
- 作者:老汪软件技巧
- 发表时间:2024-08-20 11:01
- 浏览量:
最近工作中遇到一个使用nodejs实现爬虫程序的任务。需求背景是这样的:公司运营的一个老项目运营那边最近提了SEO优化的需求,但是项目本身并没有做SSR(服务端渲染),公司的要求是花费的人力成本最低,代价最小。在经过一番调研之后团队收集了几种备选方案,一番讨论之后最终选择了koa+puppeteer的方案。PS:欢迎关注作者微信公众号fever code,获取最新技术分享。
选型中的一些思考
调研的过程中团队是有收集几种技术方案供选择的,但每种技术方案都利弊兼有,适用的场景也各不相同。虽然最后只能取一种最适合我们需求的方案,但这个思考的过程我觉得还是很有价值的。
最初的爬虫版本
在确定方案之后就是开始动手码代码了,在一番哐哐哐顺畅的代码输入之后,就有了如下代码片段,使用postman测试,结果符合预期,团队大喜过望!以为轻轻松松就搞定了这个看起来并不简单的问题。上线之后没几天访问的爬虫比想象中多很多,而且puppeteer对资源的消耗也非常恐怖,再就是存在内存泄漏问题,服务器频繁报警,只能继续优化打磨这个方案。
const puppeteer = require('puppeteer')
const express = require('express')
var app = express();
app.get('*', async (req, res) => {
let url = "https://www.demo.com" + req.originalUrl; // 目标网站URL
const browser = await puppeteer.launch(); // 启动Puppeteer浏览器
const page = await browser.newPage(); // 创建一个新页面
await page.goto(url, { waitUntil: 'networkidle2' }); // 跳转到目标网站并等待页面完全加载 const html = await page.content(); // 获取页面HTML代码
await browser.close(); // 关闭浏览器
res.send(html);
});
app.listen(3000, () => {
console.log('服务已启动在3000端口...');
});
经过打磨后的爬虫程序
service.js(程序入口)
完善了日志记录功能,对每个请求和报错信息都进行了详细的记录,方便分析和排查问题。对程序被访问次数进行了累加统计。
const Koa = require("koa");
const Router = require("koa-router");
const minify = require('html-minifier').minify;
const spider = require("./spider.js");
const requestLog = require("./request-log.js");
const app = new Koa();
const router = new Router();
// 记录请求次数
let reqTimes = 0
// 正则表达式 /.*/ 用于匹配所有请求
router.get(/.*/, async (ctx) => {
reqTimes += 1
// 记录请求日志
requestLog(ctx.request, 'request.log', reqTimes)
const url = "https://www.demo.com" + ctx.originalUrl; // 目标网站URL
try {
let content = ''
const { html = '获取html内容失败', contentType } = await spider(url)
// 通过minify库压缩代码,减少搜索引擎爬虫爬取到静态资源文件的网络时延
content = minify(html, { removeComments: true, collapseWhitespace: true, minifyJS: true, minifyCSS: true });
if (ctx.request.url.indexOf(".") < 0) {
ctx.set("Content-Type", "text/html");
} else {
ctx.set("Content-Type", contentType);
}
ctx.body = content; // 将HTML代码返回给前端
} catch (error) {
const errorObject = {
message: error.message,
name: error.name,
stack: error.stack
};
// 记录错误日志
requestLog(errorObject, 'error.log')
ctx.body = '获取html内容失败';
}
})
app.use(router.routes());
app.use(router.allowedMethods());
app.listen(3000, () => {
console.log("服务已启动在3000端口...");
});
spider.js(爬虫功能实现)
每次访问从puppeteer无头浏览器实例池中取出浏览器实例列表随机访问某个浏览器,从而实现负载均衡策略,降低服务器的负担。为防止某个浏览器报错影响后续搜索引擎爬虫的正常访问,当服务累计被访问到5000次时,则自动销毁浏览器实例列表并重新创建。
const puppeteer = require('puppeteer');
const { createWSEList, resetWSEList, fetchWSEList } = require('./puppeteer-pool.js');
const requestLog = require("./request-log.js");
// 访问次数阈值
const reqLimit = 5000
// 访问次数
let reqTimes = 0
const spider = async (url) => {
// 标记请求次数+1
reqTimes += 1
// 响应头:content-type
let contentType = "";
// 请求次数等于请求阈值则清空浏览器实例
if (reqTimes >= reqLimit) {
await resetWSEList()
// 重置请求次数
reqTimes = 0
}
// 获取浏览器实例列表
let WSE_LIST = fetchWSEList()
if (WSE_LIST.length === 0) {
await createWSEList()
WSE_LIST = fetchWSEList()
}
let tmp = Math.floor(Math.random() * WSE_LIST.length);
//随机获取浏览器
let browserWSEndpoint = WSE_LIST[tmp];
//连接
const browser = await puppeteer.connect({
browserWSEndpoint
});
//打开一个标签页
const page = await browser.newPage();
// Intercept network requests.
