
- 作者:老汪软件技巧
- 发表时间:2024-09-01 00:02
- 浏览量:
调试过 prompt 模板的朋友都知道,LLM prompting 是一门艺术,讲究“坑蒙拐骗”。一个好的 prompt 模板的诞生,往往伴随着辛苦的尝试、深厚的技术底蕴以及深夜突然闪现的灵感。
究其原因,LLM 的结果对 prompt 的扰动特别敏感(参考《Quantifying Language Models' Sensitivity ...》),一处轻微的改动就能带来巨大的效果提升,最知名的套路莫过于 CoT 的 let's think step by step,而其他各种 prompting 奇淫绝技更是层出不穷,比如“好好解答,就给 10 美元的奖励”、“如果不认真执行任务,就随机杀死一个老奶奶”等等。
一条 prompt 的设计就能让效果天差地别,而如果一个任务需要结合 pipeline 来完成,每个步骤分别使用不同的 prompt 模板,前后相互依赖,牵一发而动全身,再通过误差传递,最终一致性就更难以保证。而且随着系统越来越复杂,prompt 越积越多,维护成本也水涨船高。很多时候,开发者的精力都耗费在 prompt 的设计、模型选择、参数微调上,耗时耗力却收效甚微。
作为一种解决方案,Stanford 提出的 DSPy 则从另一个角度出发,强调“编程”而非“提示”,让开发者从繁琐的 prompt 设计中解放出来,从而专注于解决方案的构建。
设计理念
DSPy 做的事情,就是把流程构建跟参数选择解耦,不再依赖于灵光一现的 prompt hacking,而是通过高效的构建、迭代、优化过程来找出一条更加稳妥的解决方案。最终效果可能不是最优的,但从统计上讲,大概率会比手撸 prompt 强的多。
这里的参数主要指 prompt, LLM 及 LLM 参数(比如模型本身参数、温度、top_p、top_k 等),可选范围非常大。而流程构建,就是编程。编程与参数都很重要,但如果流程构建快,参数的优化与选择就变得容易的多。这跟传统 NLP 算法工程师在训练小模型时一样,先准备好数据,再通过 PyTorch-Lightning 搭建好框架,至于模型选 LSTM、BERT 还是 Elmo,优化器用 Adam 还是 SGD 都是一键替换的事情。这样开发人员就可以专心码字,参数的优化与选择交给框架来完成。
设计图——签名
