
- 作者:老汪软件技巧
- 发表时间:2024-08-31 07:01
- 浏览量:
享元模式的原理和实现都很简单,但是应用场景却相对狭窄,它和现在我们所熟知的缓存模式、池化模式有所联系,却又有不同。看完这篇文章后,相信你会找到这个不同之处。
一、模式原理分析
享元模式的原始定义是:摒弃了在每个对象中保存所有数据的方式,通过共享多个对象所共有的相同状态,从而让我们能在有限的内存容量中载入更多对象。
从这个定义中你可以发现,享元模式要解决的核心问题就是节约内存空间,使用的办法是找出相似对象之间的共有特征,然后复用这些特征。
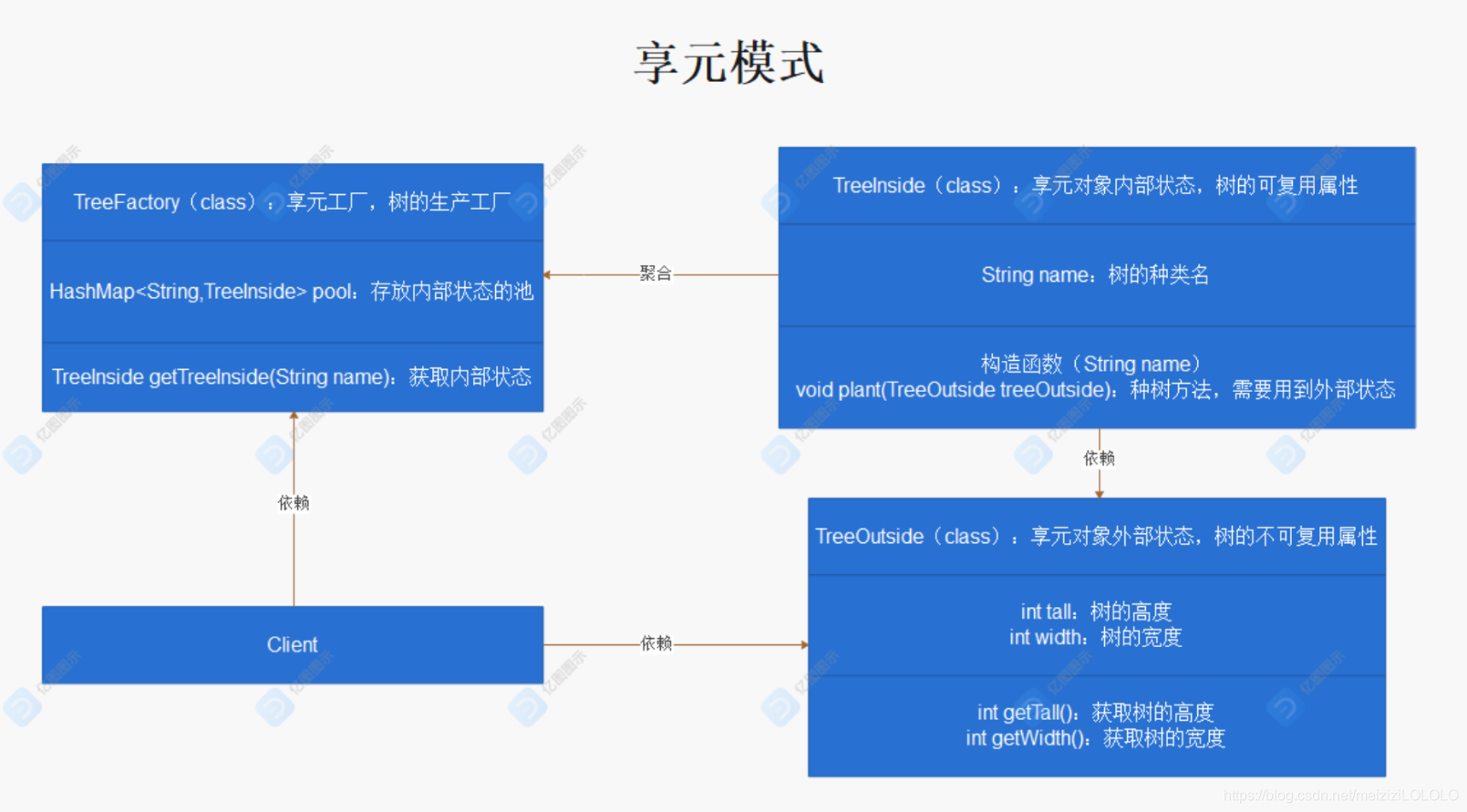
我们先来看看 UML 图是如何表示享元模式的,如下图:
从这个 UML 图中,我们能看出享元模式包含的关键角色有四个。
下面我们再来看看 UML 对应的代码实现:
//享元类
public interface Flyweight {
void operation(int state);
}
//享元工厂类
public class FlyweighFactory {
// 定义一个池容器
public Map pool = new HashMap<>();
public FlyweighFactory() {
pool.put("A", new ConcreteFlyweight("A"));//将对应的内部状态添加进去
pool.put("B", new ConcreteFlyweight("B"));
pool.put("C", new ConcreteFlyweight("C"));
}
//根据内部状态来查找值
public Flyweight getFlyweight(String key) {
if (pool.containsKey(key)) {
System.out.println("===享元池中有,直接复用,key:"+key);
return pool.get(key);
} else {
System.out.println("===享元池中没有,重新创建并复用,key:"+key);
Flyweight flyweightNew = new ConcreteFlyweight(key);
pool.put(key,flyweightNew);
return flyweightNew;
}
}
}
//共享的具体享元类
public class ConcreteFlyweight implements Flyweight {
private String uniqueKey;
public ConcreteFlyweight(String key) {
this.uniqueKey = key;
}
@Override
public void operation(int state) {
System.out.printf("=== 享元内部状态:%s,外部状态:%s%n",uniqueKey,state);
}
}
//非共享的具体享元类
public class UnsharedConcreteFlyweight implements Flyweight {
private String uniqueKey;