await page.setRequestInterception(true);
page.on('request', async (request) => {
if (request.isInterceptResolutionHandled()) return;
if (
request.url().indexOf(".png") > 0 ||
request.url().indexOf(".jpg") > 0 ||
request.url().indexOf(".gif") > 0 ||
request.url().indexOf(".svg") > 0 ||
request.url().indexOf(".mp4") > 0
) {
await request.abort();
} else {
await request.continue();
}
});
page.on("response", async (response) => {
await (contentType = response.headers()["content-type"]);
});
//打开网页
try {
await page.goto(url, {
timeout: 60000, //连接超时时间,单位ms
waitUntil: 'networkidle0' //网络空闲说明已加载完毕
});
} catch (err) {
try {
await page.goto(url, {
timeout: 120000, //连接超时时间,单位ms
waitUntil: 'networkidle0' //网络空闲说明已加载完毕
});
} catch (error) {
const errorObject = {
message: error.message,
name: error.name,
stack: error.stack
};
// 记录错误日志
requestLog(errorObject, 'error.log')
// 获取当前浏览器打开的tab数
const pages = await browser.pages();
if (pages.length > 1) {
// 当前tab数大于1则关闭当前页面(一个浏览器至少要留一个页面,不然browser就关闭了,后面newPage就卡死了)
await page.close();
}
return {
html: '请求超时',
contentType: 'text/html'
};
}
}
//获取渲染好的页面源码。不建议使用await page.content();获取页面,因为在我测试中发现,页面还没有完全加载。就获取到了。页面源码不完整。也就是动态路由没有加载。vue路由也配置了history模式
const html = await page.evaluate(() => {
return document.documentElement.outerHTML
});
// 获取当前浏览器打开的tab数
const pages = await browser.pages();
if (pages.length > 1) {
// 当前tab数大于1则关闭当前页面(一个浏览器至少要留一个页面,不然browser就关闭了,后面newPage就卡死了)
await page.close();
}
return {
html: html || '获取html内容失败',
contentType
};
}
module.exports = spider;
puppeteer-pool.js(浏览器实例池)