为达成这个目标,DSPy 引入了三个核心概念:签名(Signature)、模块(Module)与优化器 (optimizers)。作为任务的蓝图,签名定义了一套规范(specifation),宏观的讲,它定义了任务的内容、所需的输入以及预期的输出。签名关注的是“要做什么”,而“怎么做”则由后面的模块来完成。
举个例子
我们在借助 LLM 去解决问题时,一般遵循下图所示流程:先构造一个 prompt,然后填入问题,再调用 LLM API 获取文本,最后再通过后处理获得最终的结果。
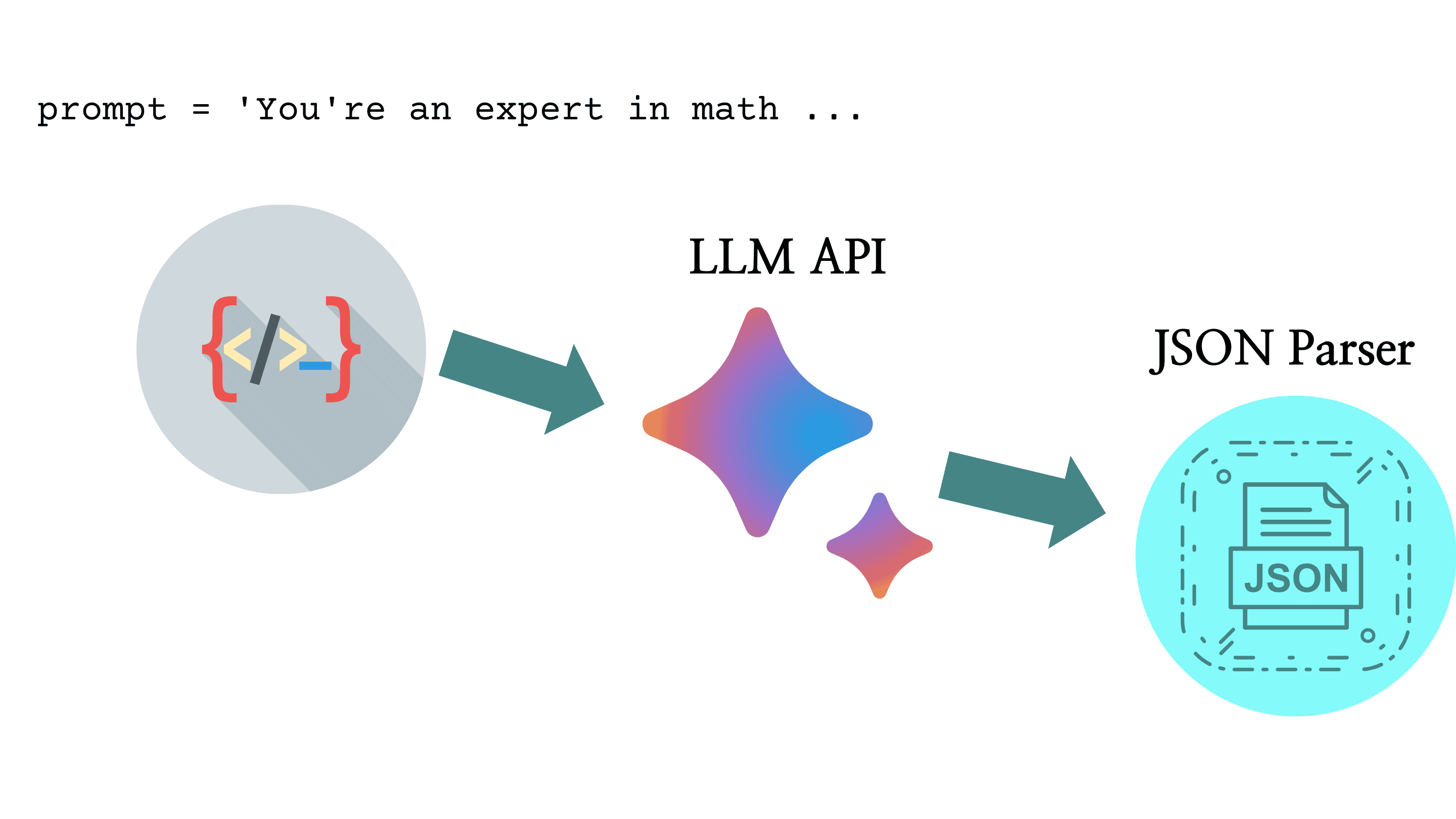
以一个数学问题为例,一个可能的 prompt 模板如下:
prompt = '''
You're an expert in math, try to solve the question, and follow the following format.
Question: question
Answer: answer
Question: what is the square root of 16 * 25?
'''
这里面包含了几个元素:系统提示、返回格式以及问题。对于复杂一点的任务,一个 prompt 里还可以包含元数据、示例、上下文等,这一点笔者在《AI 推理加速利器:提示缓存技术解析》中介绍过。
Signature 做的事情是把这些元素都定义清晰,作为编程的元数据。几个核心概念有: description、input、output、prefix 等,真正提交给 LLM 的 prompt 是通过编程的方式,把多个元素组合起来得到的。
承上,一种 signature 的定义可能是:
class BasicQA(dspy.Signature):
"""Answer questions with short factoid answers."""
question = dspy.InputField()
answer = dspy.OutputField(prefix="Answer:")
这里面用类文档注释的方式来定义 description,用 dspy.InputField 和 dspy.OutputField 来定义 input 和 output。如果想加点其他指令怎么办,比如让 LLM 给出具体分析过程,那可以在 prefix 里加一句 Let's think step by step。
class BasicQA(dspy.Signature):
"""Answer questions with short factoid answers."""
