展与改进可以提升其性能和适应性。以下是一些常见的扩展思路。
8.1 多线程并发
在多线程环境中,哈希图的并发性能可能会受到锁竞争的影响。为了解决这个问题,许多并发版本的哈希图实现,如 Java 的 ConcurrentHashMap,通过分段锁(Segmented Locking)技术提高并发性能。
8.2 持久化哈希图
在某些应用场景中,如分布式数据库或日志管理系统,持久化哈希图(Persistent HashMap)非常有用。持久化哈希图能够将数据存储到磁盘或其他存储介质中,确保数据在系统崩溃或重启后不丢失。
8.3 布隆过滤器优化
布隆过滤器(Bloom Filter)是一种高效的空间压缩数据结构,用于快速判断某个元素是否可能存在于集合中。在某些应用中,可以将布隆过滤器与哈希图结合,快速筛选不存在的元素,减少不必要的哈希图查找开销。
总结
哈希图是一种结合了哈希表和链表优势的数据结构,兼具了快速查找和顺序访问的能力。它通过哈希表提供 O(1) 的查找、插入和删除操作,同时通过链表或其他结构(如红黑树)来维护元素插入顺序,处理哈希冲突。在性能优化上,哈希图依赖于哈希函数的选择、负载因子的控制以及冲突处理策略的优化,如链表替换为红黑树或跳表。
现代编程语言,如 Java、Python 和 C++,都提供了哈希图的优化实现,且广泛应用于缓存系统、数据库索引、图数据结构和键值存储等场景。随着并发编程、持久化存储和空间优化需求的增长,哈希图也通过分段锁、持久化扩展以及布隆过滤器等技术不断改进,适应更复杂的应用环境。
通过理解哈希图的核心原理、应用场景和性能优化策略,开发者可以更加高效地解决涉及大规模数据管理和快速查询的实际问题。