public UnsharedConcreteFlyweight(String key) {
this.uniqueKey = key;
}
@Override
public void operation(int state) {
System.out.println("=== 使用不共享的对象,内部状态:"+uniqueKey+",外部状态:"+state);
}
}
输出结果:
====享元池中有,直接复用,key:A
=== 享元内部状态:A,外部状态:9
====享元池中有,直接复用,key:B
=== 享元内部状态:B,外部状态:8
====享元池中没有,重新创建并复用,key:D
=== 享元内部状态:D,外部状态:7
====创建不共享的对象,key:uX
=== 使用不共享的对象,内部状态:uX,外部状态:6
这段代码实现非常简单,不过这里你可能会联想到缓存模式,比如,LRU 缓存模式。但这两者是完全不同的设计意图,它们的本质区别在于:享元模式要解决的问题是节约内存的空间大小,而缓存模式本质上是为了节省时间。
回到上面的代码分析中,我们能看出享元模式封装的变化有:
所以说,享元模式本质上是通过创建更多的可复用对象的共有特征来尽可能地减少创建重复对象的内存消耗。
三、使用场景分析
一般来讲,享元模式常用的使用场景有以下几种。
在现实中,享元模式最常使用的场景是在编辑器软件中,比如,在一个文档中多次出现相同的图片,则只需要创建一个图片对象,通过在应用程序中设置该图片出现的位置,就可以实现该图片在不同地方多次重复显示的效果。
四、为什么使用享元模式?
分析完享元模式的原理和使用场景后,我们再来说说使用享元模式的原因,主要有以下两个。
第一个,减少内存消耗,节省服务器成本。 比如,当大量商家的商品图片、固定文字(如商品介绍、商品属性)在不同的网页进行展示时,通常不需要重复创建对象,而是可以使用同一个对象,以避免重复存储而浪费内存空间。由于通过享元模式构建的对象是共享的,所以当程序在运行时不仅不用重复创建,还能减少程序与操作系统的 IO 交互次数,大大提升了读写性能。
第二个,聚合同一类的不可变对象,提高对象复用性。 比如,Java 中的 Number 对象族类(Integet、Long、Double 等)都是使用了享元模式例子,通过缓存不同范围数值来重复使用相同的数值。
五、享元模式的优缺点
通过上面的分析,我们可以得出使用享元模式主要有以下优点。
同样,享元模式也不是万能的,它也有一些缺点。
享元模式为共享对象定义了一个很好的结构范例。不过,用好享元模式的关键在于找到不可变对象,比如,常用数字、字符等。
之所以做对象共享而不是对象复制的一个很重要的原因,就在于节省对象占用的内存空间大小。缓存模式和享元模式最大的区别就是:享元模式强调的是空间效率,比如,一个很大的数据模型对象如何尽量少占用内存并提供可复用的能力;而缓存模式强调的是时间效率,比如,缓存秒杀的活动数据和库存数据等,数据可能会占用很多内存和磁盘空间,但是得保证在大促活动开始时要能及时响应用户的购买需求。也就是说,两者本质上解决的问题类型是不同的。
虽然享元模式的应用不如缓存模式多,但是对于超大型数据模式来说,它却是非常有效的优化方法之一。特别是对于现在越来越多的数据系统来说,共享变得更加重要,因为复制虽然时间效率更高,但是空间上可能完全不够。