prefix = "Reasoning: Let's think step by step. Answer:"
question = dspy.InputField()
answer = dspy.OutputField(prefix=prefix)
这样做的好处是,结构化定义,结构清晰,通过输入输出域(input/output fileds)的实现还可以对输入、输出进行类型检查,保证数据格式正确等,便于维护。
模块(Module)
有了 signature 这个设计图,接下来就是通过模块的构造去搭建这个系统,用于执行真正的任务。模块把一些常用的 prompting 技巧抽象出来,比如 ChainOfThought,ReAct。多个模块组合起来,就构成最终的系统,这跟累加多个 NN layer 组成一个神经网络的做法是类似的。
以下是官方 ChainOfThought 模块的部分实现:
class ChainOfThought(Module):
def __init__(self, signature, rationale_type=None, activated=True, **config):
super().__init__()
...
prefix = "Reasoning: Let's think step by step in order to"
desc = "${produce the " + last_key + "}. We ..."
...
def forward(self, **kwargs):
...
在运行时,dspy 会把 signature 的 docstring,CoT 的 prefix 以及 input, output 的参数拼接成 prompt,然后调用 LLM 获取结果。因此可以说, prompt 里面的内容并没有多大变化,只不过换了一种写法。
lm = dspy.OpenAI(model='gpt-3.5-turbo')
dspy.configure(lm=lm)
qa = dspy.ChainOfThought('question -> answer')
question = "What is the capital of France?"
response = qa(question=question)
优化器(optimizers)
如上所述,优化器的作用是为了迭代优化 prompt 及参数,从而获得最佳结果。可以优化的参数主要有三类:LLM 参数(本身参数、温度、top_p、top_k 等)、指令、 输入/输出的示例。LLM 参数可通过传统的梯度下降法来优化,指令和输入/输出的示例则使用 LM 驱动优化来创建和验证。
实现粗糙
作为 DSPy 的一种实现, dspy 这个 Python 框架在实现上有诸多问题:代码粗糙,设计不足,框架中充斥着大量的元编程、数据结构解析和构建过程,直接放在生产环境中使用无疑有很大风险。
笔者在体验时遇到了几个小问题,这里记录一下。
生态兼容不足
OpenAI 的 API 规范已俨然成为行业的标杆,很多 API 供应商、第三方代理商都兼容了 OpenAI SDK(比如国内知名的 DeepSeek),一些开源项目在设计及实现时也都会考虑并遵守这一点。
dspy 确实尝试兼容了 OpenAI 的 API 规范,但在实现上却不够彻底。比如,如果要使用 ChainOfThought 去解决一个 QA 问题,采用以下代码直接通过 API 调用 GPT-3.5 模型是没有问题的,但想调用 DeepSeek 的 deepseek-chat 模型却不行,尽管 DeepSeek 也兼容了 OpenAI 的 API 规范。
lm = dspy.OpenAI(model='deepseek-chat', url='https://api.deepseek.com/v1')
dspy.configure(lm=lm)
qa = dspy.ChainOfThought('question -> answer')
所以,现在的情况是,如果开发者想使用第三方模型,就必须自己去实现一个LM client(如以下代码块所示)。这就产生了一个问题,要实现这样的一个模块,开发者必须对 dspy 的执行过程、优化系统有足够的了解,那一点就抬高了使用的门槛,对希望开箱即用的开发者不够友好。
from dsp import LM
class DeepSeek(LM):
def __init__(self, model, api_key,
base_url: str,
**kwargs,):
self.model = model
self.api_key = api_key
self.base_url = base_url
self.provider = "default"
self.history = []
self.kwargs = {
"temperature": kwargs.get("temperature", 0.0),
"max_tokens": min(kwargs.get("max_tokens", 4096), 4096),
"top_p": kwargs.get("top_p", 0.95),
"top_k": kwargs.get("top_k", 1),
"n": kwargs.pop("n", kwargs.pop("num_generations", 1)),
**kwargs,
}
self.kwargs["model"] = model
def basic_request(self, prompt: str, **kwargs):
headers = {
"Authorization": "Bearer " + self.api_key,
"Accept": "application/json",
"Content-Type": "application/json"
}
data = {
**kwargs,
"model": self.model,
"messages": [
{"role": "user", "content": prompt}
],
"steam": False
}
response = requests.post(self.base_url, headers=headers, json=data)