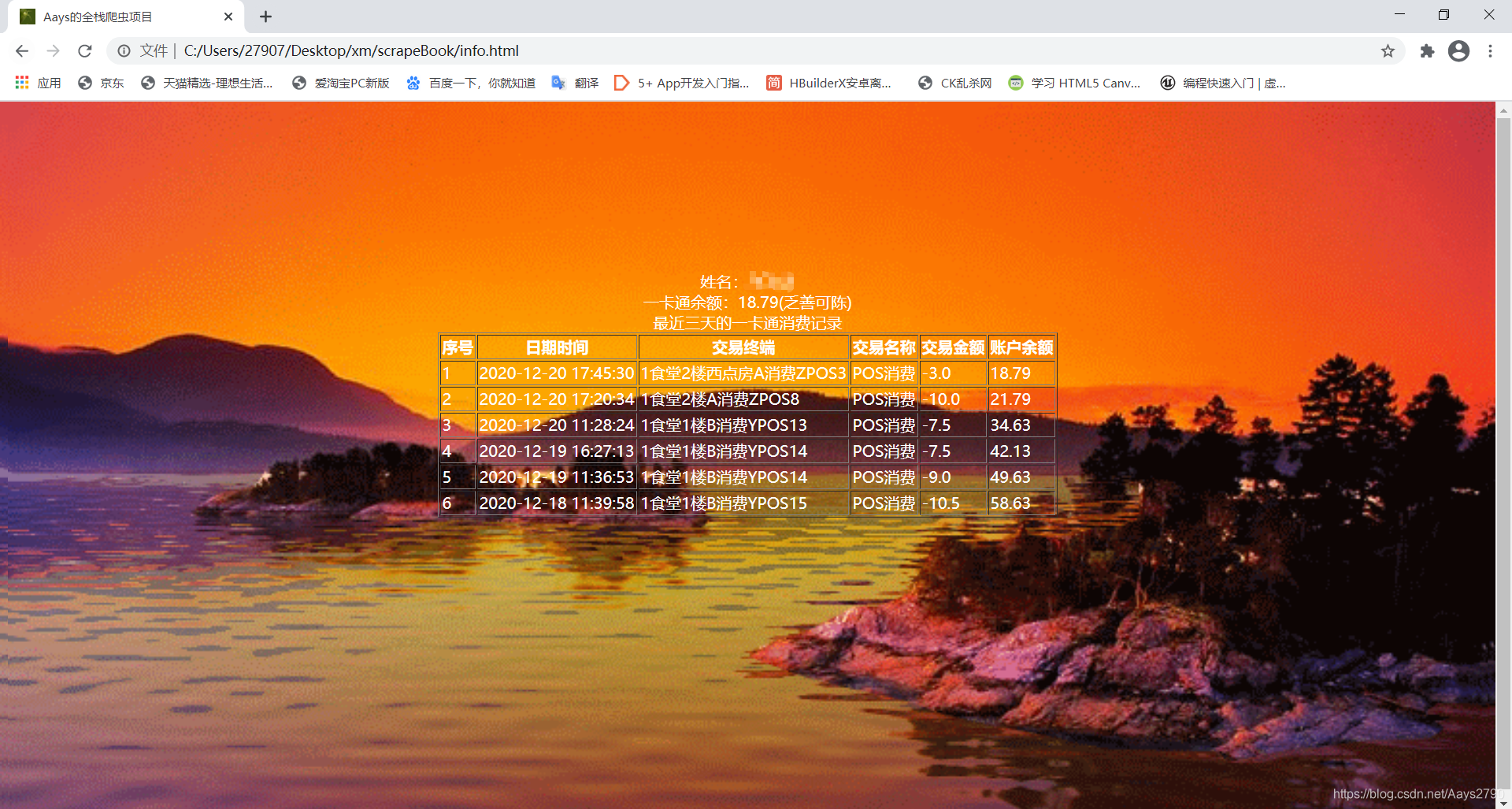
创建4个浏览器实例存在浏览器实例池中,供实现负载均衡策略时调用
const puppeteer = require("puppeteer");
let WSE_LIST = []; //存储browserWSEndpoint列表
let BROWSER_LIST = []; //存储browserWSEndpoint列表
const MAX_WSE = 4;
//负载均衡
const createWSEList = async () => {
for (let i = 0; i < MAX_WSE; i++) {
const browser = await puppeteer.launch({
headless: "shell",
//参数(浏览器性能优化策略)
args: [
'--disable-gpu',
'--disable-dev-shm-usage',
// 禁用沙箱
'--disable-setuid-sandbox',
// --no-first-run 配置建议关闭,允许创建浏览器的时候每个浏览器保留一个空页面,防止浏览器因为没有页面而关闭
// '--no-first-run',
'--no-sandbox',
'--no-zygote',
// 单线程
'--single-process'
],
//一般不需要配置这条,除非启动一直报错找不到谷歌浏览器
//executablePath:'chrome.exe在你本机上的路径,例如C:/Program Files/Google/chrome.exe'
});
let browserWSEndpoint = await browser.wsEndpoint();
BROWSER_LIST.push(browser);
WSE_LIST.push(browserWSEndpoint);
}
}
const resetWSEList = () => {
try {
BROWSER_LIST.forEach(async browser => {
await browser?.close()
})
WSE_LIST = []
BROWSER_LIST = []
} catch (error) {
WSE_LIST = []
BROWSER_LIST = []
}
}
const fetchWSEList = () => WSE_LIST
module.exports = {
createWSEList,
resetWSEList,
fetchWSEList
}
request-log.js(日志记录功能)
不用任何第三方库,自己手写实现的日志记录功能,我个人觉得简单好用
const fs = require('fs')
const path = require('path')
// 格式化时间戳
const formateDate = (date, rule = '') => {
let fmt = rule || 'yyyy-MM-dd hh:mm:ss'
// /(y+)/.test(fmt) 判断是否有多个y
if (/(y+)/.test(fmt)) {
// RegExp.$1 获取上下文,子正则表达式 /(y+)/.test(fmt)
fmt = fmt.replace(RegExp.$1, date.getFullYear())
}
const o = {
'M+': date.getMonth() + 1,
'd+': date.getDate(),
'h+': date.getHours(),
'm+': date.getMinutes(),