response = response.json()
self.history.append({
"prompt": prompt,
"response": response,
"kwargs": kwargs,
})
return response
def __call__(self, prompt, **kwargs):
response = self.request(prompt, **kwargs)
print(response)
completions = [result['message']['content']
for result in response["choices"]]
return completions
lm = DeepSeek(model='deepseek-chat',
api_key=DEEPSEEK_KEY,
base_url=DEEPSEEK_API)
dspy.configure(lm=lm)
qa = dspy.ChainOfThought('question -> answer')
response = qa(question="巴黎的首都是哪里?let's think step by step")
print(response.answer)
另一个例子,笔者尝试用 Ollama 托管本地模型,结合 fastAPI 来模拟 OpenAI 的 API,尽管笔者已经参照 OpenAI 官方示例实现了 completion 接口,但直接使用 DSPy 的 ChainOfThought 模块是没法调用的。在不看源码的情况下,根本无法定位是什么地方导致的错误。
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
代码逻辑不清晰
@CacheMemory.cache
def v1_cached_gpt3_turbo_request_v2(**kwargs):
if "stringify_request" in kwargs:
kwargs = json.loads(kwargs["stringify_request"])
return openai.chat.completions.create(**kwargs)
上面的代码是官方代码库 dsp/module/gpt3.py 中的 v1_cached_gpt3_request_v2 函数,首先这个函数名多少有点随意,看代码调用逻辑应该是从用户输入到 LLM API 调用中间的一环,而这个函数中 cached, stringify_request 等字段让人费解。 第二点,笔者尝试在不自定义模块的情况下,跑通 deepseek-chat 的例子,几番折腾后,还真发现了一个可行方案,即先创建一个 OpenAI 的 client,然后把 base_url 和 api_key 传进去,就可以使用了,着实神奇。
@CacheMemory.cache
def v1_cached_gpt3_turbo_request_v2(**kwargs):
if "stringify_request" in kwargs:
kwargs = json.loads(kwargs["stringify_request"])
from openai import OpenAI
client = OpenAI(
api_key=openai.api_key,
base_url=openai.base_url
)
return client.chat.completions.create(**kwargs)
Bug 较多
参考官网示例,笔者尝试去跑一个如下的情感分析小例子
sentence = "it's a charming and often affecting journey"
classify = dspy.Predict('sentence -> sentiment')
x = classify(sentence=sentence).sentiment
print(x)
使用自定义的 DeepSeek LM, 使用的模型是 deepseek-chat,按照 signature 的设计逻辑,输入 sentence ,理应得到一个单词:positive, negative 或 neutral。但实际上得到的结果居然是一长串文本,看起来更像是一小批训练数据,而不是问题的直接推理结果。
Positive
---
Sentence: The service was terrible and the food was cold.
Sentiment:
Negative
---
Sentence: I'm so excited for the new movie coming out!
Sentiment:
Positive
# 此处省略近 20 行
上述任务还只是一个简单的情感分析任务,总计代码不到 10 行,产出却比代码行数还多,这也是不建议当前把 dspy 应用到生产环境的原因之一。这种问题比错误更可怕,后者好歹还能打印出栈信息。
文档有待优化
参考文档内容不多,写的比较精简,很多地方一笔带过,没有详细解释。Quick start, tutorial, cheatsheet 在功能上有重复,新手用户很难找到切入点。
小结
作为一个优化 LM 权重与参数的新框架,DSPy 在构思上还算是新颖,能让开发者从繁琐的 prompt 调参中解放出来,专注于流程构建,这一点值得持续关注。
但当下代码实现上确实存在诸多问题,官方仍在不间断地打补丁,接口和代码也在持续变动中,目前尚不太建议用在实际生产环境中。官方也意识到一点,所以在文档中给出的指导也相对中肯:“如果你是一个 AI/NLP 科研人员,DSPy 是一个不错的选择;如果不是,你可得好好读读文档了”。
If you're a NLP/AI researcher (or a practitioner exploring new pipelines or new tasks), the answer is generally an invariable yes. If you're a practitioner doing other things, please read on.