's+': date.getSeconds()
}
for (let k in o) {
if (new RegExp(`(${k})`).test(fmt)) {
const val = o[k] + ''
fmt = fmt.replace(RegExp.$1, RegExp.$1.length == 1 ? val : ('00' + val).substr(val.length))
}
}
return fmt
}
const writeLog = (logData, fileName, times) => {
const writeFilePath = path.join(__dirname, `logs/${fileName}`);
let content = formateDate(new Date())
if (times) {
content += `(${times})`
}
content += ':\r' + JSON.stringify(logData) + '\n';
fs.appendFileSync(writeFilePath, content);
}
module.exports = writeLog
package.json(包管理)
{
"name": "puppeteer",
"version": "1.0.0",
"main": "service.js",
"scripts": {
"dev": "nodemon service.js",
"serve": "pm2 start ecosystem.config.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"html-minifier": "^4.0.0",
"koa": "^2.15.3",
"koa-router": "^12.0.1",
"pm2": "^5.4.1",
"puppeteer": "^19.8.0"
},
"devDependencies": {
"nodemon": "^3.1.4"
}
}
ecosystem.config.cjs
pm2配置文件,使用pm2实现项目部署,不使用cjs结尾在有些window环境下启动时会报错
module.exports = {
apps: [{
name: 'puppeteer',
script: 'service.js',
log_date_format: "YYYY-MM-DD HH:mm:ss",
instances: "max", // 进程实例的数量,"max" 表示根据 CPU 核心数自动设置
exec_mode: "cluster", // 运行模式,"cluster" 表示使用集群模式
max_memory_restart: "3G", // 在内存达到指定大小时自动重启应用程序
error_file: './logs/pm2_error_file.log',
out_file: './logs/out_file.log'
}],
};
写在最后
在实践SEO的过程中puppeteer是一种偏冷门的方案,但是却也有自己的用武之地,但是目前关于puppeteer的技术方案沉淀还比较少,所以遇到问题很难找到相关的资料,得自己慢慢去摸索,而且这种方案要求对服务器相关知识有储备,对于传统前端开发人员来说是有难度的。但是在实践之后对于浏览器的底层原理会有更加深刻的认知,毕竟puppeteer就是个浏览器内核程序,当你熟悉了使用浏览器内核程序开放的API去操作浏览器行为的时候,在可视化界面鼠标一顿点不是更驾轻就熟!
项目源码
/mangoisgrea…



